
今回は、安定した学習を可能にしたLSGANを試してみます
こんにちは cedro です。
私が、ディープラーニングの中で一番好きなのは生成系。中でも、単なるノイズから本物の様な画像を生成するGANは大好物です。
特に、最初何も存在しない画像から、少しづつ本物に近い画像に変化して行くプロセスを見るのが好き。
但し、DCGANは色々やってみましたが、大きな画像になると直ぐ mode collapse (生成が途中で失敗し砂嵐に戻る)になってしまい、パラメータ設定が微妙で学習が安定しないのが難点でした。
今回、例のハンドブックの第6章には、安定した学習を可能にしたLSGANというのが載っていたので、早速試してみたくなりました。
ということで、今回は、安定した学習を可能にしたLSGANを試してみます。
GANのお勉強
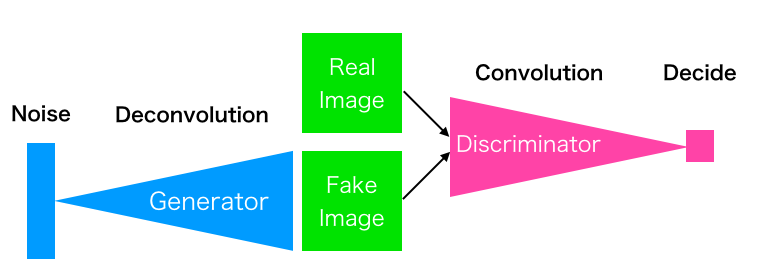
これは GAN の模式図です。Generator は Noise (乱数)を入力として、Discriminator に本物と間違わせるような偽物を作成することを学習します。
一方、Discriminator は本物と偽物を間違えないように学習します。この2つのネットワークが切磋琢磨することで高度な画像生成ができる様になります。
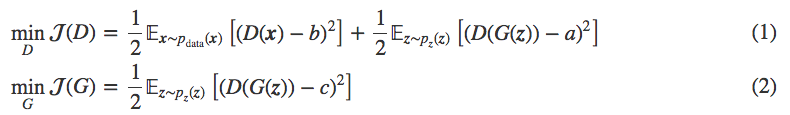
LSGANの論文に出て来る目的関数です。a,b,cは定数で、論文ではa,b,c=−1,1,0 または a,b,c=0,1,1 が推奨されていて、ハンドブックではa,b,c=0,1,1 の方が使われています。
式(1)も(2)も最小化することが目的です。それにはどうすれば良いかと言うと、式(1)のDiscriminatorの方は D(x) が1、D(G(z)) が0になれば良い。式(2)のGeneratorの方はD(G(z))が1になれば良い。
言い換えると、Discriminator は自らが本物を本物と判断し偽物を偽物と判断することが目標となり、Generator は Discriminator が偽物を本物と間違えることが目標になります。
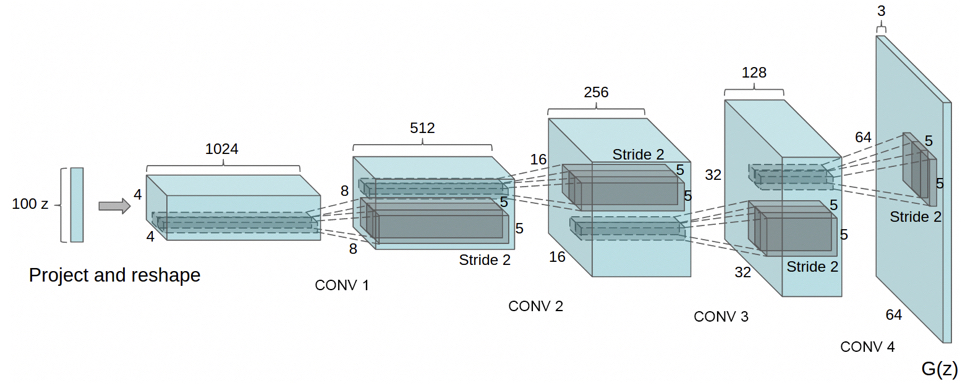
これは、DCGANの論文に載っている Generator のネットワークです。100次元ベクトルを入力に、 1024×4×4 → 512×8×8 → 256×16×16 → 128×32×32 → 3×64×64と転置畳み込みを行います。その結果、3×64×64のフェイク画像を生成します。
Discriminator は基本的にこの逆で、3×64×64のフェイク画像や実画像を入力に、128×32×32 → 256×16×16 → 512×8×8 → 1026×4×4 → 1×1×1と畳み込みを行います。その結果、1×1×1の判定結果を出力します。
コードを書きます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
class Generator(nn.Module): def __init__(self, nz=100, nch_g=64, nch=3): super(Generator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.ConvTranspose2d(nz, nch_g * 8, 4, 1, 0), nn.BatchNorm2d(nch_g * 8), nn.ReLU() ), # (100, 1, 1) -> (512, 4, 4) 'layer1': nn.Sequential( nn.ConvTranspose2d(nch_g * 8, nch_g * 4, 4, 2, 1), nn.BatchNorm2d(nch_g * 4), nn.ReLU() ), # (512, 4, 4) -> (256, 8, 8) 'layer2': nn.Sequential( nn.ConvTranspose2d(nch_g * 4, nch_g * 2, 4, 2, 1), nn.BatchNorm2d(nch_g * 2), nn.ReLU() ), # (256, 8, 8) -> (128, 16, 16) 'layer3': nn.Sequential( nn.ConvTranspose2d(nch_g * 2, nch_g, 4, 2, 1), nn.BatchNorm2d(nch_g), nn.ReLU() ), # (128, 16, 16) -> (64, 32, 32) 'layer4': nn.Sequential( nn.ConvTranspose2d(nch_g, nch, 4, 2, 1), nn.Tanh() ) # (64, 32, 32) -> (3, 64, 64) }) def forward(self, z): for layer in self.layers.values(): z = layer(z) return z |
Generator のコードです。論文のままのスペックだと重量級になり、GPUを使っても学習にかなり時間が掛かるので、入出力以外のチャンネル数は半減しています。
