
こんにちは cedro です。
先回は、Neural Network Libraries のサンプルプログラム DCGAN を改造して、顔画像生成の学習をさせました。
今回は、それに引き続き、いわゆる学習済みモデルの推論実行をやってみます。
クラス分類のプログラムであれば、推論実行は、新たなデータを見せて即座にどのクラスに属するのか判定させるという形になりますが、DCGANの場合は、どうなるのでしょうか。
その前に、DCGANの復習を簡単にしておきます。
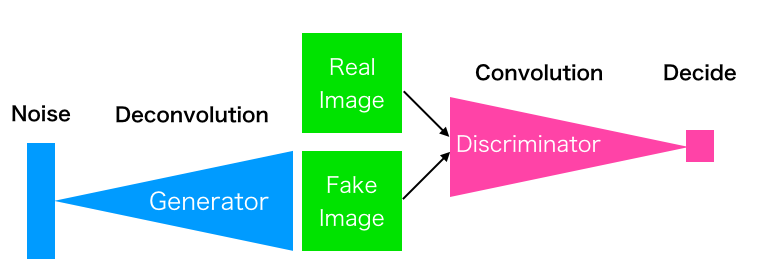
これは DCGAN の模式図です。Generator は Noise を入力として、Discriminator に本物と間違わせるような偽物を作成することを学習します。
一方、Discriminator は本物と偽物を間違えないように学習します。この2つのネットワークが切磋琢磨することで高度な画像生成ができる様になります。
Generator はノイズから画像を作るという難しい作業をしているので、最初の頃は砂嵐の様な画像ばかりしか作れなくて、Discriminator はすぐ偽物だと分かっちゃう様な気もしますよね。
でも、最初は Discriminator も何も学習してませんから、砂嵐が来ようが、本物が来ようが分かりゃしません。そのうち、両者の切磋琢磨が始まる、というわけです。
ということで、DCGAN の推論実行は、ノイズを入力したら即座に偽画像を生成する、ということになります。
DCGAN プログラムを推論実行用に修正する
まず、サンプルプログラム DCGAN のプログラムの構成を見てみましょう。
1)import >必要
2)generator のネットワーク定義 >必要
3)discriminator のネットワーク定義
4)GPU使用有無確認
5)generator のネットワーク構築 >一部必要
6)discriminator のネットワーク構築
7)Solver の設定
8)Monitor の設定 >一部必要
9)学習ループ
・データ(画像、ノイズ)読み込み >一部必要
・generator の学習パラメータ更新、モニター出力 >一部必要
・discriminator の学習パラメータ更新、モニター出力
・generator, discriminator の学習パラメータセーブ(1000回に1回)
この中で、必要なのは、1)、2)、5)と8)の一部、9)の一部。後は、不要です。一部必要な部分だけ、順に見て行きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Fake path z = nn.Variable([args.batch_size, 100, 1, 1]) fake = generator(z) fake.persistent = True # Not to clear at backward pred_fake = discriminator(fake) loss_gen = F.mean(F.sigmoid_cross_entropy( pred_fake, F.constant(1, pred_fake.shape))) fake_dis = fake.unlinked() pred_fake_dis = discriminator(fake_dis) loss_dis = F.mean(F.sigmoid_cross_entropy( pred_fake_dis, F.constant(0, pred_fake_dis.shape))) |
generator のネットワーク構築部分です。ロス定義の部分は、不要ですね。
|
1 2 3 4 5 6 7 8 |
# Fake path nn.clear_parameters() ### 追加 z = nn.Variable([64, 100, 1, 1]) fake = generator(z) y = fake ### 追加 nn.parameter.load_parameters(".\\generator_param_004000.h5") ### 追加 |
ということで、こんな形。nn.clear_parameters() でパラメーター領域を一端クリアして、ノイズ Z のShape を定義し、fake = generator(z), y = fake でネットワークを構築しています。
そして、nn.parameter.load_parameters( ” .\\ generator_param_020000.h5 ” ) で学習したパラメーターを読み込みます。
