
1.はじめに
今回ご紹介するのは、Transfomer ベースの予測ネットワークを使うことによって、低画質の顔画像を高画質化する CodeFormer という技術です。
*この論文は、2022.6に提出されました。
2.CodeFomerとは?
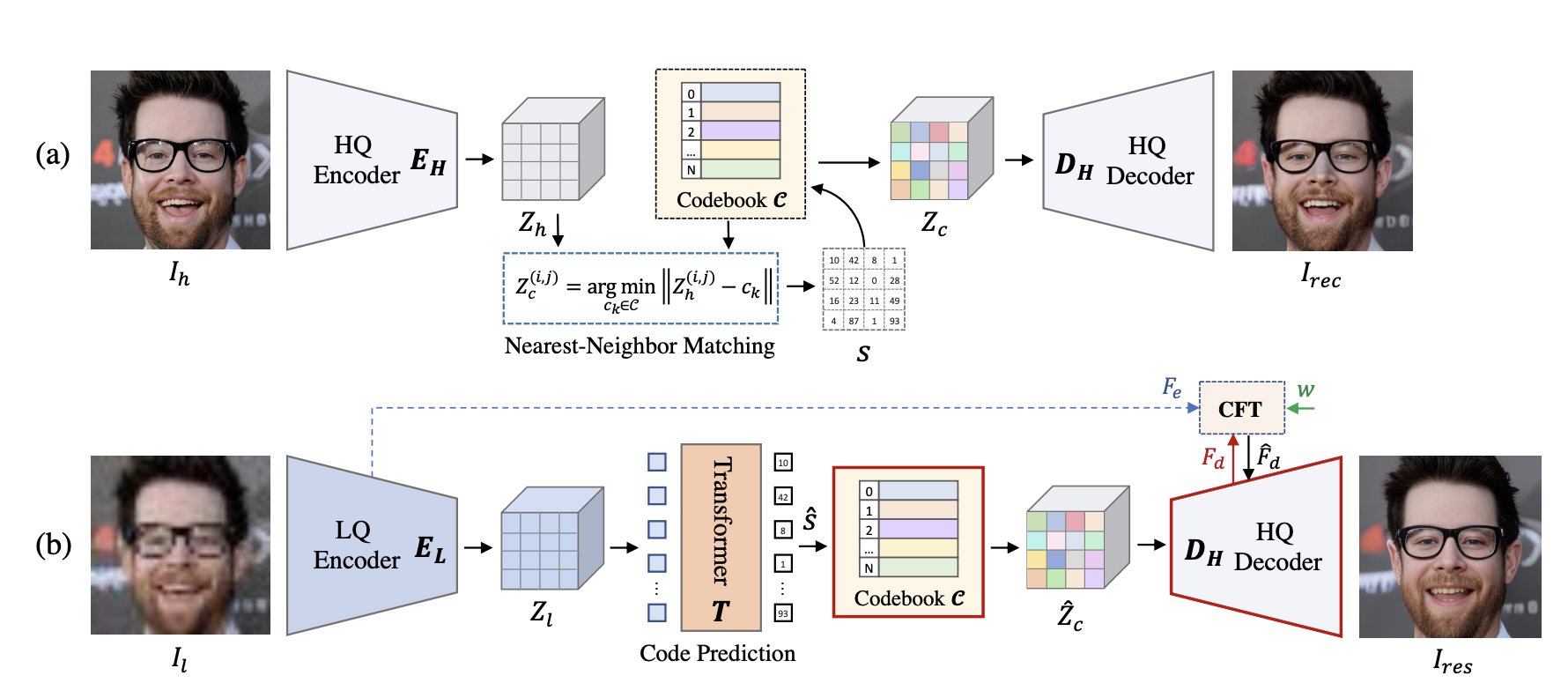
下記は、CodeFormerの概要図で、2段階で学習を行います。まず、(a)自己再構成学習を行います。高画質画像(Ih)から高画質エンコーダー(HQ Encoder)を通して画像特徴量(Zh)を抽出し、ニアレストネイバー法(Nearest-Neighbor Matching)で離散コードブック(Codebook C)にマッピングし、デコーダー(HQ Decoder)で高画質画像に戻すことを学習します。ここで学習した離散コードブック以降は次で使用します。
次に、(b)最終的なネットワークの学習を行います。低画質画像(IL)から低画質エンコーダー(LQ Encoder)を通して画像特徴量(ZL)を抽出します。ここで、Transformer による予測ネットワーク(Code Prediction)を使って、先程学習した離散コードブック以降に接続して学習するのがミソです。さらに、CFT で低画質エンコーダーからデコーダーへ流す情報を重み w で調整することによって画像品質と忠実度のトレードオフを調整することができます。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#@title **セットアップ** # Clone CodeFormer and enter the CodeFormer folder %cd /content !rm -rf CodeFormer !git clone https://github.com/cedro3/CodeFormer.git %cd CodeFormer # Set up the environment # Install python dependencies !pip install -r requirements.txt # Install basicsr !python basicsr/setup.py develop # Download the pre-trained model !python scripts/download_pretrained_models.py facelib !python scripts/download_pretrained_models.py CodeFormer # Visualization function import cv2 import matplotlib.pyplot as plt def display(img1, img2): fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 2, 1) plt.title('Input', fontsize=16) ax1.axis('off') ax2 = fig.add_subplot(1, 2, 2) plt.title('CodeFormer', fontsize=16) ax2.axis('off') ax1.imshow(img1) ax2.imshow(img2) def imread(img_path): img = cv2.imread(img_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) return img # display result from IPython.display import clear_output import os import glob def display_result(input_folder, result_folder): input_list = sorted(glob.glob(os.path.join(input_folder, '*'))) for input_path in input_list: img_input = imread(input_path) basename = os.path.splitext(os.path.basename(input_path))[0] output_path = os.path.join(result_folder, basename+'.png') img_output = imread(output_path) display(img_input, img_output) # reset_folder import shutil def reset_folder(path): if os.path.isdir(path): shutil.rmtree(path) os.makedirs(path,exist_ok=True) |
最初に、inference_codeformer.py を使用し、引数に–has_aligned を加えてクロップした顔を高画質化してみます。入力画像は、inputs/cropped_faces フォルダに入っているものを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 |
#@title **クロップした顔のデモ** input_folder = 'inputs/cropped_faces' w = 0.7 #@param {type:"slider", min:0.1, max:0.9, step:0.1} ! python inference_codeformer.py --w $w\ --test_path $input_folder\ --has_aligned clear_output() result_folder = 'results/cropped_faces_'+str(w)+'/restored_faces' display_result(input_folder, result_folder ) |





