
1.はじめに
今まで、StyleGAN+CLIPを使って顔画像をテキストで編集するアプローチには、テキストから潜在変数を最適化する Optimaization とテキスト毎に潜在変数の差分を事前学習する Mapper がありましたが、前者は時間が掛かり後者は汎用性に欠ける弱点がありました。今回ご紹介するのは、これらの弱点を改善した Global direction というアプローチです。
*この論文は、2021年3月に提出されました。
2.Global directionとは?
まず、StyleGAN+CLIPを使って顔画像をテキストで編集する Mapper というアプローチをみてみましょう。
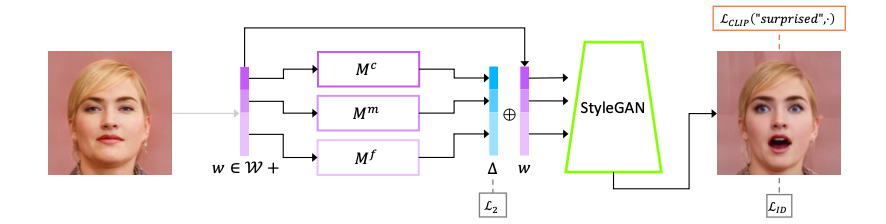
左の元画像の潜在変数wをマッピングネットワークMに入力し差分△を求め、潜在変数w+差分△をStyleGANに入力し、右の出力画像を得るネットワークを考えます。CLIP でテキストと出力画像の類似度を求め、類似度が出来るだけ高くなるようにマッピングネットワークのパラメータを学習する方法が Mapper です。
この方法は、高速な編集が可能ですが、テキストの内容毎にマッピングネットワークのパラメータを用意する必要があります。そこで、もっと汎用的にテキストから潜在変数の差分△を直接求める方法が Global direction です。
そのためには、テキストからCLIP で特徴ベクトルを求め、その特徴ベクトルを入力として差分△を出力するマッピングネットワークを考えます。そして、CLIP でテキストと出力画像の類似度を求め、類似度が出来るだけ高くなるようにマッピングネットワークのパラメータを学習すれば良いわけです。そうすれば、高速な編集と汎用性が両立できます。

ただ、これだけだと、テキストで指示する内容はどうしても曖昧さ(バラツキ)が多くなります。そこで、テキストの内容を安定化させる工夫を行います。
具体的には、テキストをニュートラルクラスとターゲット属性に分けて明示し、テンプレートに従って同じ意味を持つ複数の文をCLIPに入力して求めた特徴ベクトルを平均化するプロンプトエンジニアリングと呼ばれる手法が使われています。
それでは、コードを動かしてみましょう。
3.セットアップ
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title install cuda10.0 # download data !wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !rm /etc/apt/sources.list.d/cuda.list !sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub !sudo apt-get update !wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt install -y ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt-get update # install NVIDIA driver !sudo apt-get -y installnvidia-driver-418 # install cuda10.0 !sudo apt-get install -y \ cuda-10-0 \ libcudnn7=7.6.2.24-1+cuda10.0 \ libcudnn7-dev=7.6.2.24-1+cuda10.0 # install TensorRT !sudo apt-get install -y libnvinfer5=5.1.5-1+cuda10.0 \ libnvinfer-dev=5.1.5-1+cuda10.0 !apt --fix-broken install |
|
1 2 3 4 5 |
! pip install tensorflow==1.15.0 ! pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html ! pip install ftfy regex tqdm ! pip install git+https://github.com/openai/CLIP.git ! git clone https://github.com/cedro3/StyleCLIP.git |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# input dataset name dataset_name='ffhq' # input dataset name, currently, only support ffhq % cd StyleCLIP/global/ # input prepare data !python GetCode.py --dataset_name $dataset_name --code_type 'w' !python GetCode.py --dataset_name $dataset_name --code_type 's' !python GetCode.py --dataset_name $dataset_name --code_type 's_mean_std' import tensorflow as tf import numpy as np import torch import clip from PIL import Image import pickle import copy import matplotlib.pyplot as plt from MapTS import GetFs,GetBoundary,GetDt from manipulate import Manipulator device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device) M=Manipulator(dataset_name='ffhq') fs3=np.load('./npy/ffhq/fs3.npy') np.set_printoptions(suppress=True) |
4.画像編集
global/vec に顔画像から取得した潜在変数(000.pt 〜 016.pt)が保存されていますので、pt_name に 009.pt を設定して下さい。ご自分でオリジナルの潜在変数を用意したい方は、このブログのコードで作成して global/vec に追加して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# --- 画像の選択 --- pt_folder = 'vec/' pt_name = '009.pt' #@param {type:"string"} latents=torch.load(pt_folder+pt_name) w_plus=latents.cpu().detach().numpy() M.dlatents=M.W2S(w_plus) img_indexs=[0] dlatent_tmp=[tmp[img_indexs] for tmp in M.dlatents] M.num_images=len(img_indexs) M.alpha=[0] M.manipulate_layers=[0] codes,out=M.EditOneC(0,dlatent_tmp) original=Image.fromarray(out[0,0]).resize((512,512)) M.manipulate_layers=None original |