GANの安定化にはなくてはならないのが Batch_Normalization で、これは Generator と Discriminator の両方に入っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class Discriminator(nn.Module): def __init__(self, nch=3, nch_d=64): super(Discriminator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.Conv2d(nch, nch_d, 4, 2, 1), nn.LeakyReLU(negative_slope=0.2) ), # (3, 64, 64) -> (64, 32, 32) 'layer1': nn.Sequential( nn.Conv2d(nch_d, nch_d * 2, 4, 2, 1), nn.BatchNorm2d(nch_d * 2), nn.LeakyReLU(negative_slope=0.2) ), # (64, 32, 32) -> (128, 16, 16) 'layer2': nn.Sequential( nn.Conv2d(nch_d * 2, nch_d * 4, 4, 2, 1), nn.BatchNorm2d(nch_d * 4), nn.LeakyReLU(negative_slope=0.2) ), # (128, 16, 16) -> (256, 8, 8) 'layer3': nn.Sequential( nn.Conv2d(nch_d * 4, nch_d * 8, 4, 2, 1), nn.BatchNorm2d(nch_d * 8), nn.LeakyReLU(negative_slope=0.2) ), # (256, 8, 8) -> (512, 4, 4) 'layer4': nn.Conv2d(nch_d * 8, 1, 4, 1, 0) # (512, 4, 4) -> (1, 1, 1) }) def forward(self, x): for layer in self.layers.values(): x = layer(x) return x.squeeze() |
Discriminator のコードです。基本的に、Generator の逆です。活性化関数は学習が安定するように、Discriminator の方だけ LeakyReULを使うのがお約束です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def main(): dataset = dset.ImageFolder(root='./celeba', transform=transforms.Compose([ transforms.RandomResizedCrop(64, scale=(0.9, 1.0), ratio=(1., 1.)), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=int(workers)) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('device:', device) netG = Generator(nz=nz, nch_g=nch_g).to(device) netG.apply(weights_init) print(netG) netD = Discriminator(nch_d=nch_d).to(device) netD.apply(weights_init) print(netD) criterion = nn.MSELoss() optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) |
メイン部分です。データは、CelebAの画像約20万枚をセンターから160×160でクロップしてから128×128にリサイズしたものを celeba フォルダーの下の「0」フォルダーにまとめて格納しました。
データを読み込み必要な処理を行ったら、データローダに渡します。Generator と Discriminator の2つのネットワークをインスタンス化し、重みの初期化を行います。損失関数は MSELoss(平均二乗誤差)、最適化関数は これもお約束 Adam を使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
##### trainig_loop for epoch in range(n_epoch): for itr, data in enumerate(dataloader): real_image = data[0].to(device) # 本物画像 sample_size = real_image.size(0) # 画像枚数 noise = torch.randn(sample_size, nz, 1, 1, device=device) # 入力ベクトル生成(正規分布ノイズ) real_target = torch.full((sample_size,), 1., device=device) # 目標値(本物) fake_target = torch.full((sample_size,), 0., device=device) # 目標値(偽物) #-------- Update Discriminator --------- netD.zero_grad() # 勾配の初期化 output = netD(real_image) # Discriminatorが行った、本物画像の判定結果 errD_real = criterion(output, real_target) # 本物画像の判定結果と目標値(本物)の二乗誤差 D_x = output.mean().item() # outputの平均 D_x を計算(後でログ出力に使用) fake_image = netG(noise) # Generatorが生成した偽物画像 output = netD(fake_image.detach()) # Discriminatorが行った、偽物画像の判定結果 errD_fake = criterion(output, fake_target) # 偽物画像の判定結果と目標値(偽物)の二乗誤差 D_G_z1 = output.mean().item() # outputの平均 D_G_z1 を計算(後でログ出力に使用) errD = errD_real + errD_fake # Discriminator 全体の損失 errD.backward() # 誤差逆伝播 optimizerD.step() # Discriminatoeのパラメーター更新 #--------- Update Generator ---------- netG.zero_grad() # 勾配の初期化 output = netD(fake_image) # 更新した Discriminatorで、偽物画像を判定 errG = criterion(output, real_target) # 偽物画像の判定結果と目標値(本物)の二乗誤差 errG.backward() # 誤差逆伝播 D_G_z2 = output.mean().item() # outputの平均 D_G_z2 を計算(後でログ出力に使用) optimizerG.step() # Generatorのパラメータ更新 |
学習ループです。先程の論文にある様に、Discriminator は本物画像の判定結果と目標値(本物)の二乗誤差と偽物画像の判定結果と目標値(偽物)の二乗誤差の最小化を図ります。そして、Generator は、Discriminator の偽物画像の判定結果と目標値(本物)の二乗誤差の最小化を図ります。
それでは、コードを動かしてみます。batch_size 64、20 epochを GTX1060で動かすと、所用時間は2時間強くらいでした。
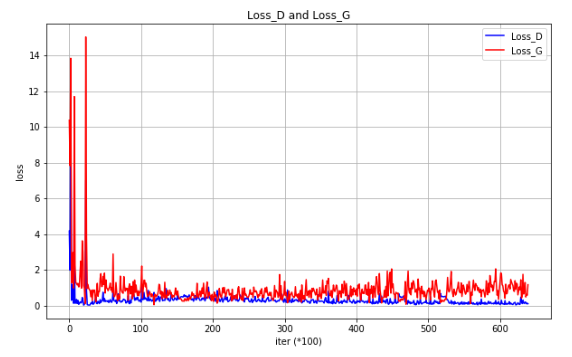
ロスDとロスGの推移グラフです。横軸の単位は iter (×100)で、バッチ単位で学習を行った回数です。いやー、ビックリしました。もう何の不安も感じさせないほど安定してます。LSGAN凄いです。

1500 iter 毎に生成した fake_image をGIF動画にしたものです。毎回入力するベクトルを固定しているので、同じ画像の質がだんだん上がって行く状態が見えて興味深いです。
それにしても、以前やってみたDCGANとは比べ物にならないくらい安定しています。技術革新の早さを感じますね。最後に、コード全体を載せておきます。
では、また。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 |
import os import random import numpy as np import torch.nn as nn import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils import matplotlib.pyplot as plt # Initial_setting workers = 2 batch_size=64 nz = 100 nch_g = 64 nch_d = 64 n_epoch = 20 lr = 0.0002 beta1 = 0.5 outf = './result_lsgan' display_interval = 100 save_fake_image_interval = 1500 plt.rcParams['figure.figsize'] = 10, 6 try: os.makedirs(outf, exist_ok=True) except OSError as error: print(error) pass random.seed(0) np.random.seed(0) torch.manual_seed(0) def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) m.bias.data.fill_(0) elif classname.find('Linear') != -1: m.weight.data.normal_(0.0, 0.02) m.bias.data.fill_(0) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) class Generator(nn.Module): def __init__(self, nz=100, nch_g=64, nch=3): super(Generator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.ConvTranspose2d(nz, nch_g * 8, 4, 1, 0), nn.BatchNorm2d(nch_g * 8), nn.ReLU() ), # (100, 1, 1) -> (512, 4, 4) 'layer1': nn.Sequential( nn.ConvTranspose2d(nch_g * 8, nch_g * 4, 4, 2, 1), nn.BatchNorm2d(nch_g * 4), nn.ReLU() ), # (512, 