
今回のテーマは女性の顔画像の生成です
こんにちはcedroです。
なにげなく、SONY Neural Network Consoleのサンプルプロジェクト名を見ていると、mnist_dcgan_with_label.sdcproj というのを見つけました。
これって画像を生成する「DCGAN」じゃない? 最近、ディープラーニングについてWebで色々と情報収集しているので、気づきました。
しかし、先頭にmnistと書いてあるということは、例の0~9の数字が使われているということだよね。それと画像生成とどういう関係が?
あまりピンと来なかったのですが、とりあえずサンプルを動かしてみようと思い、学習ボタンを押しました。そしたら、ビックリ。
動作が死ぬほど遅い!
1epoch学習するのに、7分くらい掛かるのです。ということは100epoch学習させるのには。。。。約12時間。
複雑なネットワークだとすると、MNISTの0~9の数字の学習データは60000個もあるので、しょうがないのかもしれないですが。。。
早々とあきらめて学習停止ボタンを押しました。
私は、当然ながらNVIDIAのGPUなど持っていないわけで、さてどうしようかと考えた結果、別の方法で学習速度を100倍早くすることにしました。
どうするかって? 学習データ量を1/100にすれば、学習スピードは100倍になります。
具体的には、サンプルプロジェクトの学習ファイルは60001行のCSVファイルになっているので、602行以降を削除すればOKです。(ちなみに行削除にEXCELは不可です。OpenOfficeのcalcを使って下さいね)。
早速、学習・評価します。何をやっているか分かればいいだけなので、学習は50epochだけ。

0~9の画像を元にオリジナルの0~9の画像を生成しているんですね。なんて地味な企画なんだ。
せっかく画像を生成するなら、もっと写真のようなものが良いのに。。。。
というわけで、今回はこのサンプルプロジェクトを流用して、女性の顔画像の生成をやってみることにします。
DCGANって何?
DCGAN(Deep Convolutional Generative Adversarial Network)は、2015年にRadford et alが考案した高解像度画像の生成モデルで、ポイントはGeneratorとDiscriminatorという2つのネットワーク構成です。
Generatorは訓練データと同じようなデータを生成しようとします。一方、Discriminatorはデータが訓練データから来たものか、それとも生成モデルから来たものかを識別します。
この関係は、偽札偽造者と警察の関係と似ています。偽札偽造者は何とかして警察に見破られない偽札を作ろうする一方で、警察はどんな偽札でも見破ろうとします。
この両者の切磋琢磨のループによって、Generatorは最終的に訓練データと見分けのつかないレベルのデータが生成できるようになるわけです。
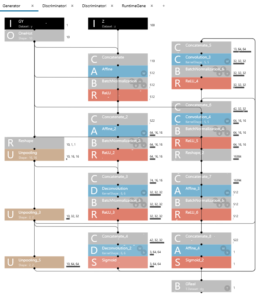
さて、今回流用するサンプルプロジェクトのネットワーク構成をみてみましょう。
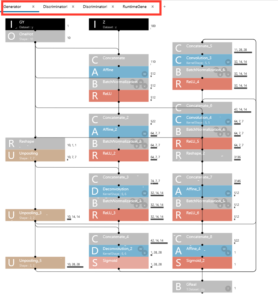
2015年に考案されたばかりの新しいモデルにしては、思ったほど複雑ではないなあと思うでしょ。私も最初そう思いました。
ところがこれネットワーク構成の一部なんです!