*先回、学習は4,000ステップで終了しましたが、さすがにちょっと物足りなかったので、再度20,000ステップ廻して、学習パラメーターを作り直しています。但し、そんなにクオリティは上がりませんでしたが。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Create monitor. import nnabla.monitor as M monitor = M.Monitor(args.monitor_path) monitor_loss_gen = M.MonitorSeries("Generator loss", monitor, interval=10) monitor_loss_dis = M.MonitorSeries( "Discriminator loss", monitor, interval=10) monitor_time = M.MonitorTimeElapsed("Time", monitor, interval=100) monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=100, num_images=64, normalize_method=lambda x: x + 1 / 2.) |
monitor 部分です。fake image を保存する部分だけ残せば良いですね。
|
1 2 3 4 5 6 7 |
# Create monitor. import nnabla.monitor as M monitor = M.Monitor("c:\\Users\\cedro\\dcgan_replay") monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=1, num_images=64, normalize_method=lambda x: x + 1 / 2.) |
ということで、こんな形。monitor をインポートして、fake image を保存するディレクトリーを指定し、fake image の保存の仕方を設定します。毎回、8×8(8×8=64)のタイル状で fake imageを保存する設定です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
data = d.data_iterator_csv_dataset(".\\face64.csv",args.batch_size, shuffle=True, normalize=False) # Training loop. for i in range(args.max_iter): if i % args.model_save_interval == 0: with nn.parameter_scope("gen"): nn.save_parameters(os.path.join( args.model_save_path, "generator_param_%06d.h5" % i)) with nn.parameter_scope("dis"): nn.save_parameters(os.path.join( args.model_save_path, "discriminator_param_%06d.h5" % i)) # Training forward image, _ = data.next() x.d = image / 255. - 0.5 # [0, 255] to [-1, 1] z.d = np.random.randn(*z.shape) |
Training loop 部分です。入力はプログラムの中で発生させるノイズだけなので、データの読み込みは不要です。また、定期的なパラメーターの保存も不要です。
|
1 2 3 4 5 6 7 |
# Training loop. for i in range(40): # Training forward z.d = np.random.randn(*z.shape) y.forward() ### 追加 |
ということで、こんな形。z.d = np.random.randn ( *z.shape ) でノイズを入力し、お約束の y.forward () で推論実行です。ループは40回廻すことにしています。
|
1 2 3 4 5 6 7 8 9 10 |
# Generator update. solver_gen.zero_grad() loss_gen.forward(clear_no_need_grad=True) loss_gen.backward(clear_buffer=True) solver_gen.weight_decay(args.weight_decay) solver_gen.update() monitor_fake.add(i, fake) monitor_loss_gen.add(i, loss_gen.d.copy()) |
Generator 関係のアップデート部分です。Solver は不要ですね。モニターの必要な部分のみ残します。
