
今回は、ロイター・ニュースをMLPでカテゴリー分類するプログラムは、一体何をしているのか理解したいと思います。
こんにちは cedro です。
そろそろ、自然言語処理をやってみたいと思い、とっかかりを探していました。例によって、Keras のサンプルプログラムの中から物色した結果、初級編としてはロイター・ニュースをMLPでカテゴリー分類するものが良いのかなと思いました。
で、とりあえず動かしてみたわけです。私の Macbook Air でもあっという間に(1分以内に)完了したのは良かったわけですが、アウトプットは、Test accuracy: 0.7929652715939448 という文字がスクリーンに表示されるだけ。何をやっているのか、全く分かりませんでした。
という訳で、自然言語処理に踏み込む第一歩として、今回は、ロイター・ニュースをMLPでカテゴリー分類するプロフラムは、一体何をしているのか理解したいと思います。
ロイター・ニュースのデータセットとは?
ロイター・ニュースのデータセットとは、11,228個のニュース・データが46種類のカテゴリーに分類されたもので、ニュース・データの単語は数字で表現されています。この数字は、同じ単語なら同じ数字が割り振られ、データ全体に登場する回数が多い単語ほど小さい数字が割り振られています。
|
1 2 3 4 5 6 |
from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data() # データの読み込み print('x_train[0]:',x_train[0]) # x_train の0番目の内容を表示 print('y_train[0]:',y_train[0]) # y_train の0番目の内容を表示 |

実際のニュースデータとカテゴリーの内容を見るためのプログラムです。実行すると、ニュースデータ(x_train) と カテゴリー(y_train) の一番最初のデータ [0] を表示します。ニュースデータは87個の数字(データによって個数は異なります)、カテゴリーは1個の数字で表される訳です。ちょっと味気ないですね(笑)。
|
1 2 3 4 5 |
from keras.datasets import reuters word_index = reuters.get_word_index() print(word_index) |

kerasのデータセットには、ロイター・ニュースの単語を数字に変換する辞書があるので、まずそれを見てみましょう。このプログラムを実行すると、辞書の中身が見えます。先頭が { で ‘ ‘ で囲まれた単語を数字に変換した結果が : の次に書かれています。例えば、単語 ‘ mdbl ‘ を数字に変換すると 10996 になるという訳です。それでは、この辞書を使って、先ほどのニュースデータの数字を単語に戻してみましょう。
|
1 2 3 4 5 6 7 8 |
from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data() word_index = reuters.get_word_index() # 辞書の取得 reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) # 逆引き辞書作成 decoded_newswire = ' '.join([reverse_word_index.get(i -3,'?') for i in x_train[0]]) # 逆引き辞書から単語へ変換 print(decoded_newswire) |

ニュースデータの87個の数字を単語に戻すプログラムです。実行すると、辞書(単語→数字)を取得して来て、逆引き辞書(数字→単語)を作成し、単語へ変換します。文章の内容は「ある会社がある会社を買収して、利益が順調に伸び、配当も期待できそうだ」という意味の様です。英語は良く分かりませんが、さすがに数字よりはこっちの方が良いですね(笑)。
|
1 2 3 4 5 6 |
from keras.datasets import reuters word_index = reuters.get_word_index() reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) print(reverse_word_index) |

逆引き辞書の中身を確認するプログラムです。実行すると、先ほど表示した辞書とは、反対の表記になっていることが分かります。
|
1 2 3 4 5 6 7 8 9 10 |
from keras.datasets import reuters word_index = reuters.get_word_index() reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) c = 1 for i in range(10): print(c,reverse_word_index[c]) c +=1 |
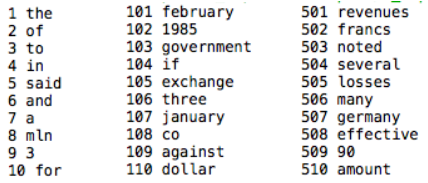
辞書の数字は出現頻度が高い単語ほど小さくなるので、出現頻度トップ10の単語を見るためのプログラムです。実行してみると、映えあるベスト1は「 the 」でした! パチパチパチ。以下、c の値を変えて、100位あたり、500位あたりも見て見ましたが、そう特別な単語がある訳ではないですね。
一つ注意したいのは、データセットは1〜3を特別な意味を表す数字として使っているので、辞書で単語を数字に変換する場合は、3を加えて変換します。例えば 「said」 を数字に変換する時は、5+3=8となります。