最初の5枚のみ表示しています。
次に、inference_codeformer.py を使用し、引数に–bg_upsampler realesrgan を加えて背景も含めて画像全体を高画質化してみます。入力画像は、inputs/whole_imgs フォルダに入っているものを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#@title **画像全体のデモ** input_folder = 'inputs/whole_imgs' w = 0.7 #@param {type:"slider", min:0.1, max:0.9, step:0.1} ! python inference_codeformer.py --w $w\ --test_path $input_folder\ --bg_upsampler realesrgan clear_output() result_folder = 'results/whole_imgs_'+str(w)+'/final_results' display_result(input_folder, result_folder ) |





最初の5枚のみ表示しています。
それでは、オリジナル画像でやってみましょう。picフォルダに自分の用意した画像をアップロードして下さい。そして、picにファイル名を1つ指定して実行します。とりあえず、picフォルダには、01.jpg〜04.jpgまで4枚の画像がサンプルとして入っていますので、このサンプルで動かしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#@title **画像全体オリジナル** import os import shutil from PIL import Image pic ='01.jpg'#@param {type:"string"} input_folder = 'inputs/whole_imgs_original' reset_folder(input_folder) im = Image.open('pic/'+pic) im.save(input_folder+'/'+os.path.splitext(pic)[0]+'.png') w = 0.7 #@param {type:"slider", min:0.1, max:0.9, step:0.1} ! python inference_codeformer.py --w $w\ --test_path $input_folder\ --bg_upsampler realesrgan\ --face_upsample clear_output() result_folder = 'results/whole_imgs_original_'+str(w)+'/final_results' display_result(input_folder, result_folder ) |

下記を実行すると高画質化した画像をダウンロードします。
|
1 2 3 4 |
#@title **ダウンロード** #@markdown -google chrome 専用 from google.colab import files files.download(result_folder+'/'+os.path.splitext(pic)[0]+'.png') |
picを02.jpg〜04.jpgに変更し、同様に実行してみます。



従来のGANを使用する方法より安定した高画質化が出来ている様です。また、現在 HuggingFace でこの機能をWeb UIで簡単に試すことが出来ます。
では、また。
(オリジナルgithub)https://github.com/sczhou/CodeFormer
2022.9.23 動画版Colabの追加
動画(音声付き)を一旦フレームにバラして、フレーム毎に高画質化して、動画にまとめるコードのリンクを追加します。1秒間の動画(30フレーム)を高画質化するのに1分程度かかるので短い動画でお試し下さい。
2022.11.21 白黒動画版Colabの追加
白黒動画(音声付き)を高画質化し、さらにカラー化(DeOldify)するColabをのリンク追加します。1秒間の動画(30フレーム)を高画質化するのに1分程度かかるので短い動画でお試し下さい。
(twitter投稿)













このブログでAIに興味を持ち、いつも勉強させていただいています。
動画版Colabのソースコードを拝見し、参考にしながら、自分のPCでローカル構築してみました。おかげさまで稼働はするのですが、1点わからない箇所があり、ご教授いただければ幸いです。
「動画の読み込み」1分1800フレームの制限を外すには、どのファイルのどこをどのように修正したらいいのでしょうか?
よろしくお願いいたします。
ふぃあさん
ローカル構築さすがです!
「動画の読み込み」1分1800フレームの制限は、function.py の50行にある、length = 1800 の値を修正して下さい。
早々の返信ありがとうございます。
早速、function.pyを修正して試したらできました。
お手数おかけしました。ありがとうございます。
いつもこちらのブログで勉強させていただいております。
さて、基本的な質問で恐縮ですが「pic」フォルダはどちらにありますでしょうか。
すべてのフォルダを見たのですが見つからず、、、よろしくお願いいたします。
picフォルダは、下記です。
https://github.com/cedro3/CodeFormer/blob/a61a6ee1b3d049c8f308fc8c4e87c0c00880880a/assets/pic_folder.png