
1.はじめに
NNC Challenge とは、SONYさんが開発したAI開発ツールNeural Network Consoleを使い、協賛企業が提供するデータを用いてディープラーニングに挑戦するAI開発コンテストで、今回が第2回目です。
今回の協賛企業は、映像制作・イベント・音効業務用のBGM・効果音などを販売しているAudiostockさんです。提供されるデータは、10,000点を超えるBGMデータで、2020.09.16 ~ 2020.10.19 の期間で開催されました。
そして今回のテーマは、A)AudiostockのBGM検索の自動分類アルゴリズムを作り出す、B)自由な発想で音声データを解析する(自由テーマ)、の2つの中から選ぶというもので、私も参加しましたのでチャレンジ内容を記します。
*学習用データ提供:Audiostock
2.Audiostockは何をやっている会社?
Audiostockは、音楽クリエイターからBGMや効果音などの作品を登録して貰いオンラインで著作権フリーの音楽として販売します。購入者は映像制作・イベント・音効業務などを行っている方です。販売が成立するとAudiostockは購入者から支払いを受け、作品を制作した音楽クリエイターに報酬を支払うというサービスを行っています。
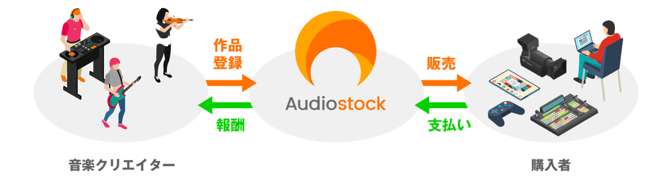
購入者にとっては、自分の必要とする音楽を著作権法を気にすることなく手軽に買えますし、音楽クリエイターにとっては、自分の作品を効率的に販売する機会が得られるというわけです。
現在、契約している音楽クリエイターは16千人、販売している音源は60万点で毎月1万点づつ増えているとのことです。
では、実際のオンライン販売のWebページを見てみましょう。どうやって自分の好みの曲を探すかと言うと、「長さ」,「用途」,「楽曲ジャンル」,「イメージ」,「メイン楽器」,「テンポ」,「ファイル形式」という各カテゴリでタグを指定をして、自分の探したい曲を絞り込んで探します。これ以外の方法もありますが、メインはこの方法の様です。
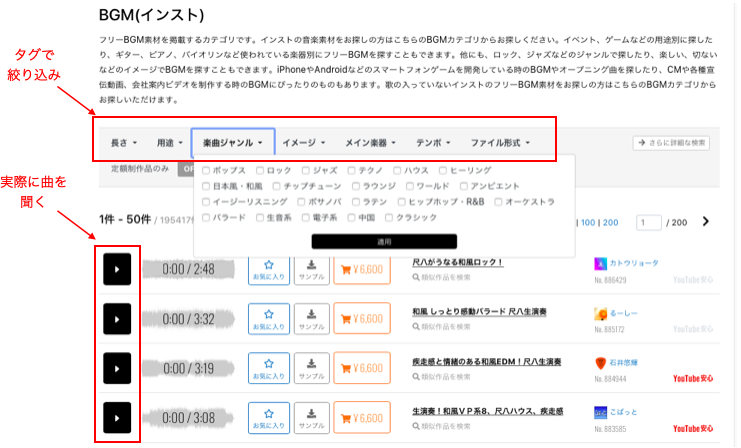
カテゴリをクリックするとタグの一覧(楽曲ジャンルだと「ポップス」〜「クラシック」まで21個のタグがあります)が表示されますので、好みのタグにチェックを入れて適用ボタンを押すと絞り込みが掛かります。
タグで絞り込んだ後は、1つ1つ曲を聞いて選ぶことになります。曲を聞くプロセスは上手く出来ていて、矢印上下キーを押すだけで次から次へとスムーズに曲が聞けますし、マウスで曲の任意の位置から再生できます。
※タグによる絞り込み検索の他に、タグと1行コメントを対象としてキーワード検索で曲を絞り込む方法もありますが、タグで選ぶのと本質的な違いは小さいです。
3.今回提供されたデータ
今回、Audiostockさんから提供されたデータは、以下の3つです。