せっかくなんで、最下位の方も見てみました。辞書に登録されている単語は、全部で30978個で、さすがにこの辺りになるとよく分からない単語ばかりになります。そうした中、映えある最下位は、「 jung」でした。
サンプルプログラムを順番に見て行きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from __future__ import print_function import numpy as np import keras from keras.datasets import reuters from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.preprocessing.text import Tokenizer max_words = 1000 batch_size = 32 epochs = 5 print('Loading data...') # 頻出上位1000位までの単語を対象に読み込む。データは学習:評価=8:2とする。 (x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words, test_split=0.2) print(len(x_train), 'train sequences') # 学習データの個数を表示 print(len(x_test), 'test sequences') # 評価データの個数を表示 num_classes = np.max(y_train) + 1 # クラス数を計算 print(num_classes, 'classes') # クラス数を表示 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
print('Vectorizing sequence data...') tokenizer = Tokenizer(num_words=max_words) x_train = tokenizer.sequences_to_matrix(x_train, mode='binary') x_test = tokenizer.sequences_to_matrix(x_test, mode='binary') print('x_train shape:', x_train.shape) print('x_test shape:', x_test.shape) print('Convert class vector to binary class matrix ' '(for use with categorical_crossentropy)') y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) print('y_train shape:', y_train.shape) print('y_test shape:', y_test.shape) |
Tokenizer を使って、文章をベクトル化する部分です。各ニュースのデータ数はまちまちですが、MLPに掛ける時には一定にする必要があります。また、データは特徴的な部分のみ残して余分な情報は省いておく方が、その後の処理が効率的です。
今、対象単語(num_words)を10個とした場合、単語10個分のリストを作り、使っている単語は「1」、使っていない単語は「0」とすることで、一定の長さのデータになり、かつシンプルなデータ構造になります。具体的に言うと、
I like fruit —> [ 1, 2, 3 ] —> [ 1, 1, 1, 0, 0, 0, 0, 0, 0, 0 ]
I like apples —> [ 1, 2, 4 ] —> [ 1, 1, 0, 1, 0, 0, 0, 0, 0, 0 ]
An apple is a fruit —> [ 5, 6, 7, 8, 3 ] —> [ 0, 0, 1, 0, 1, 1, 1, 1, 0, 0 ]
こんな感じです。各ニュースに出て来る単語の種類のみに着目して、出現する順番や頻度の情報は省くことで、一定の長さでシンプルなデータ構造になります。この手法をBag of Words と言います。このプログラムでは、対象単語(num_words)を1000個として処理しています。
カテゴリーを表す、0〜45の数字も、keras.utils.to_categorical でこれと似たようなデータに変換します。例えば y_train [ 0 ] = 3 —> [ 0, 0, 0, 1, 0, 0, 0, ….. 0, 0 ] という感じ(3のところだけ1)。正確に言うと、これはワンホット表現と言って、46個の数字の内どれか1つだけ1で残りは全て0と言う表現です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
print('Building model...') model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.summary() # display model summary model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1) score = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=1) print('Test score:', score[0]) print('Test accuracy:', score[1]) ### Plot accuracy import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, "bo", label = "Training acc" ) plt.plot(epochs, val_acc, "b", label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("acc.png") plt.close() |
3行目からモデル構築です。入力を512個の全結合層で受けて、ドロップアウトを挟んで、46個の全結合層で出力、SoftMaxを使って46個の出力の確率を計算しています。一応、プログラム起動時に、モデルを表示したかったので、9行目に model.summary() を追加しました。26行目からは、予測精度の推移グラフを表示させる部分を追加しました。
プログラムを動かします
プログラムの起動初期画面です。ロイター・ニュースの内容やプログラムの動きを理解してから改めて動かしてみると、今までとは全然違う気持ちで画面を見れますね(笑)。
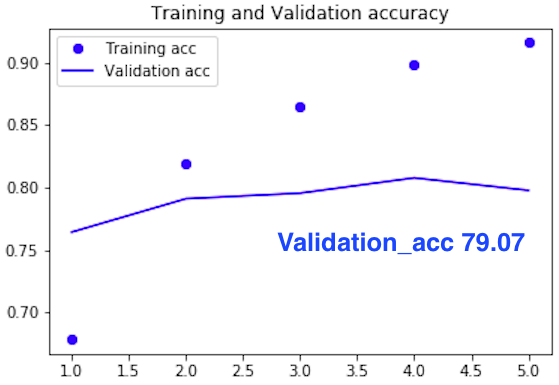
予測精度の推移グラフです。プログラムは、あっと言う間に完了し、予測精度は 5 epoch で79.07%でした。MLPは軽くて高速に動きますので、どんどんやってみたくなり、10 eopch を試してみましたが 79.16% とほとんど変わらず、グラフを見てもそれ以上は望めない感じです。
それならばと次は、max_words = 1000 を最大の 30978 にしてみようと、トライしてみました。計算量は飛躍的に増えますが、MLPですから 1epoch / 60 sec くらいで、楽勝です。
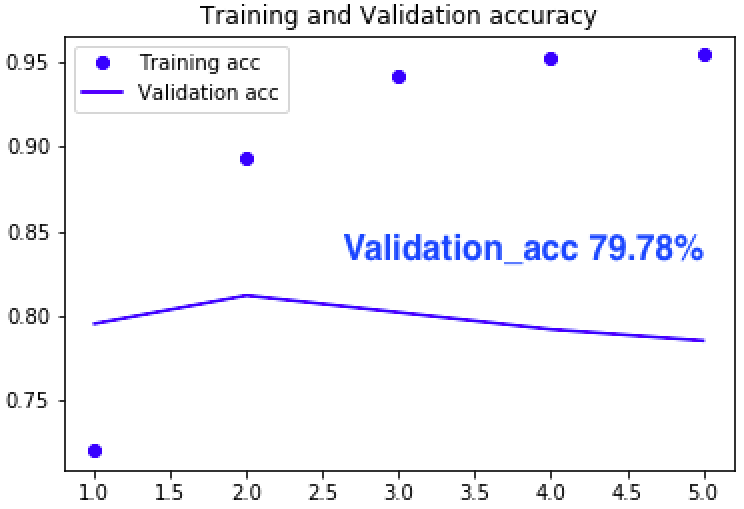
いやー、予想外でした。ほとんど変わらないんです。サンプルプログラムの設定、最適化されてます。それにしても、使っている単語数は 30,978語もあるのに、その中の頻出1000語だけを使うだけで、全部使ったのとほとんど変わらない予測精度が出せるのは、面白ですね。基本的な単語に絞っても、カテゴリーによって使う単語に結構違いがあるということでしょうか。
では、また。














コメントを残す