
1.はじめに
2021年新年早々、OpenAIが「テキストを入力するとそれっぽい画像を生成するDALL-Eというモデル」を発表し、私はその表現力に衝撃を受けました。
先週、OpenAIからコードの一部(Discrete VAE の部分)と論文が公開されましたが、まだ公式にはDALL-Eを完全には動かせない状態です。
そうした中、@advadnoun さんがこれを受けて Discrete VAE に CLIP を組み合わせたプロトタイプを公表してくれました(素晴らしい!)。今回はこれを試してみたいと思います。
2.DALL-Eとは?
DALL-Eは、任意のテキストを入力するとその内容に合わせた画像を生成するモデルです。このモデルは、大きく分けると2つのステージを経て作られます。
ステージ1は、画像の圧縮・復元モジュールの作成です。これには、Discrete VAE(離散変分オートエンコーダ)と呼ばれるモデルが使われていて、エンコーダがRGB 256×256画像を32×32の中間出力に圧縮し、デコーダはその中間出力を再び入力とほぼ同品質のRGB256×256画像に復元します。
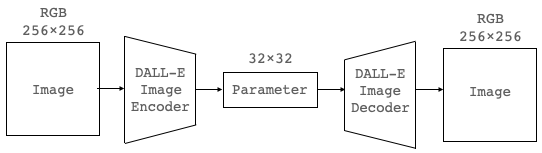
一般的に画像は情報量が大きくそのままでは扱い難い訳ですが、Discrete VAEの中間出力を使うことで画像の情報量を192分の1に削減出来ることになります。Discrete VAEは、画像のみを学習データとして、入力した画像を正確に出力することを学習します。
ステージ2は、画像とテキストの対応関係の学習です。これには、Transformerと呼ばれるモデル(赤の点線で囲まれたEncoderの部分)が使われていて、画像情報(画像トークン)とその内容を説明するテキスト情報(テキストトークン)の対応関係を学習します。
Transformerへ入力するデータ形式は、画像トークンとして先ほどの中間出力(32×32=1024個)、テキストトークンとしてテキストを構成する単語をベクトルに変換したもの(最大256個)、この2つを連結したものです。
学習データはインターネットから収集された2億5000万の画像とテキストのペアを先程の形式にし、120億のパラメーターを持つ巨大なTransformerに学習させます。
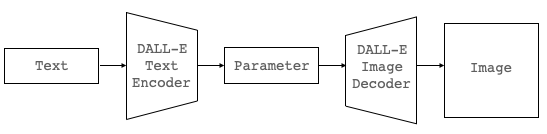
この2つのステージが完了すると、下記の様にテキストから画像トークンを求めて画像に復元させれば目的が達成できるわけです。しかし、残念ながら現段階で DALL-E Text Encoder は公表されていないので、この方法は使えません。
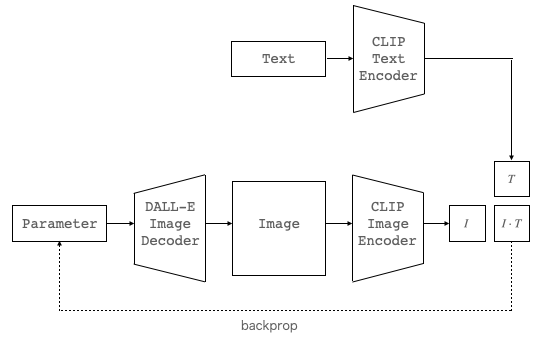
そこで、少し回り道になりますが、同じくOpenAIが発表したCLIP(テキストと画像それぞれから特徴ベクトルを抽出し類似度を算出できるモデル)を組み合わせて下記の様なプロトタイプを考えます。
CLIPを使って、Textと DALL-E Image Decoder の出力それぞれから特徴ベクトル(T, I )を求め、類似度(ベクトルの内積)が出来るだけ高くなるように誤差逆伝播で Parameter を最適化すれば、目的とする画像(Image)が生成できるわけです。
3.コード
コードはオリジナルを少しいじったものをGithubに上げてあります。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
最初に、セットアップを行います。
|
1 2 |
# GPUスペック確認 !nvidia-smi -L |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Pytorchバージョン変更 ! pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/torch_stable.html # Pytorch画像処理ライブラリー・インストール ! pip install kornia # CLIP関連コードのコピー ! git clone https://github.com/openai/CLIP.git %cd /content/CLIP/ # CLIPのモデル化 ! pip install ftfy regex import clip model, preprocess = clip.load('ViT-B/32', jit=True) model = model.eval() # DALL-Eのモデル化 ! pip install DALL-E from dall_e import map_pixels, unmap_pixels, load_model dec = load_model("https://cdn.openai.com/dall-e/decoder.pkl", 'cuda') |
次に、必要なライブラリーのインポートと関数の定義を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
import torch import numpy as np import torchvision import torchvision.transforms.functional as TF import torchvision.transforms as T import kornia import PIL import os, io, sys import random import imageio from IPython import display from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" from google.colab import output import requests # 初期設定 im_shape = [512, 512, 3] sideX, sideY, channels = im_shape target_image_size = sideX tau_value = 2. # 画像表示・保存 def displ(img): img = np.array(img)[:,:,:] img = np.transpose(img, (1, 2, 0)) imageio.imwrite('output.png', np.array(img)) return display.Image('output.png') # 画像のランダム切り出し def augment(out, cutn=16): p_s = [] for ch in