
今回もKeras のサンプルプログラム MLP を改造してみることで、さらに定番パターンを勉強したいと思います。
こんにちは cedro です。
先回は、Keras のサンプルプログラム MLP を改造し、オリジナルデータセットを読み込ませ、ロスや精度の推移グラフ、Confusion Matrix 、ネットワークモデルを描かせてみました。
今回は、その次の段階、学習結果を使って、新規データのクラス予測をやってみます。
ネットワークモデルは新たなものに変えても良いのですが、MLP は全結合だけの単純なモデルなので、兎に角学習スピードが速いのが魅力的。
とりあえず、一通りやってみるには、MLP の方がいいやという結論に達しました。
ということで、今回もKeras のサンプルプログラム MLP を改造してみることで、さらなる定番パターンを勉強したいと思います。
先回のプログラムのおさらい
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop from sklearn.model_selection import train_test_split ### from PIL import Image ### 追加 import numpy as np ### 追加 import glob ### 追加 batch_size = 128 num_classes = 10 epochs = 20 # the data, split between train and test sets #(x_train, y_train), (x_test, y_test) = mnist.load_data() ### hiragana dataset ### folder = ["0","1","2","3","4","5","6","7","8","9"] image_size =28 x = [] y = [] for index, name in enumerate(folder): dir = "./hiragana/" + name files = glob.glob(dir + "/*.png") for i, file in enumerate(files): image = Image.open(file) image = image.convert("L") image = image.resize((image_size,image_size)) data = np.asarray(image) x.append(data) y.append(index) x = np.array(x) y = np.array(y) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) x_train = x_train.reshape(x_train.shape[0], 784) ### 28×28=784 x_test = x_test.reshape(x_test.shape[0], 784) ### 28×28=784 ###### x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |
先回作った、 mnist_mlp.py をオリジナルのひらがなデータセットを読み込むように改造したプログラムです。
ロス&精度推移グラフ、Confusion Matrix、ネットワークモデルを描く部分は省いてあります。このプログラムに学習モデルを保存する部分を追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
### Save model and weights ### import os save_dir = os.path.join(os.getcwd(), 'saved_models') ### 学習ファイルの保存先 model_name = 'hiragana_trained_model.h5' ### 学習ファイルの名前 if not os.path.isdir(save_dir): os.makedirs(save_dir) model_path = os.path.join(save_dir, model_name) model.save(model_path) ### 学習ファイルの保存 print('Saved trained model at %s ' % model_path) |
これをプログラムの最後に追加します。
学習モデルの保存方法は3種類あり、重みファイルのみを保存する model.save_weights、ネットワークモデルのみ保存する model.to_json()、重み・ネットワークモデルの両方を保存する model.save があります。
ここでは model.save を使い、プログラムのあるフォルダーに save_models フォルダーを作り、その中に hiragana_trained_model.h5 という学習モデルを保存します。
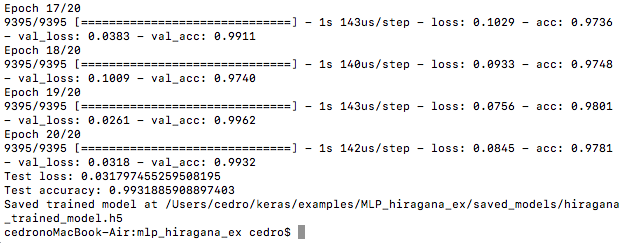
学習・評価を実行します。MLP は軽いので何か試すには、便利ですね。約20秒で完了し、学習モデルが保存されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
from keras.models import load_model from keras.utils import np_utils from PIL import Image import numpy as np import glob import matplotlib.pyplot as plt ### set test data folder = ["0","1","2","3","4","5","6","7","8","9"] image_size = 28 x = [] y = [] for index, name in enumerate(folder): dir = "./test/" + name files = glob.glob(dir + "/*.png") for i, file in enumerate(files): image = Image.open(file) image = image.convert("L") image = image.resize((image_size,image_size)) data = np.asarray(image) x.append(data) y.append(index) x = np.asarray(x) ### 画像データをNumpy配列に変換 y = np.asarray(y) ### ラベルデータをNumpy配列に変換 x_test = x.astype("float32") x_test = x_test/255.0 x_test = x_test.reshape(x_test.shape[0],784) y_test = np_utils.to_categorical(y,10) ### predict model = load_model("./saved_models/hiragana_trained_model.h5") ### 学習ファイルの読み込み score = model.evaluate(x_test, y_test, verbose=0) ### 予測実行 print('Test loss :', score[0]) print('Test accuracy :', score[1]) predict = model.predict_classes(x_test) ### 予測結果取得 ### show predict for i in range(len(x_test)): img = x[i] ### 画像データのNumpy配列の i 番目を取得 img = Image.fromarray(np.uint8(img)) ### 配列を画像に変換 plt.imshow(img, cmap ="gray") comment = "actually:"+str(y[i])+"____"+"predict:"+str(predict[i]) plt.title(comment) ### タイトルに実際ラベルと予測ラベルを入れる plt.show() ### 画像を表示 plt.close() |
学習結果を元に、予測するプログラムです。predict.py で保存します。
まず、予測したいデータを読み込みます。### set test data のところがそれで、これは学習の時と同じなので、説明は不要ですね。
次に、予測実行をします。### predict のところがそれで、 load_model で学習モデルを読み込み、model.evaluate で予測を実行し、model.predict_classes で予測結果を取得出来ます。ネットワークモデルを記述する必要なし。簡単! 素晴らしい!
最後に、予測結果を表示します。### show predict のところがそれで、予測した画像に実際ラベルと予測ラベルを書き加えてmatplotlib で表示します。
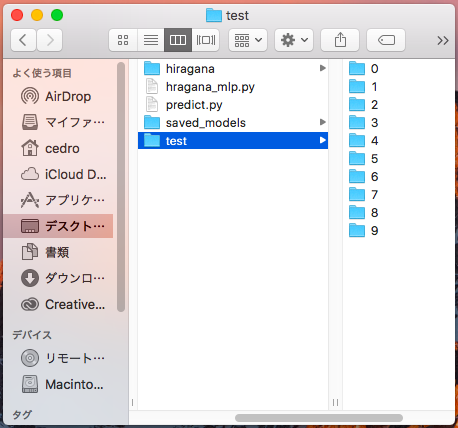
今回、予測する画像は、学習・評価に使ったものとは別のものを用意します。test フォルダーを作り、その下に0〜9フォルダーを作って、その中に「あ」〜「こ」を1枚づつ計10枚格納します。

プログラムを実行すると、すぐ結果が出て、予測精度100%(Test accuracy : 1.0)と表示されました。

「あ」の予測結果です。予測結果は実際ラベル0、予測ラベル0(actually:0___predict:0)と表示されました。正解です! 表示を消す度に、次の予測した画像を順次表示します。
keras は必要な機能ブロックを組み合わせるだけで動かせて便利ですね。
では、また。












コメントを残す