4, 4) -> (256, 8, 8) 'layer2': nn.Sequential( nn.ConvTranspose2d(nch_g * 4, nch_g * 2, 4, 2, 1), nn.BatchNorm2d(nch_g * 2), nn.ReLU() ), # (256, 8, 8) -> (128, 16, 16) 'layer3': nn.Sequential( nn.ConvTranspose2d(nch_g * 2, nch_g, 4, 2, 1), nn.BatchNorm2d(nch_g), nn.ReLU() ), # (128, 16, 16) -> (64, 32, 32) 'layer4': nn.Sequential( nn.ConvTranspose2d(nch_g, nch, 4, 2, 1), nn.Tanh() ) # (64, 32, 32) -> (3, 64, 64) }) def forward(self, z): for layer in self.layers.values(): z = layer(z) return z class Discriminator(nn.Module): def __init__(self, nch=3, nch_d=64): super(Discriminator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.Conv2d(nch, nch_d, 4, 2, 1), nn.LeakyReLU(negative_slope=0.2) ), # (3, 64, 64) -> (64, 32, 32) 'layer1': nn.Sequential( nn.Conv2d(nch_d, nch_d * 2, 4, 2, 1), nn.BatchNorm2d(nch_d * 2), nn.LeakyReLU(negative_slope=0.2) ), # (64, 32, 32) -> (128, 16, 16) 'layer2': nn.Sequential( nn.Conv2d(nch_d * 2, nch_d * 4, 4, 2, 1), nn.BatchNorm2d(nch_d * 4), nn.LeakyReLU(negative_slope=0.2) ), # (128, 16, 16) -> (256, 8, 8) 'layer3': nn.Sequential( nn.Conv2d(nch_d * 4, nch_d * 8, 4, 2, 1), nn.BatchNorm2d(nch_d * 8), nn.LeakyReLU(negative_slope=0.2) ), # (256, 8, 8) -> (512, 4, 4) 'layer4': nn.Conv2d(nch_d * 8, 1, 4, 1, 0) # (512, 4, 4) -> (1, 1, 1) }) def forward(self, x): for layer in self.layers.values(): x = layer(x) return x.squeeze() def main(): dataset = dset.ImageFolder(root='./celeba', transform=transforms.Compose([ transforms.RandomResizedCrop(64, scale=(0.9, 1.0), ratio=(1., 1.)), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=int(workers)) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('device:', device) netG = Generator(nz=nz, nch_g=nch_g).to(device) netG.apply(weights_init) print(netG) netD = Discriminator(nch_d=nch_d).to(device) netD.apply(weights_init) print(netD) criterion = nn.MSELoss() optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) fixed_noise = torch.randn(batch_size, nz, 1, 1, device=device) # save_fake_image用ノイズ(固定) Loss_D_list, Loss_G_list = [], [] save_fake_image_count = 1 ##### trainig_loop for epoch in range(n_epoch): for itr, data in enumerate(dataloader): real_image = data[0].to(device) # 本物画像 sample_size = real_image.size(0) # 画像枚数 noise = torch.randn(sample_size, nz, 1, 1, device=device) # 入力ベクトル生成(正規分布ノイズ) real_target = torch.full((sample_size,), 1., device=device) # 目標値(本物) fake_target = torch.full((sample_size,), 