
1.はじめに
今回ご紹介するのは、文から動画を生成するモデル(txt2mov)の最新技術AnimateDiffです。この技術の特徴は、ベースモデルで一度学習すれば、ベースモデルからDreamBoothやLoRAなどで作った派生モデルに学習なしで適用できることです。
*この論文は、2023.7に提出されました。
2.AnimateDiffとは?
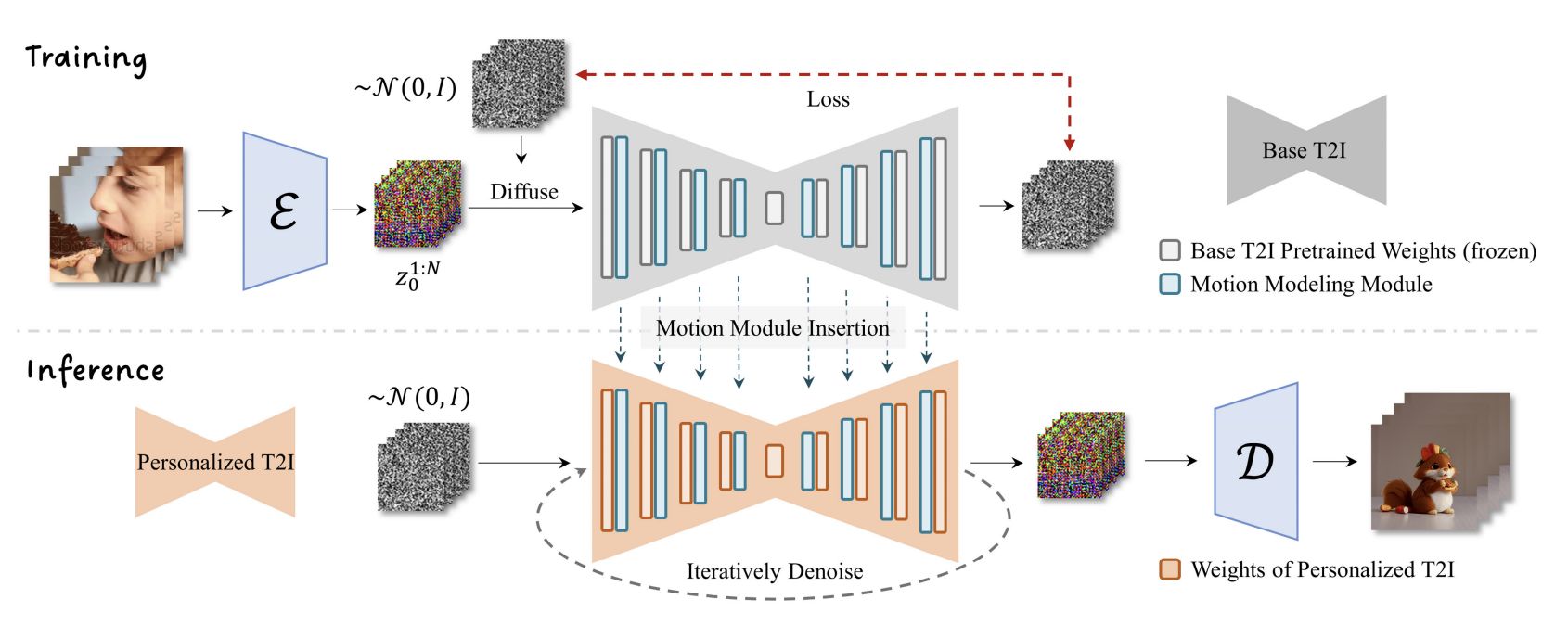
下記は、AnimateDiffの概略図です。上段がTraining(学習時)です。ベースモデルの各レイヤーに Motion Moduleを挟み込み、ベースモデルのパラメータはフリーズさせて、Motion Moduleのパラメータのみをビデオデータセットで学習させます。
下段がInference(推論時)です。ベースモデルからDreamBoothやLoRAなどで作った派生モデルの各レイヤーに学習済みのMotion Moduleを挟み込み、推論させます。このときモデルのファインチューニングなどは全く必要がありません。
3.コード
オリジナルのgithubとは別に、camenduru氏が作成したgoogle colabが使い易かったので、ここではそれを紹介します。この[リンク]をクリックすると、そのgoogle colabが開けます。
まず、セットアップを行います。派生モデルは、デフォルトでは、toonyou_beta3.safetensorsを読み込むようになっています。その他のモデルを読み込む場合は適宜コメントアウト(#)を設定し直して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
!git clone -b v1.1 https://github.com/camenduru/animatediff !pip install omegaconf einops omegaconf safetensors diffusers[torch]==0.11.1 transformers xformers==0.0.20 triton==2.0.0 !apt -y install -qq aria2 !rm -rf /content/animatediff/models/StableDiffusion !git clone -b fp16 https://huggingface.co/runwayml/stable-diffusion-v1-5 /content/animatediff/models/StableDiffusion/ !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/mm_sd_v14.ckpt -d /content/animatediff/models/Motion_Module -o mm_sd_v14.ckpt !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/mm_sd_v15.ckpt -d /content/animatediff/models/Motion_Module -o mm_sd_v15.ckpt !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/toonyou_beta3.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o toonyou_beta3.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/CounterfeitV30_v30.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o CounterfeitV30_v30.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/FilmVelvia2.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o FilmVelvia2.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/Pyramid%20lora_Ghibli_n3.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o Pyramid%20lora_Ghibli_n3.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/TUSUN.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o TUSUN.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/lyriel_v16.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o lyriel_v16.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/majicmixRealistic_v5Preview.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o majicmixRealistic_v5Preview.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/moonfilm_filmGrain10.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o moonfilm_filmGrain10.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/moonfilm_reality20.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o moonfilm_reality20.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/rcnzCartoon3d_v10.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o rcnzCartoon3d_v10.safetensors # !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateDiff/resolve/main/realisticVisionV40_v20Novae.safetensors -d /content/animatediff/models/DreamBooth_LoRA -o realisticVisionV40_v20Novae.safetensors |
