
今回は、keras の seq2seq サンプルプログラムを使って、チャットボットをやってみます。
こんにちは cedro です。
keras の seq2seq サンプルプログラムは、系列を入力として受け取り、それに対応する系列を出力するモデルです。先回はこのサンプルプログラムを使って、英文の単語の系列を受け取り、それと同じ意味の日本文の単語の系列を出力することで、英日翻訳をやってみました。
ということは、このサンプルプログラムをそのまま使って、日本文の単語の系列を受け取り、それに応答する日本文の単語の系列を出力すれば、チャットボットが出来ることはお分かりになると思います。
ということで、今回は、keras の seq2seq サンプルプログラムを使って、チャットボットをやってみます。
データセットを準備します
まず、データセットのフォーマットはどうすれば良いのか、先回使った 英文と日本訳のデータセット(jpn-eng.zip)を見てみましょう。

英文があって、タブ区切りで日本文が続く形です。つまり、入力したい単語の系列、タブ区切り、出力したい単語の系列、改行と書けば良いわけです。

日本語の対話のデータセットを色々探してみました。その中で面白そうだったのが、この GitHub のデータセット(corpus.distinct.txt)です。これはノクターンノベルズなどの小説から対話部分を抜き出して作ったものだそうで、対話の区切りは「___SP___」で表現されています。
また、めずらしい分かち書きしたカタカナ文なのですが、これだと文字の種類が少なくてすむので予測させ易いですね。GINK03 さん、データセットをありがたく使わせて頂きます。感謝致します!
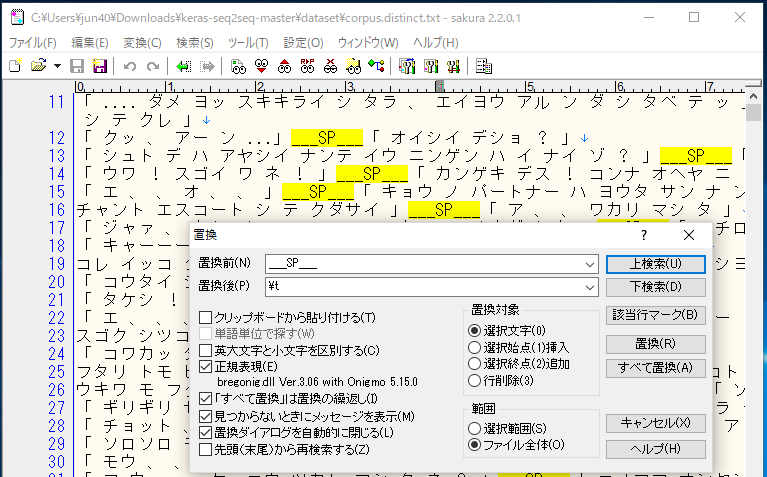
サンプルプログラムが適切に読み込めるように、データセットを加工します。python で加工プログラムを書いても良いですが、この程度ならエディタの方が簡単で速いので、今回はサクラエディタを使います。
検索ー置換から、正規表現に✔を入れ、置換前に「___SP___」、置換後に「¥t」と入力し、全て置換のボタンを押せば、___SP___区切りがタブ区切りに全て置き換わります。ここで正規表現というのは、タブ区切りとか改行などの制御文字を見えるようにすることを言い、タブ区切りの制御文字は「¥t」だというわけです。

