
1.はじめに
今回ご紹介するのは、1つのモデルで顔画像の様々なスタイル合成を可能にするBlendGANという技術です。
*この論文は、2021.11に提出されました。
2.BlendGANとは?
従来、顔画像のスタイル合成はStyleGANを使ってレイヤー交換を行うのが一般的ですが、この技術では合成したいスタイルの種類だけモデルを用意する必要があります。BlendGANは、1つのモデルで顔画像の様々なスタイル合成を可能にする技術です。
それを実現するために、様々なスタイルの顔を集めた大規模データセットAAHQを用意し、下記のフレームワークで学習を行います。
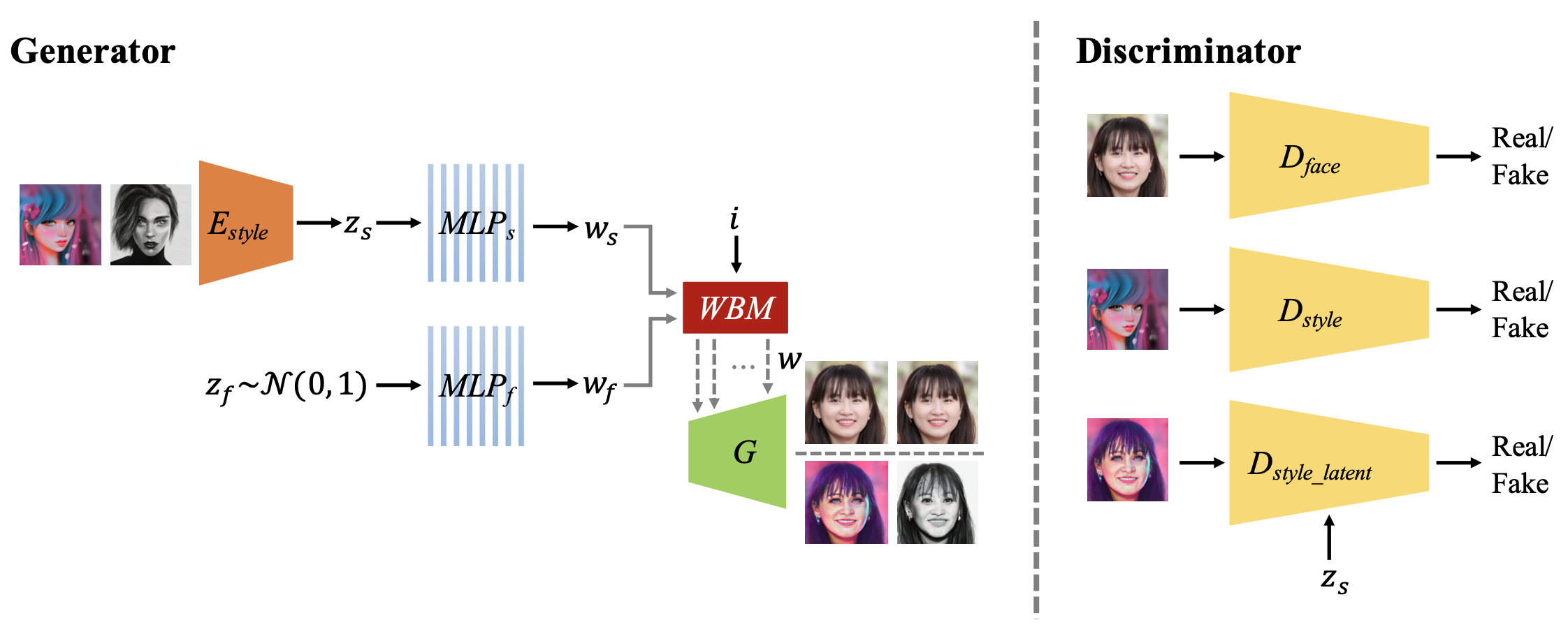
生成器(Generator)の入力は、通常のガウス分布からサンプリングしたランダムな潜在変数に加えて、エンコーダ(E_style)でスタイルの潜在変数を求め、この2つをマルチパーセプトロン(MLP)でW空間にマッピングし重み付きブレンディングモジュール(WBM)で結合したものを使用します。
識別器(Discriminator)は、顔の形(D_face)、スタイル(D_shape)、スタイルの潜在変数(Dstyle _latent)の3つが設定されています。
それでは、早速コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#@title セットアップ # githubからコードを取得 ! git clone https://github.com/cedro3/BlendGAN.git %cd BlendGAN # ninjaインストール !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force # 学習済みパラメータのダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1D27HPNOSx9kWIhc13VevRy0pUv_xYiJb', './pretrained_models/blendgan.pt', quiet=False) gdown.download('https://drive.google.com/uc?id=1pWWSm_c75ieMExJPWJuYA1wby-hm4f1J', './pretrained_models/psp_encoder.pt', quiet=False) gdown.download('https://drive.google.com/uc?id=1qshfqj8SdmgQv_kfLpiohbI3QPQF-OE5', './pretrained_models/style_encoder.pt', quiet=False) # ランドマークデータのダウンロード ! wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2 ! bzip2 -dk shape_predictor_68_face_landmarks.dat.bz2 # 画像の表示関数 import matplotlib.pyplot as plt from PIL import Image import os import numpy as np def display_pic(folder): fig = plt.figure(figsize=(30, 40)) files = os.listdir(folder) files.sort() for i, file in enumerate(files): img = Image.open(folder+'/'+file) images = np.asarray(img) ax = fig.add_subplot(10, 10, i+1, xticks=[], yticks=[]) image_plt = np.array(images) ax.imshow(image_plt) ax.set_xlabel(folder+'/'+file, fontsize=15) plt.show() plt.close() |
