1.はじめに
今回ご紹介するのは、ディープラーニングによって画像から抽象的なスケッチを描くCLIPassoという技術です。
*この論文は、2022.2に提出されました。
2.CLIPassoとは?
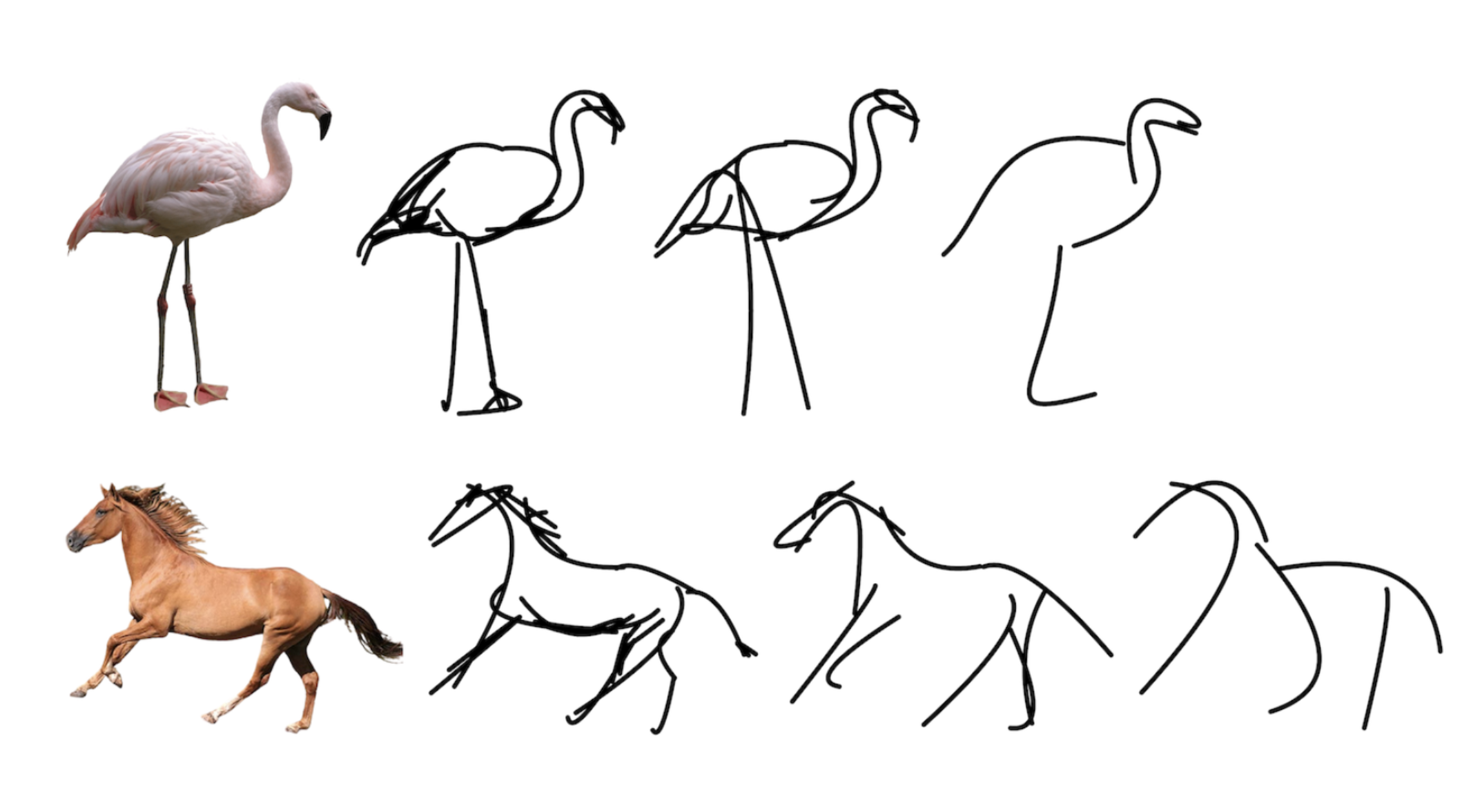
今まで画像のエッジを捉えたスケッチを描く技術は色々提案されているものの、抽象的なスケッチを描く技術はありませんでした。CLIPassoは、画像をベクトルに変換できるCLIPを活用することで、これを可能にしています。
下記がCLIPassoの概要図です。与えられた画像から特徴量を抽出し微分可能なRasterizerを通してスケッチ描きます。そして、CLIPではこのスケッチと与えられた画像それぞれをベクトル化し、COS類似度が最大になるように誤差逆伝播でパラメータの最適化を行うわけです。このとき、スケッチを描くときのストローク数を調整すると抽象度を調整できます。