|
1 2 3 4 |
# Generator update. monitor_fake.add(i, fake) |
ということで、こんな形。
プログラム全体を載せておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
from __future__ import absolute_import from six.moves import range import numpy as np import nnabla as nn import nnabla.logger as logger import nnabla.functions as F import nnabla.parametric_functions as PF import nnabla.solvers as S import nnabla.utils.save as save from args import get_args import os def generator(z, maxh=256, test=False, output_hidden=False): """ Building generator network which takes (B, Z, 1, 1) inputs and generates (B, 3, 28, 28) outputs. """ # Define shortcut functions def bn(x): # Batch normalization return PF.batch_normalization(x, batch_stat=not test) def upsample2(x, c): # Twise upsampling with deconvolution. return PF.deconvolution(x, c, kernel=(4, 4), pad=(1, 1), stride=(2, 2), with_bias=False) assert maxh / 4 > 0 #with nn.parameter_scope("gen"): # (Z, 1, 1) --> (256, 4, 4) with nn.parameter_scope("deconv1"): d1 = F.elu(bn(PF.deconvolution(z, maxh, (4, 4), with_bias=False))) # (256, 4, 4) --> (128, 8, 8) with nn.parameter_scope("deconv2"): d2 = F.elu(bn(upsample2(d1, maxh / 2))) # (128, 8, 8) --> (64, 16, 16) with nn.parameter_scope("deconv3"): d3 = F.elu(bn(upsample2(d2, maxh / 4))) # (64, 16, 16) --> (32, 28, 28) with nn.parameter_scope("deconv4"): # Convolution with kernel=4, pad=3 and stride=2 transforms a 28 x 28 map # to a 16 x 16 map. Deconvolution with those parameters behaves like an # inverse operation, i.e. maps 16 x 16 to 28 x 28. d4 = F.elu(bn(PF.deconvolution( d3, maxh / 8, (4, 4), pad=(3, 3), stride=(2, 2), with_bias=False))) # (32, 28, 28) --> (1, 28, 28) with nn.parameter_scope("conv5"): x = F.tanh(PF.convolution(d4, 3, (3, 3), pad=(1, 1))) return x # Fake path nn.clear_parameters() ### 追加 z = nn.Variable((64, 100, 1, 1)) fake = generator(z) y = fake ### 追加 # 学習済みパラメーターの読み込み nn.parameter.load_parameters(".