range(cutn): sizey = int(torch.zeros(1,).uniform_(.5, .99)*sideY) sizex = int(torch.zeros(1,).uniform_(.5, .99)*sideX) offsetx = torch.randint(0, sideX - sizex, ()) offsety = torch.randint(0, sideY - sizey, ()) apper = out[:, :, offsetx:offsetx + sizex, offsety:offsety + sizey] apper = apper + .1*torch.rand(1,1,1,1).cuda()*torch.randn_like(apper, requires_grad=True) apper = torch.nn.functional.interpolate(apper, (224,224), mode='bilinear') p_s.append(apper) into = augs(torch.cat(p_s, 0)) return into # 正規化と回転設定 nom = torchvision.transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)) augs = kornia.augmentation.RandomRotation(30).cuda() # パラメータの設定 class Pars(torch.nn.Module): def __init__(self): super(Pars, self).__init__() hots = torch.nn.functional.one_hot((torch.arange(0, 8192).to(torch.int64)), num_classes=8192) rng = torch.zeros(1, 64*64, 8192).uniform_() for i in range(64*64): rng[0,i] = hots[[np.random.randint(8191)]] rng = rng.permute(0, 2, 1) self.normu = torch.nn.Parameter(rng.cuda().view(1, 8192, 64*64)) def forward(self): normu = torch.nn.functional.gumbel_softmax(self.normu.reshape(1,64*64,8192), dim=1, tau=tau_value).view(1, 8192, 64, 64) return normu |
画像生成したいテキストを設定します。 text_input にテキストを設定し、特徴ベクトルに変換します。ここでは、an armchair in the shape of an avocado(アボガドの形をしたアームチェア)と設定しています。
|
1 2 3 4 5 6 |
# テキスト入力 text_input = 'an armchair in the shape of an avocado' # テキストを特徴ベクトルに変換 token = clip.tokenize(text_input) text_v = model.encode_text(token.cuda()).detach().clone() |
学習ループです。パラメータをリセットし、画像保存用のimagesフォルダーをリセットしたら、1001 iter 学習ループを廻します。学習の安定性を向上させるために、生成した画像から画像をランダムに切り出し・回転させたものを複数作成します。そしてそれらを正規化し平均をとってから特徴ベクトルに変換しています。生成した画像は、50iter 毎にimages フォルダーに、000000.pngという連番形式で保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# パラメータリセット latent = Pars().cuda() param = [latent.normu] optimizer = torch.optim.Adam([{'params': param, 'lr': .01}]) # images フォルダーリセット import os import shutil if os.path.isdir('images'): shutil.rmtree('images') os.makedirs('images', exist_ok=True) # 学習ループ for iteration in range(1001): # --- 順伝播 --- # パラメータから画像を生成 out = unmap_pixels(torch.sigmoid(dec(latent())[:, :3].float())) # 画像をランダム切り出し・回転 into = augment(out) # 画像を正規化 into = nom((into)) # 画像から特徴ベクトルを取得 image_v = model.encode_image(into) # テキストと画像の特徴ベクトルのCOS類似度を計算 loss = -torch.cosine_similarity(text_v, image_v).mean() # 逆伝播 optimizer.zero_grad() loss.backward() optimizer.step() # 学習率の調整 for g in optimizer.param_groups: g['lr'] = g['lr']*1.005 g['lr'] = min(g['lr'], .12) # ログ表示 if iteration % 50 == 0: with torch.no_grad(): # 生成画像の表示・保存 out = unmap_pixels(torch.sigmoid(dec(latent())[:, :3]).float()) displ(out.cpu()[0]) shutil.copy('output.png', './images/%s.png'%str(int(iteration/50)).zfill(6)) # データ表示 print('iter = ',iteration) for g in optimizer.param_groups: print('lr = ', g['lr']) print('tau_value = ', tau_value) print('loss = ',loss.item()) print('\n') |

