
今回は、変分オートエンコーダ(VAE)のサンプルプログラムで遊んでみます。
こんにちは cedroです。
変分オートエンコーダ(Variational Auto Encoder = VAE )をご存知ですか。
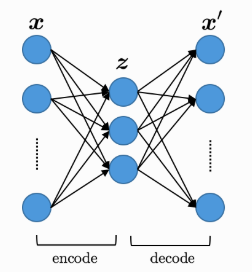
普通のオートエンコーダは、入力Xを潜在変数Zに次元圧縮することによって特徴量を学習するニューラルネットワークです。MNISTを例にとれば、学習を完了すると、ある数字Xを入力すると同じ形の数字X’を出力します。
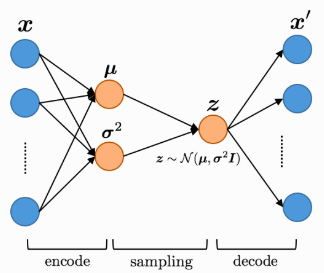
一方、変分オートエンコーダーは、潜在変数Zが正規分布に従うように学習させることで、オートエンコーダと同様なことを実現するだけでなく、潜在変数Zを直接操作することで生成出力X’をコントロールすることができます。
ということで、今回は、変分オートエンコーダのサンプルプログラムで遊んでみます。
早速プログラムを動かしてみます
keras / examples / variational_autoencoder.py を適当なフォルダーに格納します。
|
1 2 3 |
python variational_autoencoder.py |
フォルダーに移動し、上記コマンドを入力すれば、プログラムが動きます。潜在変数Zは2次元です。