02_rawdataは、BGMのフルサイズデータで10,802個(サンプルレート44.1KHz)あります。音質が良く聞いていて楽しいのですが、曲の長さはまちまちで全体の容量も200GB超えとそのままでは扱い難いです。
01_加工済みデータは、02_rawdataをコンパクトにしたもので、同じく10,802個あります。曲の長さを曲頭から24secで切り揃え、サンプルレートを8kHzにダウンサンプルすることで、全体の容量を3GB程度に抑えています。音質はあまり良くありませんが、ディープラーニングで使うには、こちらが良いでしょう。
BGMデータ一覧は、BGMの1行コメントやタグをまとめたもので、こんなイメージです。

音楽は画像と違いゼロからアノテーションするには相当時間が掛かるため、BGMデータ一覧は非常に貴重なデータです。そのため、主要カテゴリのタグ付け状況を見てみます。まず「用途」タグです。

1位はジングルで、CM、イベント、ゲーム、映画と続きます。1位のジングルは、番組の節目に挿入される短い音楽ですので、ジングルを探している場合は効果的な絞り込みが出来そうです。しかし、それ以外は曖昧な絞り込みになってしまいそうです。例えば映画と言っても様々なものがあるわけで、このタグで探している曲を効率的に絞り込めるかどうかはちょっと疑問です。タグ使用数は6,730件(重複使用なしで使用率62%)と思ったほど多くありません。
次に、「楽曲ジャンル」タグです。

1位はロックで、バラード、テクノ、ポップス、ワールドと続きます。5位のワールドは、世界の各地域の民族音楽の総称です。曲のジャンルだけの絞り込みなので、特殊なジャンルの絞り込みは別として、あくまでもサブ的なものだと思います。タグ使用数は5,185件(重複使用なしで使用率48%)と少な目です。
そして、「イメージ」タグです。

1位は軽快で、楽しい、明るい、優しい、わくわくと続きます。探している曲のイメージを自分なりの言葉にするのは簡単なので上手くハマれば効果的かもしれません。しかし、イメージは主観的なもので、例えば楽しいと思うか明るいと思うかは人それぞれと言う気がします。
最後に、「メイン楽器」タグです。

1位はシンセサーザーで、ピアノ、エレキギター、ストリング、パーカッションと続きます。このカテゴリのタグは使っている楽器を明示するものなので客観的なものだと思います。タグの使用合計は3,429件(重複使用なしで使用率32%)と一番少ないです。
タグについてまとめると、「用途」タグ・「楽曲」タグは絞り込み効果が薄く、「イメージ」タグは主観的なバラツキが多いように思います。「メイン楽器」は客観的なタグだと思います。
そして、的確なタグが付いていないと絞り込みの時にリストから外れてしまうにも関わらず、全体的にタグの使用率は低いです。重複使用がないとしても使用率は、「用途」タグで62%、「楽曲ジャンル」タグで48%、「メイン楽器」タグで32%です。
※全体的にタグの使用率が低い理由は、タグ付けはAidiostock事務局で行うのではなく原則音楽クリエイターに任されているので、クリエイターの方々のタグ付けのバラツキが影響しているかもしれません。但し、これは無理からぬことで、毎月1万点の新曲が追加される中では、事務局でのタグ編集は補助的なものにならざるを得ないと思います。
4.テーマ選定
自分が購入者だとしてAudiostockに会員登録(会員登録は無料です)し、実際に曲を選んでみることにしました。想定は、企業のプロモーションビデオを作成するとして、そのBGMを選ぶというものです。
「用途」タグはVP,企業VP、「楽曲ジャンル」タグはポップス、「イメージ」タグは疾走感,おしゃれ,軽快、「メイン楽器」タグはシンセサイザーでタグ付けして曲を絞り込むと、全部で730曲リストアップされます。