\\generator_param_019999.h5") ### 追加 # Create monitor. import nnabla.monitor as M monitor = M.Monitor("c:\\Users\\cedro\\dcgan_replay") monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=1, num_images=64, normalize_method=lambda x: x + 1 / 2.) # Training loop. for i in range(40): z.d = np.random.randn(*z.shape) y.forward() ### 追加 monitor_fake.add(i, fake) |
*Generator のネットワーク定義の部分ですが、学習の時は2つのネットワークがあるので、with nn.parameter_scope(“gen”) とか書いてありましたが、この関連は削除しインデントを修正しています。
推論実行する
dcgan_replayというフォルダーを作成し、先程修正したプログラムを、dcgan_replay.py として保存します。後は、args.py とgenerator_param_020000.h5 (学習パラメーターを保存したファイル)を入れます。
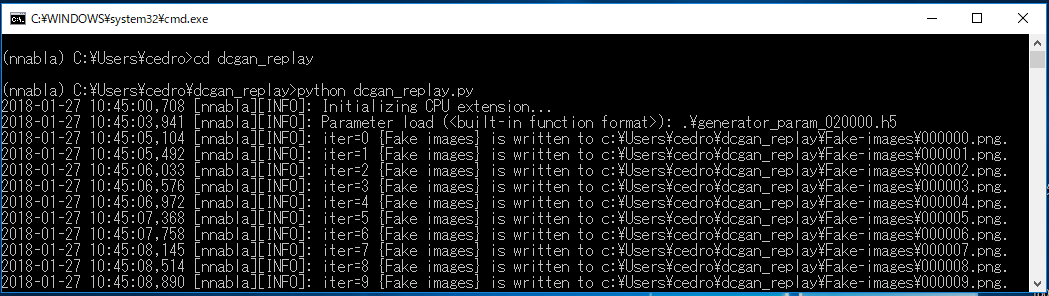
> cd dcgan_replay でフォルダーへ移動し
> pyhton dcgan_replay.py でプログラムを実行します。
学習パラメターを読み込んだら、次々に8×8のタイル画像を生成して行きます。また例によって画像生成の状況をGIF動画で見てみましょう。

画像生成が始まると、毎秒2~3枚のペースで8×8のタイル画像を生成しており、このGIF動画は実際の画像生成とほぼ同じスピードです。さすがに、推論実行のスピードは速いですね。
画像生成のチューニング

これは推論実行で生成した生成画像の中の1枚です。入力が28×28ピクセルなので、全体のクオリティが低いのは許容するとして、まあまあ顔になっているものと、崩れてしまっているものが混在しています。この差は、どこから来るのでしょうか。
もうGenerator の学習パラメーターは固定されていますので、生成画像の質を左右するのは、ノイズ(100次元ベクトル)しかありません。
そうすると、100次元ベクトルの中には、まあまあの顔を生成するベクトルAと、崩れた顔を生成するベクトルBがあって、明らかに異なるものであると思われます。
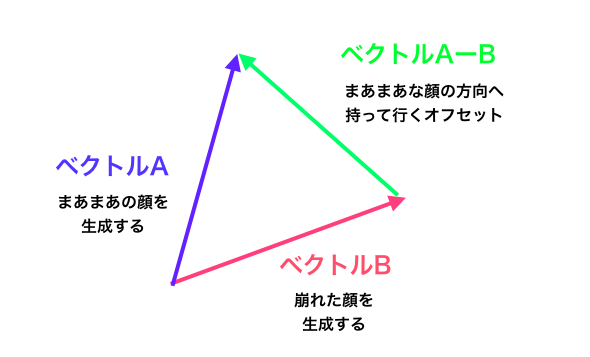
そうであれば、上図の様な、ベクトル AーB を計算して、入力のノイズにオフセットとして加えてやれば、画像生成が望ましい方向へ向かうチューニングができるはずです。
実際に、やってみましょう。
まず、画像の質と100次元ベクトルの関係を調べるために、プログラムを修正します。
|
1 2 3 4 5 6 7 8 |
# Loop for i in range(40): z.d = np.random.randn(*z.shape) y.forward() monitor_fake.add(i, fake) |
画像生成した時の100次元ベクトルを記録するために、Loop の所にプログラムを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# CSV file write import csv ### 追加 write_fp=csv.writer(open("face.csv","w")) ### 追加 # Loop for i in range(64): z.d = np.random.randn(*z.shape) y.forward() monitor_fake.add(i, fake) vector=np.ravel(z.d) ### 追加 print(vector) ### 追加 write_fp.writerow(vector) ### 追加 |
CSVライブラリーを import し、書き込み用のCSVファイル( face.csv ) を準備します。
vector = np.ravel (z.d) で100個の1×1画像を100次元ベクトルに変換し、モニターに表示すると共に、CSVファイルに書き込みます。
後、バッチサイズ=1、画像は1枚づつ表示(num_images=1)にし、64回ループを廻す設定にします。
dcgan_gen というフォルダーを作成し、修正したプログラムを dcgan_gen.py で保存します。
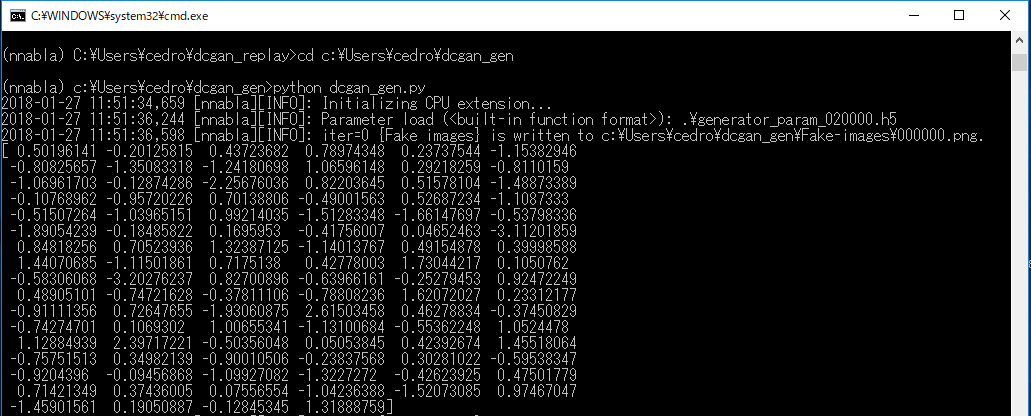