OpenAIのデモではスマートな画像でしたが、ちょっとリアリティがある感じになりました。
生成過程を動画にします。ffmpeg でimages フォルダーの連番画像から動画を作成します。学習回数(iter)を変更する場合は、最後の画像を5枚コピーする部分のforループの設定も変更して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# images フォルダーの最後の画像を5枚コピー import shutil for i in range(21,26,1): shutil.copy('output.png', './images/%s.png'%str(int(i)).zfill(6)) # ouput.mp4を一旦削除 import os if os.path.exists('./output.mp4'): os.remove('./output.mp4') # images フォルダーの画像から動画を生成 ! ffmpeg -r 5 -i images/%06d.png -vcodec libx264 -pix_fmt yuv420p output.mp4 |
それでは、作成した動画を再生してみましょう。
|
1 2 3 4 5 6 7 8 9 |
from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |

2回目以降画像生成を行いたい場合は、「テキストの設定」以降を繰り返せばOKです。それでは、いくつか試した結果をお見せします。
エッシャーが設計した美しくミステリアスな家(a beautiful and mysterious house designed by Escher)

騙し絵の大家エッシャーの雰囲気が結構出てますよね。
モナリザが屋上にあるジャグジーで赤ワインを飲んでいる(Mona Lisa is drinking red wine in the rooftop jacuzzi)

正に、無茶苦茶なテキストを与えたわけですが、さすがDALL-Eです、こちらの要求をちゃんとかなえてくれました(笑)。
ガウディが設計したスポーツカー(Sports car designed by Gaudi)

これは凄いです!もはや車の概念を超えています。さすがガウディ、ぶっ飛んでいます(笑)。
それにしても、クリエイティブな感覚を刺激してくれる面白いモデルです。ビジュアルで詰まっている時に、気分転換に使うと色々なアイディアが出て来そうな気がします。凄い時代になったものです。
では、また。
2021.6.22最新版Colabリンク
https://colab.research.google.com/drive/1L8oL-vLJXVcRzCFbPwOoMkPKJ8-aYdPN
(twitter投稿)













自分でも試してみましたが、それっぽい画像はできますがOPENAIのようなきれいな画像はなかなかできないですね・・・
やはりこれはTransformerの部分の影響でしょうか?
おでんの卵さん
仰る通り、Transformerの部分が未公開のため、CLIPで代用しているためです。