今回は、Google Colab で、Word Cloud を使ってテキストマイニングしてみます。
こんにちは cedro です。
皆さん Word Cloud をご存知ですか。文章を単語単位で出現頻度を調べ、出現頻度に応じて単語を、大きさ、色、向きに変化をつけて表示することで、文章の内容を1枚で印象的に見せるアレです。
ちょっと調べて見たら、Word Cloud はライブラリーになっていて、手軽に使えることが分かりました。
ということで、今回は、Google Colab で、Word Cloud を使ってテキストマイニングしてみます。
Google Colab の準備をします
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
Google Colab に接続します。ファイル/python3 の新しいノートブックを開いたら、ランタイム/ランタイムのタイプを変更でGPUを選択して保存します。そして、上記コマンドをコピペして動かします。
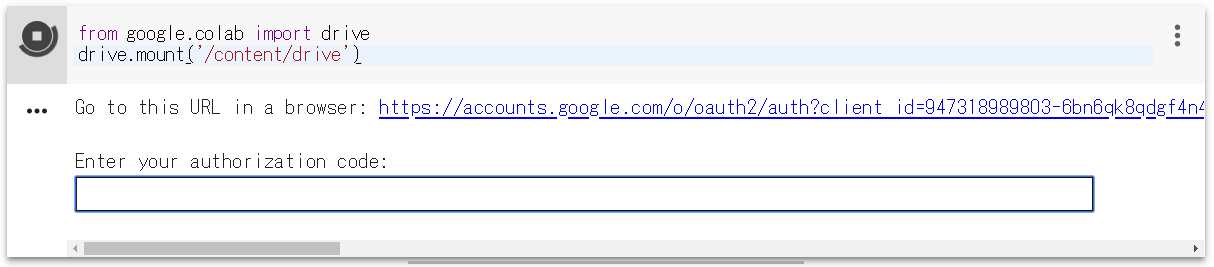
実行するとこんな表示が出ます。リンクをクリックし、アカウントを選択したら、authorization code が表示されるので、これを四角内にコピぺすれば、Googole Driveがマウントされます。
|
1 2 3 |
cd drive/My Drive !mkdir word_cloud cd word_cloud |
drive/My Drive にフォルダーに移動し、その下に今回テストするための word_cloud フォルダーを作成し、そこへ移動するコマンドです。 1行づつコピペして実行します。
|
1 |
!pip install janome |
日本語は英語の様に単語が分かれていないので、単語単位に分解するために、Janome をインストールします。コピペして実行します。

実行後、こんな表示が出ればOKです。
|
1 2 3 4 5 6 |
from janome.tokenizer import Tokenizer text = 'すももももももももものうち' t = Tokenizer() tokens = t.tokenize(text) for token in tokens: print(token) |
Janome がちゃんと動作するかどうか確認します。上記コードをコピペして実行します。

実行後は、こんな形になるはずです。分割した単語、品詞、読みなどの情報を返してくれます。
|
1 |
!apt-get -y install fonts-ipafont-gothic |
Google Colab には日本語の True Font が入っていないので、インストールします。このコマンドをコピペして実行します。

