
今回は、マルコフ連鎖を使って、日本語の文章を自動生成してみます。
こんにちは cedro です。
以前、LSTMで文字単位の文章生成をやりましたが、そういった機械学習を使わなくても、結構それっぽい文章生成が出来るマルコフ連鎖という手法があります。
最初、「マルコフ連鎖」と聞いた時は、何か難しい学問の手法で、とっつき難いなーという印象でしたが、文章生成にどう使ったら良いのか調べてみたら、とてもシンプルな方法であることが分かりました。
ということで、今回は、マルコフ連鎖を使って、日本語の文章を自動生成してみます。
マルコフ連鎖とは?
マルコフ連鎖は、未来の挙動が現在の値だけで決定され、過去の挙動と無関係である。各時刻において起こる状態変化(遷移または推移)に関して、マルコフ連鎖は遷移確率が過去の状態によらず、現在の状態のみによる系列である。
Wikipedia には、こんなことが書いてありますが、これだけではさっぱり分かりませんね。なので、文章生成を想定して具体的な事例で説明したいと思います。
1)私は果物がとても好きです。
2)私は野菜がとても嫌いです。
こんな2つの文があった時に、マルコフ連鎖モデルを作ってみます。
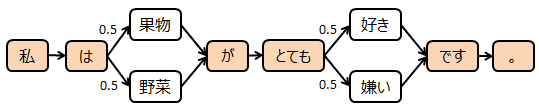
「私」→「は」と状態遷移した時、続く単語は「果物」が確率0.5、「野菜」が確率0.5です。ここで、「果物」を選択したとしましょう。次に「が」→「とても」と状態遷移した時、過去の状態を考慮するなら、続く単語は「好き」が確率1.0です。
しかし、マルコフ連鎖は、過去の遷移によらず現在の状態のみで判断するので、続く単語は先程同様「好き」が確率0.5、「嫌い」が確率0.5なのです。要するに、状態遷移のパターンを全て見つけておいて、選択肢があったら、全ての組み合わせをOKとするのが、マルコフ連鎖なのです。
そんなことなら早く言ってよ、という位すごくシンプルな手法なんです。また、この様に、2つの単語の遷移で次の単語を選択する場合は2階マルコフ連鎖と言います。一般的には、N個の単語の遷移で次の単語を選択する場合はN階マルコフ連鎖と言います。
プログラムを作ります
簡単なテキストを用意して、プログラムの動作を説明して行きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from janome.tokenizer import Tokenizer # Janomeでテキストデータを単語に分割 text = "私は果物がとても好きです。私は野菜がとても嫌いです。" wordlist =Tokenizer().tokenize(text, wakati=True) # マルコフ連鎖用辞書作成 markov = {} # 辞書初期化 w1, w2 = "", "" for word in wordlist: if w1 and w2: if (w1, w2) not in markov: # 2単語が未登録なら markov[(w1, w2)] = [] # 登録して markov[(w1, w2)].append(word) # 2単語の次の単語を追加する w1, w2 = w2, word # 1単語スライド |
マルコフ連鎖用辞書を作成する部分です。まず、6行目で、janome を使って分かち書きをします。その結果、変数 wordlist は以下の様になります。
wordlist = [‘私’, ‘は’, ‘果物’, ‘が’, ‘とても’, ‘好き’, ‘です’, ‘。’, ‘私’, ‘は’, ‘野菜’, ‘が’, ‘とても’, ‘嫌い’, ‘です’, ‘。’]
次に、11行目から、2つの連続した単語の次に、続く単語が何かを登録して行きます。その結果、辞書 markov は以下の様になります。
markov = {(‘私’, ‘は’): [‘果物’, ‘野菜’], (‘は’, ‘果物’): [‘が’], (‘果物’, ‘が’): [‘とても’], (‘が’, ‘とても’): [‘好き’, ‘嫌い’], (‘とても’, ‘好き’): [‘です’], (‘好き’, ‘です’): [‘。’], (‘です’, ‘。’): [‘私’], (‘。’, ‘私’): [‘は’], (‘は’, ‘野菜’): [‘が’], (‘野菜’, ‘が’): [‘とても’], (‘とても’, ‘嫌い’): [‘です’], (‘嫌い’, ‘です’): [‘。’]}
多くは、2つの連続した単語の次に来る単語は1つですが、(‘私’, ‘は’) の場合は [‘果物’, ‘野菜’] と2つの選択肢があり、(‘が’, ‘とても’) の場合は [‘好き’, ‘嫌い’] と2つの選択肢があることが分かります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import random # 文章生成 count = 0 # 文のカウンタ num= 5 # 生成する文の数 sentence = "" # 文を格納する変数 w1, w2 = random.choice(list(markov.keys())) # 2単語をランダムに選ぶ while count < num: tmp = random.choice(markov[(w1, w2)]) # 2単語に続く候補の中からランダムに選択する sentence += tmp # 文に1単語追加 if(tmp=='。'): # '。' があったら count += 1 # 文のカウンタを+1 sentence += '\n' # 改行を追加 w1, w2 = w2, tmp # 1単語スライド print(sentence) |
