1.はじめに
前回のブログでは、事前学習済みBERTをファインチューニング無しでそのまま使って、センター試験や文章生成がどれくらい出来るかやらせてみました。
今回は、事前学習済みBERTにファインチューニングを行って、文章のネガポジ判定をするタスクを解かせ、根拠を可視化してみたいと思います。
2.事前学習のおさらい
BERTの事前学習では、2つのタスクを実行します。
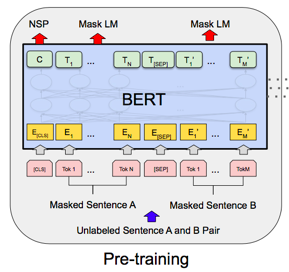
1つ目のタスクは、Masked Language Modelで、穴埋め問題を解かせることで前後の文脈を利用できるようにします。文全体の15%の単語を選び、その内80%をマスク、10%を他の単語に置き換え、10%をそのままにします。15%に抑えているのは、この後のファインチューニングでマスクは登場しないのでギャップが大きいとファインチューニングが上手く行かないためです。
2つ目のタスクは、Next Sentence Predictionで、2つの文が意味的に繋がっているかを判定するものです。
これらのタスクを学習するには、かなり計算コストがかかり、TPUを4つ使っても4日間くらい掛かるらしいですが、誰かが1回やれば後はファインチューニングで様々なタスクが解けるネットワークができるわけです。
3.ファインチューニング
ファインチューニングは、事前学習の重みを初期値として、ラベルありデータで行います。事前学習によって地頭が鍛えられているので、少ない文章データから性能の良いモデルが作成可能です。論文では、様々なタスクのファインチューニングの計算コストは、TPU1つで1時間以内で終わったということです。

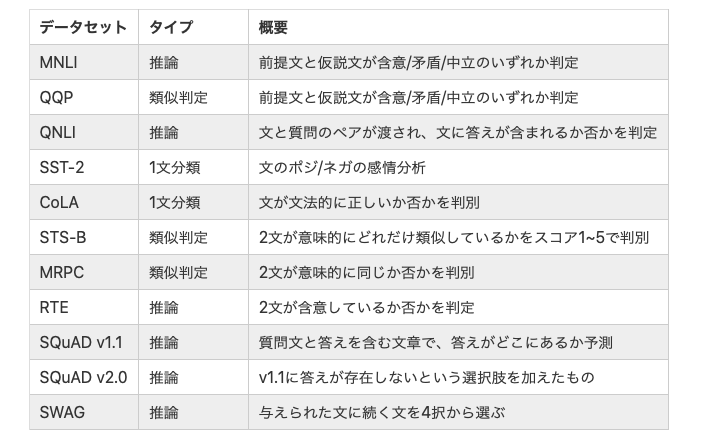
以下は、BERTがSoTAを記録した11個のNLPタスクです。
4.今回実装するモデル
BERTにはモデルサイズの異なる2つのタイプがあり、今回使うのはBaseと呼ばれる小さい方のモデルです。

BERTの出力は識別用とトークンレベル用の2つあり、今回は識別用に全結合層を接続しネガポジ判定を行います。使用するデータセットは、映画のレビュー(英文)の内容がポジティブなのかネガティブなのかをまとめたIMDb(Internet Movie Database)です。
モデルを学習させることによって、ある映画のレビューを入力したら、そのレビューがポジティブなのかネガティブなのかを判定し、レビューの単語の相互Attentionから判定の根拠にした単語を明示させるようにします。
5.モデルのコード
BERTモデルを作成し、事前学習済みの重みパラメータをセットします。
|
1 2 3 4 5 6 7 8 9 10 11 |
from bert import get_config, BertModel, set_learned_params # モデル設定のJOSNファイルをオブジェクト変数として読み込みます config = get_config(file_path="./data/bert_config.json") # BERTモデルを作成します net_bert = BertModel(config) # BERTモデルに学習済みパラメータセットします net_bert = set_learned_params( net_bert, weights_path="./data/pytorch_model.bin") |
BERTモデルにIMDbのネガ・ポジを判定するLinearをつなげた class BertForIMDbを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# BertForIMDbクラスを作成 class BertForIMDb(nn.Module): def __init__(self, net_bert): super(BertForIMDb, self).__init__() # BERTモジュール self.bert = net_bert # BERTモデル # headにポジネガ予測を追加 # 入力はBERTの出力特徴量の次元、出力はポジ・ネガの2つ self.cls = nn.Linear(in_features=768, out_features=2) # 重み初期化処理 nn.init.normal_(self.cls.weight, std=0.02) nn.init.normal_(self.cls.bias, 0) def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=False, attention_show_flg=False): # BERTの基本モデル部分の順伝搬 # 順伝搬させる if attention_show_flg == True: encoded_layers, pooled_output, attention_probs = self.bert( input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg) elif attention_show_flg == False: encoded_layers, pooled_output = self.bert( input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg) # 入力文章の1単語目[CLS]の特徴量を使用して、ポジ・ネガを分類します vec_0 = encoded_layers[:, 0, :] vec_0 = vec_0.view(-1, 768) # sizeを[batch_size, hidden_sizeに変換 out = self.cls(vec_0) # attention_showのときは、attention_probs(1番最後の)もリターンする if attention_show_flg == True: return out, attention_probs elif attention_show_flg == False: return out |
重みパラメータ更新の部分です。BertLayerの全部の層で行うとヘビーなので、12層ある内の最終層と追加したLinearのみで行います。そして、最適化手法と損失関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 勾配計算を最後のBertLayerモジュールと追加した分類アダプターのみ実行 # 1. まず全部を、勾配計算Falseにしてしまう for name, param in net.named_parameters(): param.requires_grad = False # 2. 最後のBertLayerモジュールを勾配計算ありに変更 for name, param in net.bert.encoder.layer[-1].named_parameters(): param.requires_grad = True # 3. 識別器を勾配計算ありに変更 for name, param in net.cls.named_parameters(): param.requires_grad = True # BERTの元の部分はファインチューニング optimizer = optim.Adam([ {'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5}, {'params': net.cls.parameters(), 'lr': 5e-5} ], betas=(0.9, 0.999)) # 損失関数の設定 criterion = nn.CrossEntropyLoss() |
6.コード全体と実行
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
コードを実行するとたった2epochの学習で、テストデータの正解率は約90%に達します。
判定根拠の明示は、HTMLを使ってAttentionが掛かっている単語に赤マーカーを付けます(Attentionの掛かり方が大きいほど濃い赤マーカーにします)。

これはPositiveと推論した結果の例ですが、fabulous(素晴らしい), wonderful(素敵な), geatest(最高の)などにAttentionが掛かっていて、これを根拠にPositiveを判定していることが分かります。
(参考)
・つくりながら学ぶ! PyTorchによる発展ディープラーニング
・自然言語処理の王様「BERT」の論文を徹底解説













コメントを残す