dcgan_gen フォルダーに移動し
> pyhon dcgan_gen.py でプログラムを実行します。
画面表示を見ると、生成画像 000000.png を保存した直後に、その時使われた100次元ベクトルが表示されています。この後、その100次元ベクトルをCSVファイル( face.csv )に書き込みます。
これを64回繰り返します。

上図の様な感じで、生成した64枚の画像の中から、Goodを10枚、Badを10枚選びます。
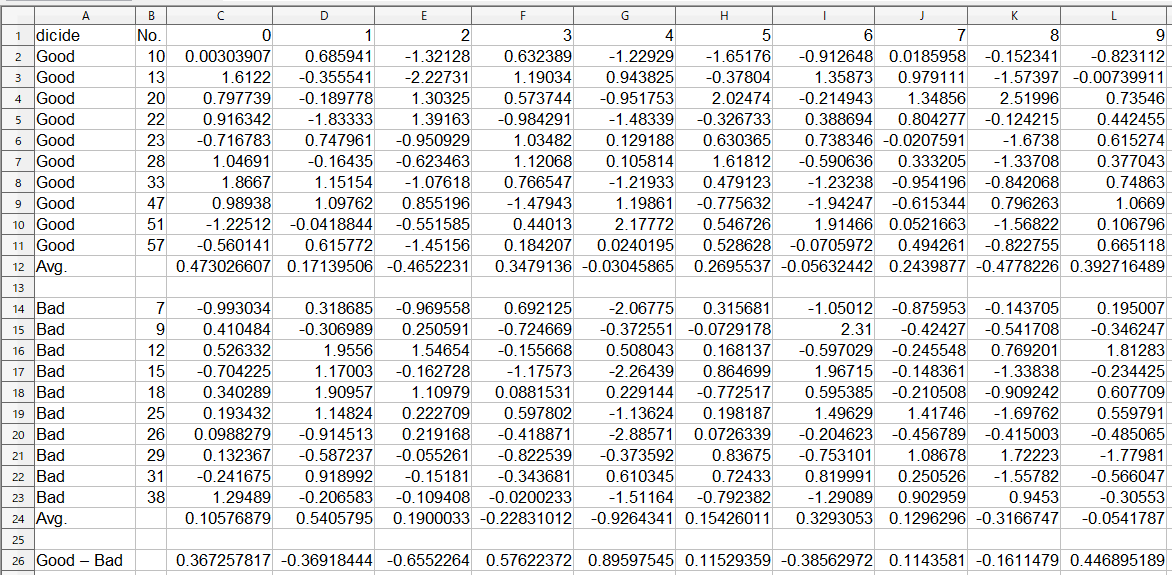
OpenOfficeのCalc を使って、該当する100次元ベクトルの各列を平均し、Goodベクトルの平均とBadベクトルの平均を求め、Good ーBadでオフセット値を求めます。
オフセット値は、offset.csv ファイル(1行×100列)に書き込んで置きます。。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# CSV file write import csv write_fp=csv.writer(open("face.csv","w")) # Loop. for i in range(64): z.d = np.random.randn(*z.shape) y.forward() monitor_fake.add(i, fake) vector=np.ravel(z.d) print(vector) write_fp.writerow(vector) |
100次元ベクトルにオフセット値を加えるためにプログラムを修正します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# CSV file write import csv write_fp=csv.writer(open("face.csv","w")) read_fp=csv.reader(open("offset.csv","r")) ### 追加 for line in read_fp: ### 追加 line=list(map(float,line)) ### 追加 offset=np.reshape(line,[100,1,1]) ### 追加 # Loop. for i in range(40): z.d = np.random.randn(*z.shape)+offset ### 修正 y.forward() monitor_fake.add(i, fake) vector=np.ravel(z.d) write_fp.writerow(vector) |
read_fp = csv.reader ( open( “offset.csv”,”r” )) で、offset.csvからの読み込みの準備をし、for line in read_fp:で1行データを読み込みます。
読み込んだデータは文字列なのでline = list ( map (float, line )) で数値に変換し、offset = np.reshape( line,[100,1,1] ) で100個の1×1画像に戻します。後は、z.d = np.random.randn (*z.shape) + offset でノイズにオフセット値を加えています。
生成画像を8×8に戻して、再度画像生成を行い、改善前と比較してみます。

左がオフセットを加える前、右がオフセットを加えた後の生成画像です。オフセットを加えることによって、とんでもない画像が減って、生成画像が望ましい方向に安定することが分かります。
この考え方を一般化すると、ある特徴量(例えば、髪の長さ、目の大きさ、鼻の高さ、顔の形など)に着目した時、その特徴量が大きくなるベクトルと小さくなるベクトルを見つけることができれば、その特徴量をコントロールできることが分かります。
うーん、DCGAN、なかなか奥の深いネットワークのようです。機会があれば、また色々触ってみたいです。
では、また。
PS 旦那、Windows7でも動きますぜ
SONY Neural Network Console を使ってみたいけど、Windows 7だからダメだとお嘆きの貴兄に。
6年前に買った私の MacbookAir は、boot champ でWindows 7しか対応不可。しかし、試しにやってみたら、動きました。もちろん、Neural Network Libraries もOKでした。
ちなみに、今回20,000ステップ廻して、学習パラメーターを作り直したのは、Windows7のNeural Network Libraries です。
騙されたと思って、一度インストールしてみてはいかがでしょうか。
動くかもよ!













コメントを残す