3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#@title セットアップ(数分くらい掛かります) # cudaバージョンセレクト(10.1) %cd /usr/local/ !pwd !ls !rm -rf cuda !ln -s /usr/local/cuda-10.1 /usr/local/cuda !stat cuda !nvcc --version # githubからコードを取得 %cd /content/ !git clone https://github.com/cedro3/CLIPasso.git %cd CLIPasso # ライブラリー・インストール !pip install -r requirements.txt !pip install --upgrade gdown ### !pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 -f https://download.pytorch.org/whl/torch_stable.html %cd /content/CLIPasso !git pull # CLIP, diffvrのインストール %tensorflow_version 1.x ### %cd /content/CLIPasso !pip install git+https://github.com/openai/CLIP.git !git clone https://github.com/BachiLi/diffvg %cd diffvg !git submodule update --init --recursive !python setup.py install |
セットアップが完了したら、必ず「ランタイム/ランタイムを再起動」をクリックすることを忘れずに行なって下さい。これを行わないとこの後のコードが正常に動作しません。
run_object_sketching.py を使ってスケッチを作成します。引数は、target_imageで画像の指定(target_imagesフォルダにある画像から指定します)、num_sketchで作成回数(作成したものの中から後でBestを選択します)、mask_objectで画像の背景の有無(無:0, 有:1)、fix_scaleでスケールを固定かどうか(固定:0, 自動:1)、num_strokesでスケッチのストローク回数(4, 8, 16, 32 の中から選択可能です)です。
自分で用意した画像を使いたい場合は、test_imagesフォルダにアップロードしてください。なお、colabのGPUだと結構時間が掛かりますのでゆっくりお待ちください(P100で作成回数1回当たり7分くらい掛かります)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#@title スケッチの作成 %cd /content/CLIPasso !git pull # output_sketchesフォルダ・リセット from function import * reset_folder('output_sketches') %matplotlib inline target_image = "horse.png" #@param {"type": "string"} num_sketch = 3#@param {"type": "integer"} mask_object = 0 #@param {"type": "integer"} fix_scale = 0 #@param {"type": "integer"} num_strokes = 16#@param {"type": "integer"} %run run_object_sketching.py --target_file $target_image\ --num_sketches $num_sketch\ --mask_object $mask_object\ --fix_scale $fix_scale\ --num_strokes $num_strokes\ -colab |
|
1 2 |
#@title 画像表示と前処理 %run display_results.py --target_file $target_image |


それでは、スケッチを生成するプロセスの動画を見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#@title 動画表示 import glob import cv2 from function import * # imagesフォルダ・リセット reset_folder('images') # target_imageの高さ調整 base = cv2.imread('target_images/'+target_image) height, width, c = base.shape width = int(width*448/height) base = cv2.resize(base, dsize=(width,448)) # target_img + svg_to_png --> images files = sorted(glob.glob(f"{cur_path}/svg_to_png/*.png")) for i, file in enumerate(files): img = cv2.imread(file) concat_img = cv2.hconcat([base, img]) cv2.imwrite('images/'+str(i).zfill(6)+'.png', concat_img) # 動画の作成 !ffmpeg -y -r 10 -i images/%6d.png -vcodec libx264 -pix_fmt yuv420p -loglevel error output.mp4 # 動画の再生 display_mp4('output.mp4') |

いかがだったでしょうか?極少ない線で画像の本質を表現するような技術、面白いですよね。
では、また。
(オリジナルgithub)https://github.com/yael-vinker/CLIPasso
(twitter投稿)













2022/03/15現在
https://github.com/cedro3/CLIPasso/blob/main/CLIPasso.ipynb
で実行途中で
ModuleNotFoundError: No module named ‘pydiffvg’
が出てしまいます。
tさん
ご連絡ありがとうございます。
diffvgのインストール時にtensorflowのバージョン切り替えが上手くいっていなかったことが原因でした。
以下を追加し、修正済みです。再度、お試し下さい。
%tensorflow_version 1.x