0., device=device) # 目標値(偽物) #-------- Update Discriminator --------- netD.zero_grad() # 勾配の初期化 output = netD(real_image) # Discriminatorが行った、本物画像の判定結果 errD_real = criterion(output, real_target) # 本物画像の判定結果と目標値(本物)の二乗誤差 D_x = output.mean().item() # outputの平均 D_x を計算(後でログ出力に使用) fake_image = netG(noise) # Generatorが生成した偽物画像 output = netD(fake_image.detach()) # Discriminatorが行った、偽物画像の判定結果 errD_fake = criterion(output, fake_target) # 偽物画像の判定結果と目標値(偽物)の二乗誤差 D_G_z1 = output.mean().item() # outputの平均 D_G_z1 を計算(後でログ出力に使用) errD = errD_real + errD_fake # Discriminator 全体の損失 errD.backward() # 誤差逆伝播 optimizerD.step() # Discriminatoeのパラメーター更新 #--------- Update Generator ---------- netG.zero_grad() # 勾配の初期化 output = netD(fake_image) # 更新した Discriminatorで、偽物画像を判定 errG = criterion(output, real_target) # 偽物画像の判定結果と目標値(本物)の二乗誤差 errG.backward() # 誤差逆伝播 D_G_z2 = output.mean().item() # outputの平均 D_G_z2 を計算(後でログ出力に使用) optimizerG.step() # Generatorのパラメータ更新 if itr % display_interval == 0: print('[{}/{}][{}/{}] Loss_D: {:.3f} Loss_G: {:.3f} D(x): {:.3f} D(G(z)): {:.3f}/{:.3f}' .format(epoch + 1, n_epoch, itr + 1, len(dataloader), errD.item(), errG.item(), D_x, D_G_z1, D_G_z2)) Loss_D_list.append(errD.item()) Loss_G_list.append(errG.item()) if epoch == 0 and itr == 0: vutils.save_image(real_image, '{}/real_samples.png'.format(outf), normalize=True, nrow=8) if itr % save_fake_image_interval == 0 and itr > 0: fake_image = netG(fixed_noise) vutils.save_image(fake_image.detach(), '{}/fake_samples_{:03d}.png'.format(outf, save_fake_image_count), normalize=True, nrow=8) save_fake_image_count +=1 # --------- save fake image ---------- fake_image = netG(fixed_noise) vutils.save_image(fake_image.detach(), '{}/fake_samples_epoch_{:03d}.png'.format(outf, epoch + 1), normalize=True, nrow=8) # --------- save model ----------- if (epoch + 1) % 10 == 0: # 10エポックごとにモデルを保存する torch.save(netG.state_dict(), '{}/netG_epoch_{}.pth'.format(outf, epoch + 1)) torch.save(netD.state_dict(), '{}/netD_epoch_{}.pth'.format(outf, epoch + 1)) # plot graph plt.figure() plt.plot(range(len(Loss_D_list)), Loss_D_list, color='blue', linestyle='-', label='Loss_D') plt.plot(range(len(Loss_G_list)), Loss_G_list, color='red', linestyle='-', label='Loss_G') plt.legend() plt.xlabel('iter (*100)') plt.ylabel('loss') plt.title('Loss_D and Loss_G') plt.grid() plt.savefig('Loss_graph.png') if __name__ == '__main__': main() |












コメントを残す