赤で囲まれた部分を見て下さい、全部で4画面(Generator、Discriminator×2、RutimeGene)あるんです。
データ収集・加工 & ネットワーク構成
今回使うのは、先回の「女性の顔のクラス分類」で使ったデータを流用します。
ただ、32×32ピクセルに加工したものではちょっと小さいので、収集した元画像を例の「縮小専用」アプリを使って64×64ピクセルに加工したものを使うことにします。
前回同様、C:直下にSNNC40フォルダーを作り、その下にSourceとOutputを作り、Sourceの中にface0、face1、face2、face3の各フォルダーを格納しておきます。
SONY Neural Network Console を起動し、「DATASET」タブを選択して、「+Create Dataset」ボタンを押します。
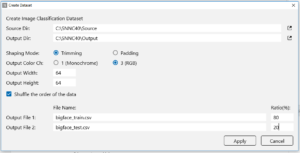
ポップアップ画面に必要な項目を入力し、「Apply」ボタンを押すと、学習ファイル(bigface_train.csv)と評価ファイル(bigface_test.csv)が作成されます。
「PROJECT」画面にします。mnist_dcgan_with_label.sdcproj をクリック。
save asで、先程作成したOutputに適当なファイル名(私は、bigface_dcgan_with_label.sdcprojとしました)でセーブします。
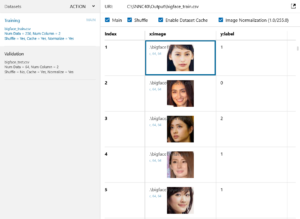
「DATASET」画面にします。プロジェクトのTrainingをbigface_train.csvに、Validationをbigface_test.csvに入れ替えます。
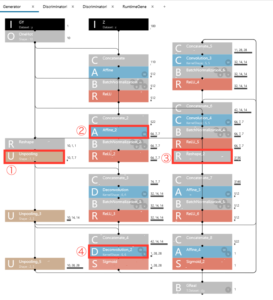
「EDIT」画面にします。画像入出力に関係するパラメーターのみ変更します。
① U(Unpooling): 10,7,7 → 10,16,16 に変更 (kenelShape 8,8 → 16,16)
② A(Affine‗2): 64,7,7 → 64,16,16 に変更
③ R(Reshape_2): 3136 → 16384 に変更 ( 64×16×16=16384 )
④D(Deconvolution‗2):1,28,28 → 3,64,64 に変更 (OutMaps 1 → 3)
①~④を変更すると、他に関係する部分は自動的に変更され、こうなります。
これと同様な感じで、他の画面も変更します(間違えたらエラーが表示されますのですぐ分かります)。
実際に顔画像を生成してみる
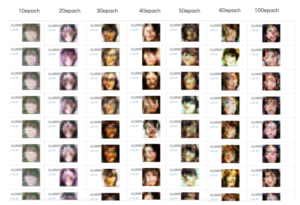
さて、生成された画像が、epoch数(学習回数)によってどう変化するのかまとめてみました。
データ数が320個とチョー少ないため、生成画像はまだ心霊写真の領域を出ていません(笑)。
かなり目を細めてみると、30~50epochあたりに、なんとなく顔らしきものがあるかなーという感じです。
そこからは大きな変化はなく、100epochまで行くと逆に潰れて行く感じしょうか。
まあ、まず一通りやってみることに価値があるといういつものノリなので、ご容赦下さい。
生成って刺激的なテーマ
今まで、ディープラーニングで画像の分類に関して色々やってみたのですが、やっぱり新たなものを生み出す「生成」というのは刺激的なテーマです。
ラベルや数字が出力されるより、絵が出たほうが面白いに決まっていますよね。
今回、心霊写真レベルとはいえ、自分のオリジナルデータで画像を生成したことに大変満足です。
なんか、これにはまっちゃいそうな気がしています。
うーん、でも画像をちゃんとやろうとすると学習データを大量に集める必要がある。
そうすると、Pythonを使った画像収集(クローリングとか、スクレイピングとか)や加工(顔の切り取りとか)ができないとなー。
Pythonはイヤだイヤだと言わず、学習データを作る部分だけ、Pythonを勉強してみようかなー。
てなことを最近考えています。
では、また。












いつもお世話になります。
最近、やっとGAN(敵対的生成ネットワーク)を始めました。Tensorflowでは例題コードでなんとか実行できています。
ちょうどSony NN ConsoleにDCGANの例題あってうれしかったのですが、残念ながら例題ネットワークを見てもその機能が理解できていません。
お手数をかけますが、その例題ネットワークの解説記事を書いていただけますか?
ここを訪れる読者はもちろん、世界のSony NN Consoleユーザーにも大変役に立つと思います。
お手数をかけますが、ご検討をよろしくお願いします。
Choe さん
いつもお世話になります。
SONY NN Console のDCGANについては、2018.1.4のブログ「顔画像生成に再びトライ」の後半で少し解説していますので、まずそれをご覧になって下さい。
ご参考になれば幸いです。