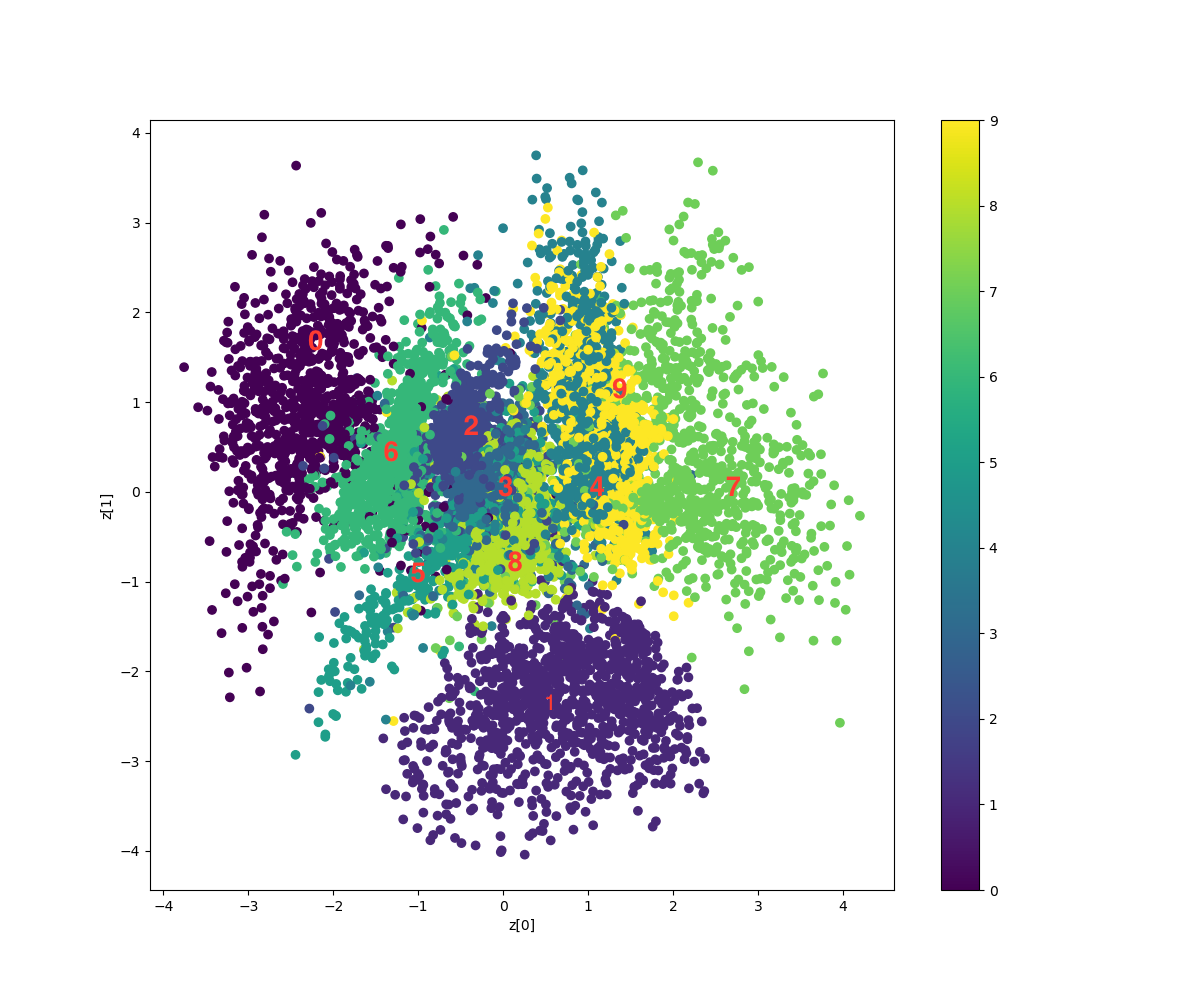 学習が完了すると、MNISTの0〜9の数字が潜在変数Zの2次元マップの何処にマッピングされたかの結果が表示されます(図の中の赤色の数字は、分かりやすいように後で追記しています)。
学習が完了すると、MNISTの0〜9の数字が潜在変数Zの2次元マップの何処にマッピングされたかの結果が表示されます(図の中の赤色の数字は、分かりやすいように後で追記しています)。
これの何が凄いかというと、教師なし学習なのに、同じ数字はマップの大体同じエリアに集まり、綺麗に分類されているということです。
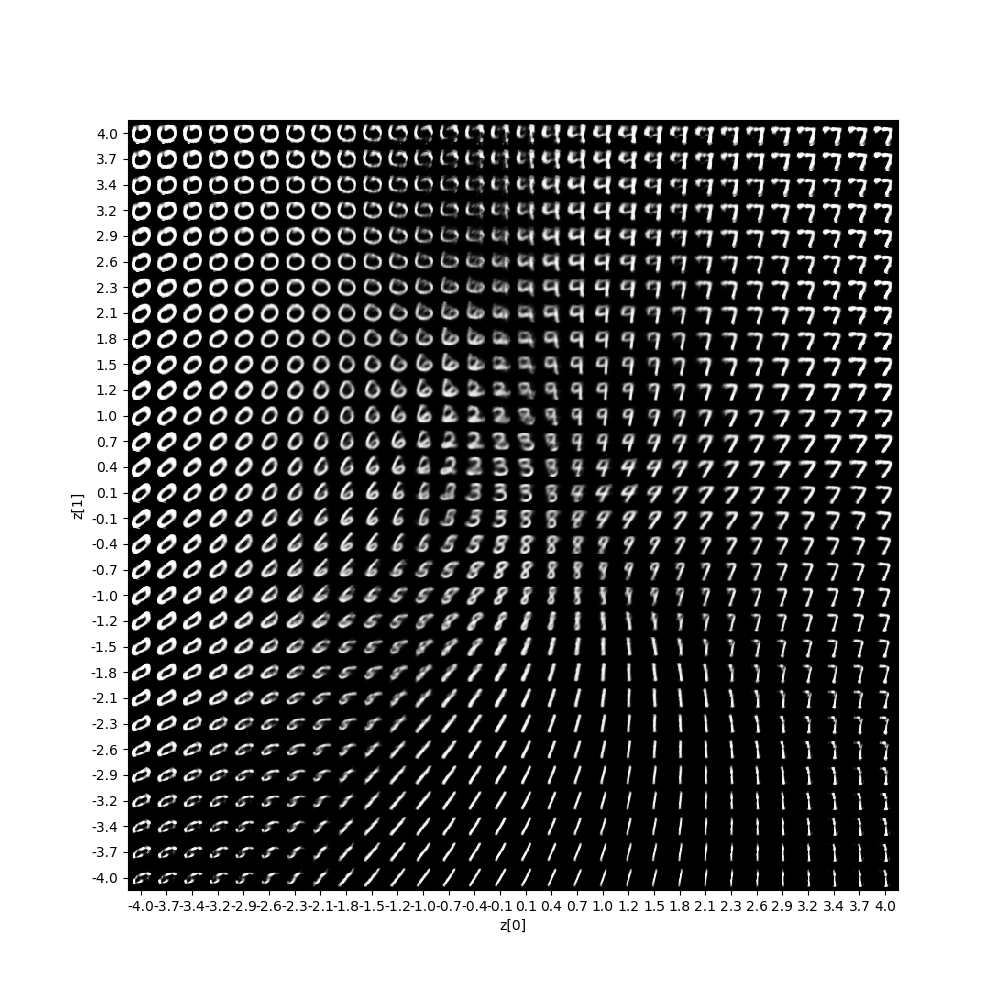
もう1つ出力されるのが、これ。これは、潜在変数Zのデータから、どのような出力X’が生成されるかをマッピングしたものです。
これの何が凄いのかと言うと、画像を入力をしなくても、潜在変数Zのデータを操作するだけで、出力X’を生成しているんです。
しかも、正規分布に従うように学習しているので、隣り合った画像は連続的に変化するような分布になっています。