潜在変数 009.pt から生成される顔画像が表示されます。
次に、編集内容をテキストで指定します。指定方法は neutral に属性を指定し、 target に目的の方向を指定します。
|
1 2 3 4 5 6 |
# --- テキスト入力 --- neutral='face with hair' #@param {type:"string"} target='smiling face with curly hair' #@param {type:"string"} classnames=[target,neutral] dt=GetDt(classnames,model) |
次に、係数の設定をします。beta はある属性を変化させたとき、関連する属性の変化をどこま受け入れるかのしきい値 です。小さくするとより多くの関連した属性の変化が反映されます(beta=0.1くらいが良い)。alpha は、潜在変数の差分に効かせる倍率です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# --- alpha & beta の設定 --- beta = 0.1 #@param {type:"slider", min:0.08, max:0.3, step:0.01} alpha = 2.5 #@param {type:"slider", min:-10, max:10, step:0.1} M.alpha=[alpha] boundary_tmp2,c=GetBoundary(fs3,dt,M,threshold=beta) codes=M.MSCode(dlatent_tmp,boundary_tmp2) out=M.GenerateImg(codes) generated=Image.fromarray(out[0,0])#.resize((512,512)) plt.figure(figsize=(14,7), dpi= 100) plt.subplot(1,2,1) plt.imshow(original) plt.title('original') plt.axis('off') plt.subplot(1,2,2) plt.imshow(generated) plt.title('manipulated') plt.axis('off') |

左が編集前の画像、右が編集後の画像です。狙いに合った編集ができているか確認し、必要に応じて alpha を変化させてコードを実行させることを繰り返し、適正な値をチェックしてみて下さい。
alpha を少しづつ変化させた時(beta = 0.1 で固定)に、顔画像が徐々に変化する動画を作成してみましょう。max_alpha に alpha の最大値を入力します。変化させた画像は、global/pic に保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# --- 編集画像の連続生成 --- max_alpha = 2.5 #@param {type:"slider", min:0, max:10, step:0.1} num = int(max_alpha*10) beta = 0.1 from tqdm import trange import os import shutil # pic フォルダーリセット if os.path.isdir('pic'): shutil.rmtree('pic') os.makedirs('pic', exist_ok=True) # 画像生成関数 def generate_img(alpha, cnt): M.alpha=[alpha] boundary_tmp2,c=GetBoundary(fs3,dt,M,threshold=beta) codes=M.MSCode(dlatent_tmp,boundary_tmp2) out=M.GenerateImg(codes) pic = Image.fromarray(out[0,0]) pic = pic.resize((512,512)) # orijinal と連結 dst = Image.new('RGB', (original.width + pic.width, original.height)) dst.paste(original, (0,0)) dst.paste(pic, (original.width, 0)) dst.save('./pic/'+str(cnt).zfill(6)+'.png') # alpha を変化させて画像生成 cnt = 0 for i in trange(15, desc='alpha = 0'): generate_img(0, cnt) cnt +=1 for i in trange(0, num, 1, desc='alpha = 0 -> max'): generate_img(i/10, cnt) cnt +=1 for i in trange(60, desc='alpha = max'): generate_img(num/10, cnt) cnt +=1 |
global/pic/ に保存した画像からmp4動画を作成します。作成した動画は、output.mp4 という名称で一時保存するとともに、global/movie/ に smiling face with curly hair _009.mp4 という形で保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# --- mp4動画の作成 --- # 既に output.mp4 があれば削除する import os if os.path.exists('./output.mp4'): os.remove('./output.mp4') # pic フォルダの画像から動画を生成 ! ffmpeg -r 30 -i pic/%6d.png\ -vcodec libx264 -pix_fmt yuv420p output.mp4 # movieフォルダへ名前を付けてコピー import shutil os.makedirs('movie', exist_ok=True) shutil.copy('output.mp4', 'movie/'+target+'_'+pt_name[:-3]+'.mp4') |
作成したmp4動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# --- mp4動画の再生 --- from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="70%" height="70%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |

あとは、画像編集の最初から繰り返せばOKです。下記の設定に変更して再度やってみましょう。
- pt_name : 012.pt
- nutral : face with eyes
- target : smiling face with eyeglasses
- alpha :3.5

もう1つ、やってみましょう・
- pt_name : 010.pt
- nutral : face with hair and eyes
- target : smiling face with blonde hair and blue eyes
- alpha : 3.0

では、また。
(オリジナル github)https://github.com/orpatashnik/StyleCLIP
(twitterへの投稿)














自分の顔画像やラグビー日本代表のあの人のように、任意の画像を読み込ませることは可能でしょうか。
桜田ふぁみりあさん
コメントありがとうございます。可能です。
自分のオリジナル画像でやる場合は、ブログに記載しましたように「StyleGANを使った画像編集をe4eで高速化する」のブログにある方法でオリジナル画像の潜在変数を用意して、global/vec にアップロードすればOKです。
もっと簡単にまとめてやりたいという場合は、このリンク[https://github.com/cedro3/Style_edit/blob/main/Style_edit_movie.ipynb]のClolabを動かし、Style_edit/images に自分のオリジナル画像をアップロードすればOKです。
ご丁寧に回答いただきありがとうございます。
早速試してみます。