ここから1曲づつ曲を聞くわけですが、730曲を全部聞くのは現実的ではありません。なぜなら、選曲に1曲あたり平均10秒しか掛けなかったとしても2時間掛かるからです。曲を聞くのは画像を選ぶよりはるかに時間が掛かります。
そう考えると、タグで絞り込んで1曲づつ聞いて自分のイメージに大体合うような曲に出会ったら、絞り込んだ曲の中からその曲の類似曲検索が出来ると良いと思いました。
また、先程のBGMデータ一覧の分析から分かった、全体的にタグの使用率が低いことを考えると、タグの絞り込みで外れてしまった曲の中にも好みの曲がある可能性があります。その場合、リストから外れた曲の中から自分のイメージに大体合うような曲の類似曲検索をするのは効果的な手法だと思います。
そこで、今回のテーマは「類似曲検索」にすることにしました。
5.ラフスケッチを作る
テーマが決まったので、類似曲検索を実現するためのラフスケッチを作成します。
1) 波形データを画像に変換する
BGMの波形データをディープラーンングそのまま扱うこともできますが、波形の様な時系列データは処理に時間が掛かりやすいので、波形データの特徴を画像データに変換して扱うことにします。そのために、BGMの波形データをメル周波数スペクトログラムに変換することにします。

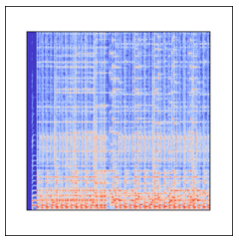
これがメル周波数スペクトログラムの例です。縦軸は周波数(Hz)、横軸は経過時間(sec)で、色は音圧レベル(db)を表します。メル周波数と言うのは、人間の聴覚特性に合うように周波数を調整したものです。つまり、サウンドの時系列変化を表す画像と言えます。
2) BGM分類器を作成する
クラス分けしたBGMの画像を入力し、CNNで重みを学習させます。最初はデタラメなクラスを出力しますが誤差逆伝播によって次第に正しいクラスを出力するようなネットワークの重みを学習します。
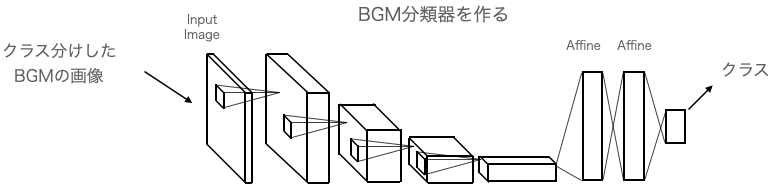
この結果、BGMを適切にクラス分けできるBGM分類器が出来ます。
3) BGMの特徴ベクトルを取得する
BGMの画像をBGM分類器に入力するとクラスが出力されますが、クラスは様々な処理を行った上での最終結果なので情報量が少ないです。それよりも、その前の全結合層(Affine)の方が圧倒的に情報量が豊富なので、ここから特徴ベクトルを取り出すことにします。