なので、潜在変数Zのデータを赤矢印のように操作して画像を生成させると、MNISTの数字のモーフィングができるはずです。やってみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) plt.imshow(digit,cmap='Greys_r') ### 追加 plt.savefig(str(i)+'@'+str(j)+'fig.png') ### 追加 figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit |
プログラムの93行目から99行目までのところに、上記の様に2行追加して、実行します。これで、出力画像を1枚づつ □□@△△fig.png (□□は行数、△△は列数)の形式で保存してくれます。
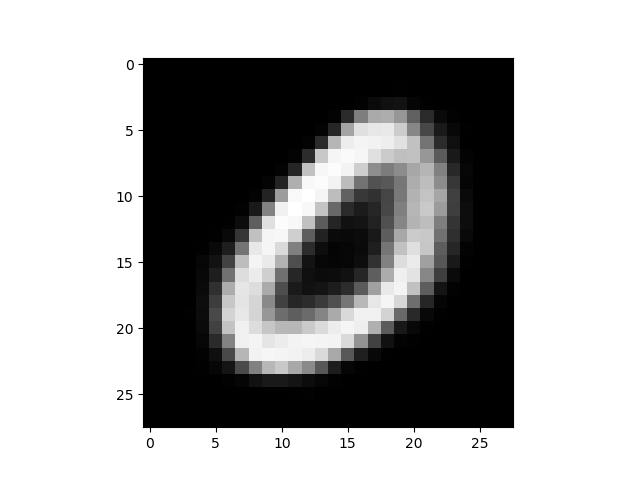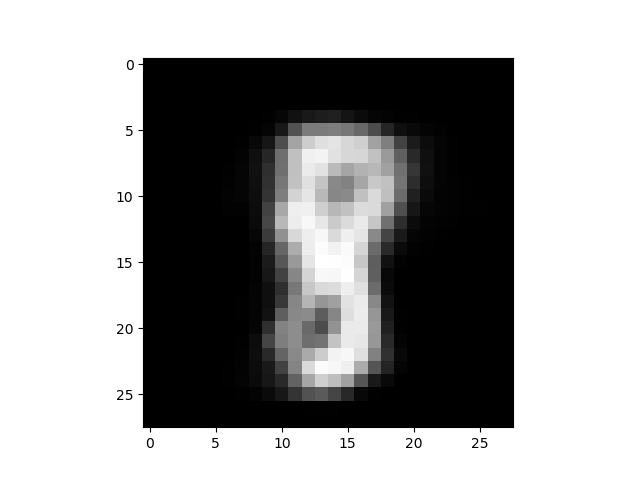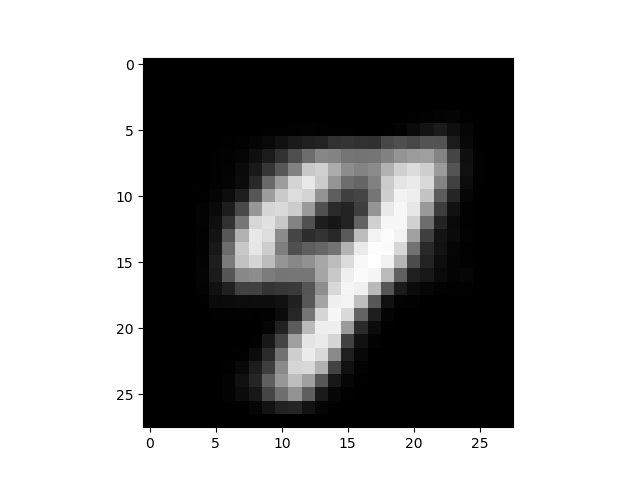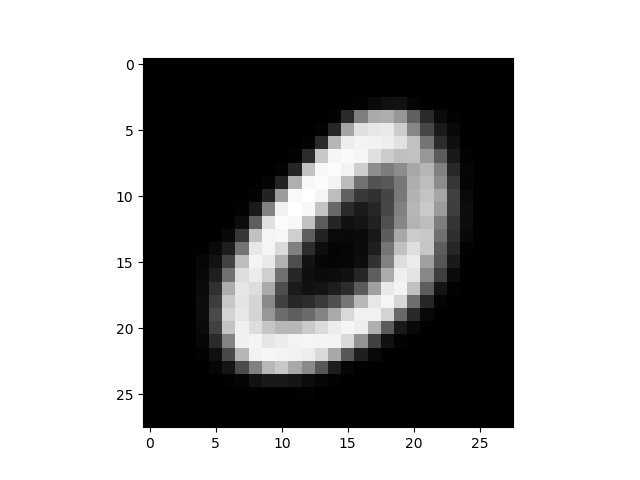
保存した出力画像から必要なものを拾って、GIF動画にすると、こんな感じになります。潜在変数Zの空間に連続的に数字が分布している感じが、この動画からも分かると思います。
VAE なかなか面白いですね。
次回は、オリジナルデータセットで再度VAEをやってみたいと思います。
では、また。













コメントを残す