辞書を元に、文章生成する部分です。8行目で、文章生成のスタートを決めています。list (markov.keys()) は辞書の見出しを表していて、具体的に言うと
list (markov.keys()) = [(‘私’, ‘は’), (‘は’, ‘果物’), (‘果物’, ‘が’), (‘が’, ‘とても’), (‘とても’, ‘好き’), (‘好き’, ‘です’), (‘です’, ‘。’), (‘。’, ‘私’), (‘は’, ‘野菜’), (‘野菜’, ‘が’), (‘とても’, ‘嫌い’), (‘嫌い’, ‘です’)]
となります。そのため、 w1, w2 = random.choice(list(markov.keys())) ならば、この見出しの中からランダムに選んで、w1, w2 に格納することになります。
そして、10行目で辞書を使って、w1, w2 に続く単語をランダムに選びます。markov[(w1, w2) は、markov 辞書に登録されている、w1, w2 に続く単語を表します。例えば、markov [ (‘が’, ‘とても’) ] = [‘好き’, ‘嫌い’] となるわけです。
従って、もしw1, w2 = ‘が’, ‘とても’ であったら、tmp = random.choice(markov[(w1, w2)]) なので、tmp には ‘好き’ あるいは ‘嫌い’ が格納され、11行目で変数 sentence に加えられます。
後は、見出しを1つづつずらしながら、順次同じことを繰り返し、「。」が現れたら、1つの文が完成です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import random from janome.tokenizer import Tokenizer # Janomeでテキストデータを単語に分割 filename = "./data.txt" text = open(filename, "r",encoding="utf-8").read() wordlist =Tokenizer().tokenize(text, wakati=True) # マルコフ連鎖用辞書作成 markov = {} # 辞書初期化 w1, w2 = "", "" for word in wordlist: if w1 and w2: if (w1, w2) not in markov: # 未登録なら markov[(w1, w2)] = [] # 登録して markov[(w1, w2)].append(word) # 2単語の次の単語を追加する w1, w2 = w2, word # 1単語スライド # 文章生成 count = 0 # 文のカウンタ num= 10 # 生成する文の数 sentence = "" # 文を格納する変数 w1, w2 = random.choice(list(markov.keys())) # 2単語をランダムに選ぶ while count < num: tmp = random.choice(markov[(w1, w2)]) # 2単語に続く候補の中からランダムに選択する sentence += tmp # 文に1単語追加 if(tmp=='。'): # '。' があったら count += 1 # 文のカウンタを+1 sentence += '\n' # 改行を追加 w1, w2 = w2, tmp # 1単語スライド print(sentence) |
プログラムの全体を載せておきます。なお、元とのなるテキストは、data.txt というファイル(UTF-8)から読み込む形に変更しています。
プログラムを動かします
今回、元となるテキストは、推理小説にしてみましょう。青空文庫にあるアーサー・コナン・ドイルの「入院患者」をダウンロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import sys import re path = './the_resident_patient.txt' bindata = open(path, "rb") lines = bindata.readlines() for line in lines: text = line.decode('Shift_JIS') # Shift_JISで読み込み text = re.split(r'\r',text)[0] # 改行削除 text = text.replace('|','') # ルビ前記号削除 text = re.sub(r'《.+?》','',text) # ルビ削除 text = re.sub(r'[#.+?]','',text) # 入力者注削除 print(text) file = open('data.txt','a',encoding='utf-8').write(text) # UTF-8に変換 |
ダウンロードしたテキストファイルを先程作ったプログラムに適切に読ませるために前処理を行うプログラムです。実行すると、テキストファイルの形式(Shift-JIS)で読み込み、改行、ルビ、入力者注などを削除してから、 UTF-8に変換して、data.txt という名前で保存します。あとはエディターを使い、手動で、文章の前後にある、余分な部分を削除します。

プログラムが出力した文です。文節単位くらいで見えば結構いけてるところもあるのですが、文としてみると何を言っているの分からないものが多いです。マルコフ連鎖は、過去の遷移は気にせず、現在だけみていますので、これはしょうがないですね。
但し、文体の雰囲気は確かに、アーサー・コナン・ドイルです。非常にプリミティブなマルコフ連鎖という手法でも、結構面白い結果が出ます。
では、また。












コメントを残す