これによって、全てのBGMの画像を入力すると、全てのBGMの特徴ベクトルを取得出来るわけです。
4) 特徴ベクトルから類似曲を探す
2つのベクトルがどのくらい同じ方向を向いているかは、下記の式を使ってcos類似度を計算すれば求めることが出来ます。cos類似度は−1〜+1で表され、全く同じ方向を向いているとき+1になります。
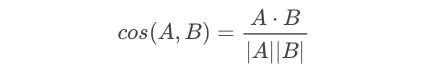
従って、類似曲を探したい曲の特徴ベクトルと他の曲の特徴ベクトルのCOS類似度を全て計算して結果をソートすれば、類似度が大きい順に曲が検索できるわけです。
これでラフスケッチが出来ましたので、後はこれに沿って具体的に進めて行きます。
6.波形データを画像に変換する
Pythonで音楽や音の分析に使用するパッケージlbrosaを使って、BGMの波形データをメル周波数スペクトログラムに変換します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import sys import numpy as np import librosa import matplotlib.pyplot as plt import scipy.io.wavfile import librosa.display import os def save_png(filename,soundpath,savepath): #音声ファイル読み込み wav_filename = soundpath+filename rate, data = scipy.io.wavfile.read(wav_filename) #16bitの音声ファイルのデータを-1から1に正規化 data = data / 32768 # フレーム長 fft_size = 1024 # フレームシフト長 hop_length = int(fft_size / 4) # 短時間フーリエ変換実行 amplitude = np.abs(librosa.core.stft(data, n_fft=fft_size, hop_length=hop_length)) # 振幅をデシベル単位に変換 log_power = librosa.core.amplitude_to_db(amplitude) # グラフ表示 plt.figure(figsize=(4, 4)) librosa.display.specshow(log_power, sr=rate, hop_length=hop_length) plt.savefig(savepath+filename + '.png',dpi=200) soundpath = './input/' savepath = './output/' cnt = 0 for filename in os.listdir(soundpath): cnt += 1 print(cnt,'件を処理しました', filename) save_png(filename,soundpath,savepath) plt.close() |
コードを実行すると、800×800ピクセルのpng画像が得られます。周辺に余白が出来るので、センターから600×600でクロップして224×224にリサイズします。
7.BGM分類器を作る
どうやってデータセットを作るかですが、ゼロからBGMを分類するのは大変過ぎるので、BGMデータ一覧表にあるタグをなんとか利用したいわけです。タグを頼りにする場合、「用途」や「楽曲ジャンル」は曖昧だし、「イメージ」は主観的です。客観的なのは「メイン楽器」だと思い、「メイン楽器」のタグを元に分類してみることにしました。

使用頻度が多いタグにフォーカスし、「パーカッション」の様にサウンドの主体にはならないものや「民族」の様にサウンドが多様なものは除外して、赤枠のタグが付いている曲だけを抽出します。その結果、シンセサイザー716曲、ピアノ596曲、エレキギター419曲、ストリングス282曲、アコースティックギター215曲、ブラスセクション177曲、シンセリード127曲をピックアップしました。後は、ひたすらピックアップした曲を聞いて分類を行いました。
例えば、シンセサイザーのタグが付いていても、あくまでもバッキングで使用しているだけでメインで使っているのはサックスだとか、確かに使っているが短時間しか使っていないとかいう様なものを省いて行きました(こういうのがかなり多いです)。最終的に、タグの統廃合も含めて「アコースティックギター」,「エレキギター」,「ピアノ」,「シンセサイザー」の4種類に分け各75曲づつ計300曲を選びました。
そして、先程説明した方法で、300曲の波形データを画像に変換します。そして、NNCでデータセットを作成します。
.png)
300個のデータは学習:評価=7:3で分割し、学習データ210個、テストデータ90個を作成しました。
ニューラルネットワークの設計については、コンテスト参加者の特典として事務局からNNCのcloud版のGPUを10,000円分使える権利を付与して頂いたので、心おきなくトライが出来ました。GPUだとCPUの20倍くらいのスピードで学習が出来るのでほとんどストレスなしで色々試せるのは、非常にありがたかったです。
色々トライした結果、学習データが210個と少ないせいでしょうか、コストパラメータは比較的小さなモデルの方が良い結果が出ました。