こんな表示が出ればOKです。
肝心の Word Cloud のライブラリーはインストールしないの?と思われるかもしれませんが、Google Colabには、デフォルトでWord Cloud がインストールされていますので、ご安心を。
テキストを準備します
今回は、青空文庫にある夏目漱石の「坊ちゃん」をテキストマイニングの題材にします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import re import zipfile import urllib.request import os.path,glob #ダウンロードしたいURLを入力する URL = 'https://www.aozora.gr.jp/cards/000148/files/752_ruby_2438.zip' def main(): download_text = download(URL) text = convert(download_text) print(text) with open('result.txt', 'w') as f: f.write(text) def convert(download_text): binarydata = open(download_text, 'rb').read() text = binarydata.decode('shift_jis') # ルビ、注釈などの除去 text = re.split(r'\-{5,}', text)[2] text = re.split(r'底本:', text)[0] text = re.sub(r'《.+?》', '', text) text = re.sub(r'[#.+?]', '', text) text = text.strip() return text def download(url): # データファイルをダウンロードする zip_file = re.split(r'/', url)[-1] if not os.path.exists(zip_file): print('Download URL') print('URL:',url) urllib.request.urlretrieve(url, zip_file) else: print('Download File exists') # フォルダの生成 dir, ext = os.path.splitext(zip_file) if not os.path.exists(dir): os.makedirs(dir) # zipファイルの展開 zip_obj = zipfile.ZipFile(zip_file, 'r') zip_obj.extractall(dir) zip_obj.close() # zipファイルの削除 os.remove(zip_file) # テキストファイルの抽出 path = os.path.join(dir,'*.txt') list = glob.glob(path) return list[0] if __name__ == "__main__": main() |
青空文庫から「坊ちゃん」をダウンロードし、テキスト(result.txt)を作成するコードです。ダウンロードするファイルは、7行目のURLで指定しています。
def download(url): は、zipファイルをダウンロードして解凍し、テキストファイルを抽出する関数です。def convert(download_text): は、ルビ、注釈など余分なものが省く関数です。
上記コードをコピペして実行します。
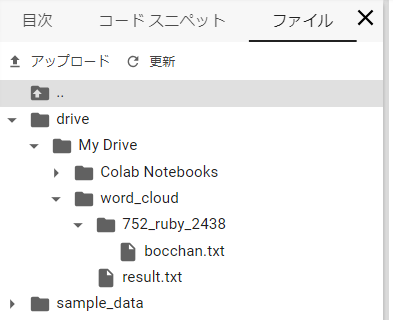
ここまでで、フォルダー構成はこんな形になるはずです。
今回は、青空文庫から小説(zip)をダウンロードして来るので、上記の様な処理を行いますが、result.txt はいわゆるテキストファイルであれば良いわけです。
自分で用意した文章を使いたい場合は、エディターで余分なタグを削除し、文字コードをUTF-8にして、result.txt というファイル名で、word_cloud フォルダーの直下に保存してもOKです。
Word Cloud を実行します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
from janome.tokenizer import Tokenizer from wordcloud import WordCloud import matplotlib.pyplot as plt text_file = open("result.txt") full_text = text_file.read() full_text= full_text.replace("\n","") print(full_text) t = Tokenizer() tokens = t.tokenize(full_text) word_list=[] for token in tokens: word = token.surface partOfSpeech = token.part_of_speech.split(',')[0] partOfSpeech2 = token.part_of_speech.split(',')[1] if partOfSpeech == "名詞": if (partOfSpeech2 != "非自立") and (partOfSpeech2 != "代名詞") and (partOfSpeech2 != "数"): word_list.append(word) words_wakati=" ".join(word_list) print(words_wakati) stop_words = ['さん','そう'] fpath = '/usr/share/fonts/truetype/fonts-japanese-gothic.ttf' # 日本語フォント指定 wordcloud = WordCloud( font_path=fpath, width=900, height=600, # default width=400, height=200 background_color="white", # default=”black” stopwords=set(stop_words), max_words=500, # default=200 min_font_size=4, #default=4 collocations = False #default = True ).generate(words_wakati) plt.figure(figsize=(15,12)) plt.imshow(wordcloud) plt.axis("off") plt.savefig("word_cloud.png") plt.show() |
result.txt をJanome で単語単位に分割し、必要な単語だけ抜き出し、Word Cloud を実行するコードです。
14-25行目で、単語単位に分割し、名詞(但し、非自立・代名詞・数を除く)のみを対象に抜き出し、words_wakati (単語が空白で区切られ改行コードはない状態)に保存しています。
27行目の stop_words = [‘さん’,’そう’] は、Word Cloud に表示させたくない単語がある場合、ここにリスト形式で記載しておきます。
28行目の fpath = ‘/usr/share/fonts/truetype/fonts-japanese-gothic.ttf’ は、先程インストールしたTrue Font の指定です。
30−39行目が、Word Cloud の肝の部分です。引数は何かはコードをみて頂ければ分かると思います。参考に、# default 値を記載してあります。
Word Cloud で作成された画像は、Google Colab のインラインに表示すると共に、word_cloud フォルダー直下に、word_cloud.png という名称で保存されます。
では、コードを実行します。

word_cloud.png です。「シャツ」がひときわ大きくフューチャーされていますね。

これは、Oヘンリーの短編小説「賢者の贈り物」をWord Cloud したものです。
「賢者の贈り物」のページのソースを表示させて(Chromeなら文章の上で右クリックで選択できます)コピーし、余分なHTMLタグをエディターでちょいちょいと削除して、作成したテキストを result.txt で保存し、Word Cloud を実行しています。
これを見ると、長編小説よりも短編小説の方が使っている単語にメリハリがあるせいか、より物語を印象付けてくれる様な気がします。
Word Cloud、これ知っていると色々な場面で使えそうですね。
最後に、今回お世話になった方々のリンクを記載しておきます。「青空文庫からPythonで本文を取得したい」、「データ解析、プログラミング学習中」。ありがとうございました。
では、また。














お世話になります。
非常に分かり易くて参考になる記事です。お陰様で日本語のWordcloud一発で作成することが出来て大変感謝しております。
一点だけを確認させて下さい。本記事に搭載されたPythonコードはGitHubのMIT Licenseと同様の扱いと考えられても宜しいでしょうか?つまり、本コードを利用し手元にある文章からWordcloudを作成し、コマーシャル目的(会社のブログ記事)等が許されるかどうか確認したいと思います。勿論、こちらの記事リンクをちゃんと載せます。
何卒、宜しくお願い致します。
Andrewさん
コメントありがとうございます。
おっしゃる通り、MIT License 同等でOKです。
cedroさん、
ご回答、ありがとうございました。
無駄せずに使わせて頂きます 🙂