文から動画を作成する指示は、configs/prompts/*.yamlファイルで設定する形になっています。ここでは、1-ToonYou.yamlの設定を見ておきましょう。prompt(プロンプト)とn_prompt(ネガティブ・プロンプト)など、必要な内容が4つ記入されています。自分の設定でやりたい場合は、このフォーマットで作成すればOKです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ToonYou: base: "" path: "models/DreamBooth_LoRA/toonyou_beta3.safetensors" motion_module: - "models/Motion_Module/mm_sd_v14.ckpt" - "models/Motion_Module/mm_sd_v15.ckpt" seed: [10788741199826055526, 6520604954829636163, 6519455744612555650, 16372571278361863751] steps: 25 guidance_scale: 7.5 prompt: - "best quality, masterpiece, 1girl, looking at viewer, blurry background, upper body, contemporary, dress" - "masterpiece, best quality, 1girl, solo, cherry blossoms, hanami, pink flower, white flower, spring season, wisteria, petals, flower, plum blossoms, outdoors, falling petals, white hair, black eyes," - "best quality, masterpiece, 1boy, formal, abstract, looking at viewer, masculine, marble pattern" - "best quality, masterpiece, 1girl, cloudy sky, dandelion, contrapposto, alternate hairstyle," : - "" - "badhandv4,easynegative,ng_deepnegative_v1_75t,verybadimagenegative_v1.3, bad-artist, bad_prompt_version2-neg, teeth" - "" - "" |
それでは文から動画を作成してみましょう。デフォルトでは、1-ToonYou.yamlを読み込むようになっています。その他の指示を読み込む場合は適宜コメントアウト(#)を設定し直して下さい。
|
1 2 3 4 5 6 7 8 9 |
%cd /content/animatediff !python -m scripts.animate --config /content/animatediff/configs/prompts/1-ToonYou.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/2-Lyriel.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/3-RcnzCartoon.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/4-MajicMix.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/5-RealisticVision.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/6-Tusun.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/7-FilmVelvia.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 # !python -m scripts.animate --config /content/animatediff/configs/prompts/8-GhibliBackground.yaml --pretrained_model_path /content/animatediff/models/StableDiffusion --L 16 --W 512 --H 512 |
動作が完了すると、samplesフォルダにGIF動画が作成されます。
0.”best quality, masterpiece, 1girl, looking at viewer, blurry background, upper body, contemporary, dress”

1.”masterpiece, best quality, 1girl, solo, cherry blossoms, hanami, pink flower, white flower, spring season, wisteria, petals, flower, plum blossoms, outdoors, falling petals, white hair, black eyes,”

2.”best quality, masterpiece, 1boy, formal, abstract, looking at viewer, masculine, marble pattern”

3.”best quality, masterpiece, 1girl, cloudy sky, dandelion, contrapposto, alternate hairstyle,”

動画品質はかなり良いです。また、今までのtxt2movは数を打って、その中から良いものを拾う必要がありましたが、この技術は歩留まりが信じられないほど高いです。技術は確実に進歩していますね。
(オリジナルgithub)https://github.com/guoyww/AnimateDiff
(twitter投稿)













コメントを残す