このモデルのコストパラメータは1,128,700で、CPUでも実用的に動くレベルです。
学習曲線(Learning Curve)です。
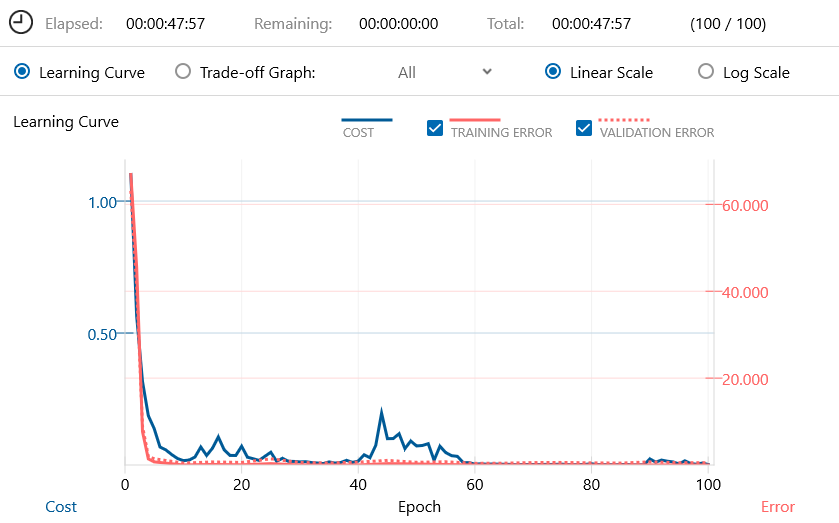
学習は、この後の処理を考えて、あえてNNC Windows版(CPU)を使って行い、100epochが48分で完了しました。検証エラー(VALIDATION ERROR)のbestは、60epoch時に0.530326です。
混同行列(Confusion Matrix)と精度です。
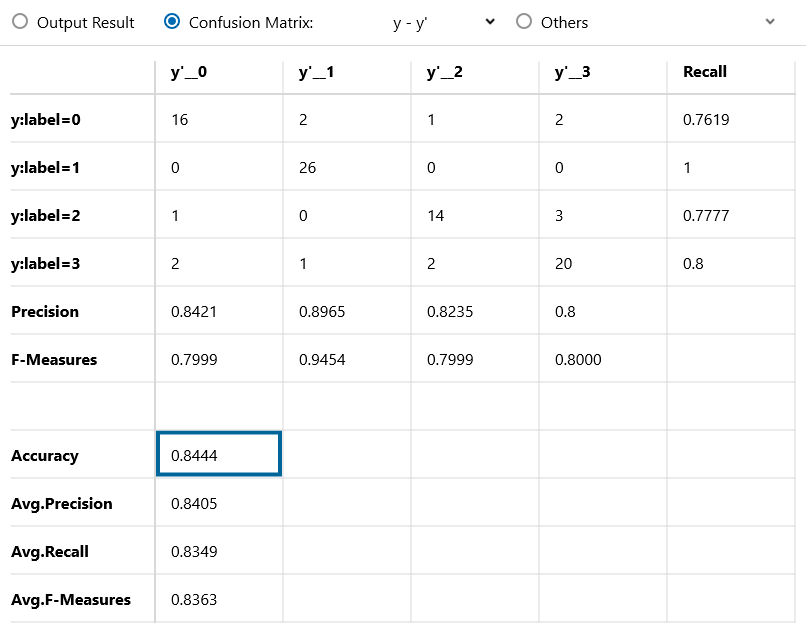
精度(Accuracy)は84.44%で、label毎のRecallも大きなバラツキはなく、まずまずの分類精度です。
8.BGMの特徴ベクトルを取得する
BGM分類器が出来ましたので、それを使って全てのBGMの特徴ベクトルを求めます。最初、結構複雑なことをしなければいけないのかなと思っていましたが、Neural Network Console (Windows版) は上手く作られています、「学習されたニューラルネットワークの途中出力を分析する」という機能があるのです。
まず、全てのBGMの波形を画像に変換してテストデータ(正解データはなんでも良い)を作成し、先程学習した時のテストデータと入れ替えておきます。
次に、途中結果出力用のネットワークを作成します。