picフォルダーに保存されている画像から顔画像を切り出しalignフォルダーに保存します。自分が用意した画像を使う場合は、その画像をpicフォルダーにアップロードしてから下記を実行して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title 顔画像の切り出し import os import shutil from tqdm import tqdm if os.path.isdir('align'): shutil.rmtree('align') os.makedirs('align', exist_ok=True) def run_alignment(image_path): import dlib from alignment import align_face predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") aligned_image = align_face(filepath=image_path, predictor=predictor) return aligned_image path = './pic' files = sorted(os.listdir(path)) for i, file in enumerate(tqdm(files)): if file=='.ipynb_checkpoints': continue input_image = run_alignment(path+'/'+file) input_image.resize((1024,1024)) input_image.save('./align/'+file) display_pic('align') |

この中から変換したい顔画像を選んで input に指定します。ここでは 02.jpg を指定します。指定した顔画像は test_imgs/original_imgs にコピーされます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#@title 画像ファイル指定 input = "02.jpg"#@param {type:"string"} file = './align/'+input # original_imagesフォルダーリセット if os.path.isdir('test_imgs/original_imgs'): shutil.rmtree('test_imgs/original_imgs') os.makedirs('test_imgs/original_imgs', exist_ok=True) # original_imagesフォルダーへコピー import shutil shutil.copy(file, 'test_imgs/original_imgs/'+input) |
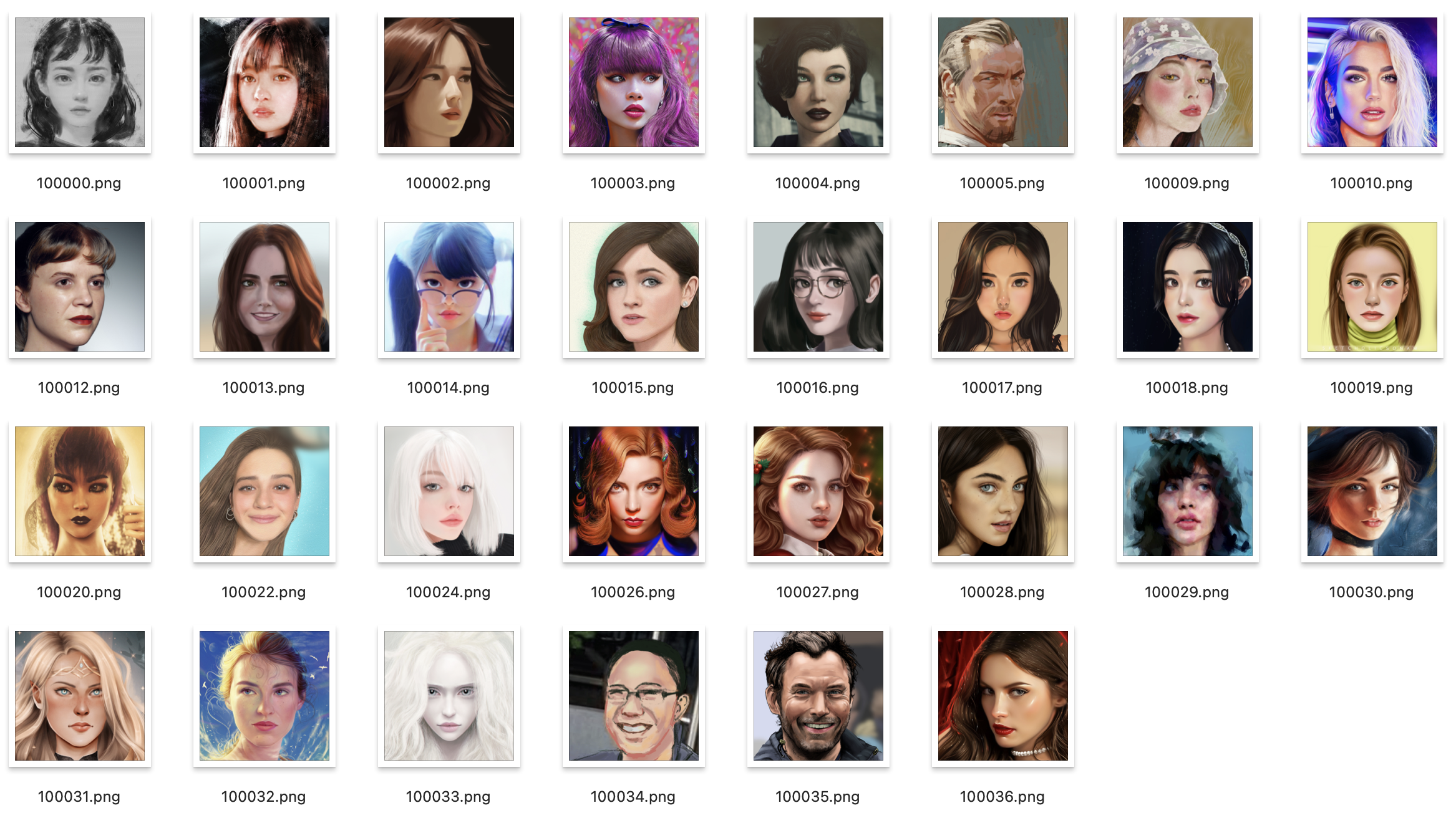
test_imgs/original_imgs の画像に、test_imgs/style_imgs の画像をブレンドし、results/style_transfer に保存します。ちなみに、results/style_transfer には下記の37個の画像が用意されています。