基本的に学習用ネットワークのコピーですが、2つ目のAffineからIdentifyへの分岐接続を追加し、特徴ベクトルが取り出せるようにしています。
このネットワークを、EDITタブにActivationMonitorという名前で追加登録して、CONFIGのExecutorの指定もこのActivationMonitorに変更し、Global ConfigのMax Epochを0にします。
Open in EDIT Tab with Weight で学習済みニューラルネットワークを重み付きで読み込み学習を開始すると、Max Epochが0なので何もせず学習が完了します。そして評価を開始すれば、テストデータに登録された各画像の特徴ベクトルを、CSVファイル(output_result.csv)で出力してくれるんです。こんな風に小回りを効かせることが出来るなんて凄いです!
これが、CSVファイルのイメージです。Affineが100次元なので、特徴ベクトルも100次元になっています。

*エディター等で、y:labelとCategoricalCrossEntropyの列は削除し、x:imageの名称は簡略化したものを表示しています。
9.特徴ベクトルから類似曲を検索する
各BGMの特徴ベクトルをまとめたCSVファイルができましたので、Pythonを使って類似度TOP5の曲を検索します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import csv import numpy as np # 初期設定 N = 500 # 類似度を計算するindex (audiostock_43054を指定) # cos類似度計算関数 def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) # 特徴ベクトルをarrayに読み込む with open('./output_result.csv', 'r') as f: reader = csv.reader(f) h = next(reader) # ヘッダーをスキップ for i, line in enumerate(reader): if i == 0: array = np.array(line[1:], dtype=float) index = [line[0]] else: array = np.vstack([array,np.array(line[1:], dtype=float)]) index.append(line[0]) print('特徴ベクトル読み込み完了', array.shape) print('index読み込み完了', len(index)) # cos類似度計算 for i in range(len(array)): x = cos_sim(array[N], array[i]) if i == 0: score = x else: score = np.hstack([score,x]) print('cos類似度計算完了', score.shape) # TOP5のindex検索 for j in range(1,6): b = np.where(score==np.sort(score)[-j]) n = int(b[0]) print('TOP'+str(j), index[n][:16], 'score = '+str(score[n])) |

コードを実行すると、類似度が高い順に曲名が並びます。TOP1のaudiostock_43054は検索対象曲そのものです(なのでcos類似度は最大の1です)。TOP2以降を見ると、一番類似度が高いのは、audiostock_52175で類似度は0.9530となります。
それでは、色々な曲を対象に類似曲を検索してみます。
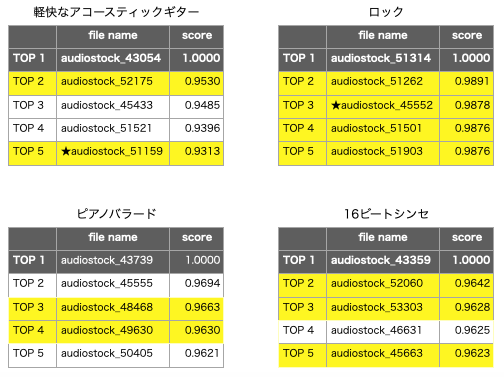
曲を4つピックアップして、TOP2〜TOP5の中にTOP1と類似の曲が含まれているかを実際に聞いて確認し、該当すると思われる曲を黄色でマーキングしてみました。
その結果16曲の内11曲が類似曲と判定でき、平均約7割くらいの精度で類似曲を検索できることが分かりました。そして、類似曲11曲中9曲はデータセットには無い曲で、類似曲検索が効果的に働いていることも分かりました。
特に、★印を付けた軽快なアコースティックギターのTOP5とかロックのTOP3は、正に狙い通りの類似曲だなーと思いました。
10.まとめ
今回のチャレンジで、BGMクラス分類器を使った類似曲検索は結構使えることが分かりました。現在の曲検索の方法に加えて、この手法を追加して使うことで膨大なBGMの中から効率的に自分の好みの曲を見つけることが出来ると思います。
また、Neural Network Consoleは「学習されたニューラルネットワークの途中出力を分析する」という、小回りが利く機能を持っていることを今回初めて知りました。Neural Network Console は痒いところに手が届く使いやすいAIツールなので、おすすめです。














コメントを残す