自分の用意した画像を使いたい場合は、このフォルダーに切り出した顔画像を追加して下さい。
そして、results/style_transfer の画像をリサイズして results/images に保存し、それを動画(fps = 0.6)にします。それではやってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#@title Style transfer を実行し動画を作成 # style_transferフォルダーリセット if os.path.isdir('results/style_transfer'): shutil.rmtree('results/style_transfer') ! python style_transfer_folder.py --size 1024 --ckpt ./pretrained_models/blendgan.pt --psp_encoder_ckpt ./pretrained_models/psp_encoder.pt --style_img_path ./test_imgs/style_imgs/ --input_img_path ./test_imgs/original_imgs/ --outdir results/style_transfer/ # imagesフォルダーリセット import os import shutil if os.path.isdir('results/images'): shutil.rmtree('results/images') os.makedirs('results/images', exist_ok=True) # output.mp4リセット if os.path.exists('./output.mp4'): os.remove('./output.mp4') # 画像のリサイズ import cv2 import glob files = glob.glob('results/style_transfer/*.jpg') files.sort() for i, file in enumerate(files): img = cv2.imread(file) img_resize = cv2.resize(img, dsize=(1536, 512)) cv2.imwrite('results/images/'+str(i).zfill(3)+'.jpg', img_resize) # 画像を動画に変換 !ffmpeg -r 0.6 -i results/images/%3d.jpg -vcodec libx264 -pix_fmt yuv420p output.mp4 |
作成した動画を再生してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
#@title 動画の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="100%" height="100%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
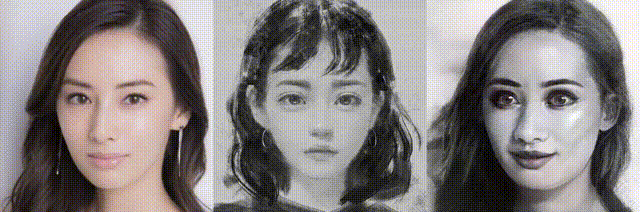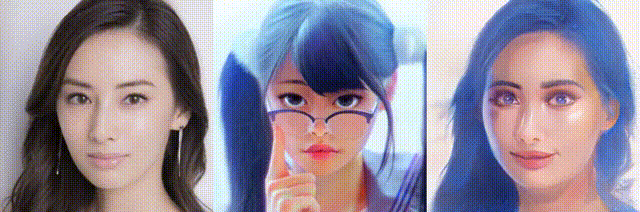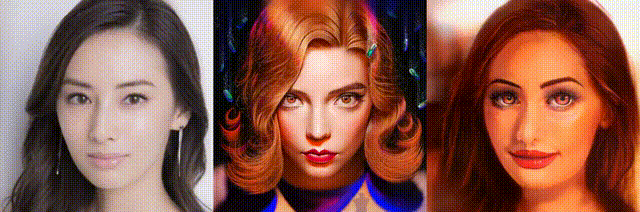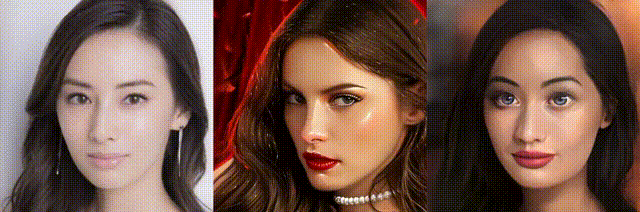
では、また。
(オリジナルgithub)https://github.com/onion-liu/BlendGAN
(twitter投稿)














コメントを残す