あと、分かち書きの空白は頻繁に出現するため予測する時にノイズになり易いので、空白は全て削除します。置換前「 」、置換後「」(置換前はスペースを入力、置換後は何も入力しない)で全て置換のボタンを押せば、空白は全部削除されます。
データセットの加工が終わったら、サンプルプログラムがあるフォルダーに dataset フォルダーを作り、その中に katakana_txt という名前で保存します。
サンプルプログラムを確認します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 |
from __future__ import print_function from keras.models import Model from keras.layers import Input, LSTM, Dense import numpy as np batch_size = 64 # Batch size for training. epochs = 100 # Number of epochs to train for. latent_dim = 256 # Latent dimensionality of the encoding space. num_samples = 20000 # Number of samples to train on. # Path to the data txt file on disk. data_path = 'dataset/katakana.txt' # Vectorize the data. input_texts = [] target_texts = [] input_characters = set() target_characters = set() with open(data_path, 'r', encoding='utf-8') as f: lines = f.read().split('\n') for line in lines[: min(num_samples, len(lines) - 1)]: input_text, target_text = line.split('\t') # We use "tab" as the "start sequence" character # for the targets, and "\n" as "end sequence" character. target_text = '\t' + target_text + '\n' input_texts.append(input_text) target_texts.append(target_text) for char in input_text: if char not in input_characters: input_characters.add(char) for char in target_text: if char not in target_characters: target_characters.add(char) input_characters = sorted(list(input_characters)) target_characters = sorted(list(target_characters)) num_encoder_tokens = len(input_characters) num_decoder_tokens = len(target_characters) max_encoder_seq_length = max([len(txt) for txt in input_texts]) max_decoder_seq_length = max([len(txt) for txt in target_texts]) print('Number of samples:', len(input_texts)) print('Number of unique input tokens:', num_encoder_tokens) print('Number of unique output tokens:', num_decoder_tokens) print('Max sequence length for inputs:', max_encoder_seq_length) print('Max sequence length for outputs:', max_decoder_seq_length) input_token_index = dict( [(char, i) for i, char in enumerate(input_characters)]) target_token_index = dict( [(char, i) for i, char in enumerate(target_characters)]) encoder_input_data = np.zeros( (len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype='float32') decoder_input_data = np.zeros( (len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype='float32') decoder_target_data = np.zeros( (len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype='float32') for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)): for t, char in enumerate(input_text): encoder_input_data[i, t, input_token_index[char]] = 1. for t, char in enumerate(target_text): # decoder_target_data is ahead of decoder_input_data by one timestep decoder_input_data[i, t, target_token_index[char]] = 1. if t > 0: # decoder_target_data will be ahead by one timestep # and will not include the start character. decoder_target_data[i, t - 1, target_token_index[char]] = 1. # Define an input sequence and process it. encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) # We discard `encoder_outputs` and only keep the states. encoder_states = [state_h, state_c] # Set up the decoder, using `encoder_states` as initial state. decoder_inputs = Input(shape=(None, num_decoder_tokens)) # We set up our decoder to return full output sequences, # and to return internal states as well. We don't use the # return states in the training model, but we will use them in inference. decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) # Define the model that will turn # `encoder_input_data` & `decoder_input_data` into `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # Run training model.compile(optimizer='rmsprop', loss='categorical_crossentropy') model.summary() # スクリーンにモデル表示 from keras.utils import plot_model # モデル保存ライブラリーのインポート plot_model(model, to_file = "seq2seq_k.png", show_shapes = True) # モデル保存実行 model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size=batch_size, epochs=epochs, validation_split=0.2) # Save model model.save('s2s.h5') # Next: inference mode (sampling). # Here's the drill: # 1) encode input and retrieve initial decoder state # 2) run one step of decoder with this initial state # and a "start of sequence" token as target. # Output will be the next target token # 3) Repeat with the current target token and current states # Define sampling models encoder_model = Model(encoder_inputs, encoder_states) decoder_state_input_h = Input(shape=(latent_dim,)) decoder_state_input_c = Input(shape=(latent_dim,)) decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c] decoder_outputs, state_h, state_c = decoder_lstm( decoder_inputs, initial_state=decoder_states_inputs) decoder_states = [state_h, state_c] decoder_outputs = decoder_dense(decoder_outputs) decoder_model = Model( [decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) # Reverse-lookup token index to decode sequences back to # something readable. reverse_input_char_index = dict( (i, char) for char, i in input_token_index.items()) reverse_target_char_index = dict( (i, char) for char, i in target_token_index.items()) def decode_sequence(input_seq): # Encode the input as state vectors. states_value = encoder_model.predict(input_seq) # Generate empty target sequence of length 1. target_seq = np.zeros((1, 1, num_decoder_tokens)) # Populate the first character of target sequence with the start character. target_seq[0, 0, target_token_index['\t']] = 1. # Sampling loop for a batch of sequences # (to simplify, here we assume a batch of size 1). stop_condition = False decoded_sentence = '' while not stop_condition: output_tokens, h, c = decoder_model.predict( [target_seq] + states_value) # Sample a token sampled_token_index = np.argmax(output_tokens[0, -1, :]) sampled_char = reverse_target_char_index[sampled_token_index] decoded_sentence += sampled_char # Exit condition: either hit max length # or find stop character. if (sampled_char == '\n' or len(decoded_sentence) > max_decoder_seq_length): stop_condition = True # Update the target sequence (of length 1). target_seq = np.zeros((1, 1, num_decoder_tokens)) target_seq[0, 0, sampled_token_index] = 1. # Update states states_value = [h, c] return decoded_sentence for seq_index in range(2000): # Take one sequence (part of the training set) # for trying out decoding. input_seq = encoder_input_data[seq_index: seq_index + 1] decoded_sentence = decode_sequence(input_seq) print('-') print('Input sentence:', input_texts[seq_index]) print('Decoded sentence:', decoded_sentence) |
100行目は、スクリーンにモデルを表示する部分を追加。101ー102行目は、モデルを ‘seq2seq_k.png’ というファイル名で保存する部分を追加していますが、pydot と graphviz が事前にインストールしてない場合は削除して下さい(エラーになります)。
179行目は、学習したニューラルネットワークを使って、データセットの頭から何行目までの入力を使って、チャットボットの入力とするかの指定です。今回は、2000にしてあります。
なお、サンプルプログラムの基本的な動きは先回のブログで書きましたので、そちらを見て下さい。
プログラムを動かしてみます
カタカナ文で文字の種類が少ないこともあって、20000行分のデータセットを読ませても、私の MacbookAir で 100sec/ eopch くらい、100epoch で約3時間弱で終わりますので、ノートパソコンでも十分動かせます。
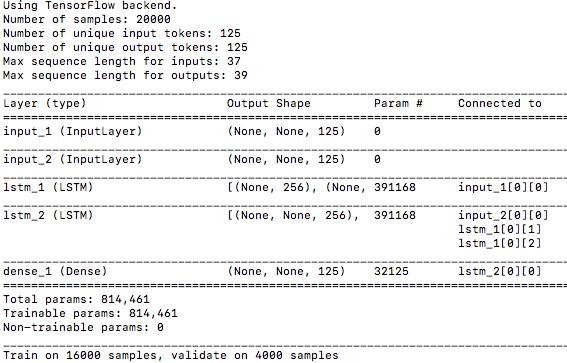
Number of unique output tokens は、先回は漢字交じりの日本文だったので1483種類と大きな数字でしたが、今回はカタカナ文になったので125種類と小さな数字になっています。これによって最適化が必要なパラメータ数、Total params は 2,499,787 → 814,461 と大幅に減ったため、データセットを 10000 →20000 に倍増しても、先回より処理は短時間で済みます。
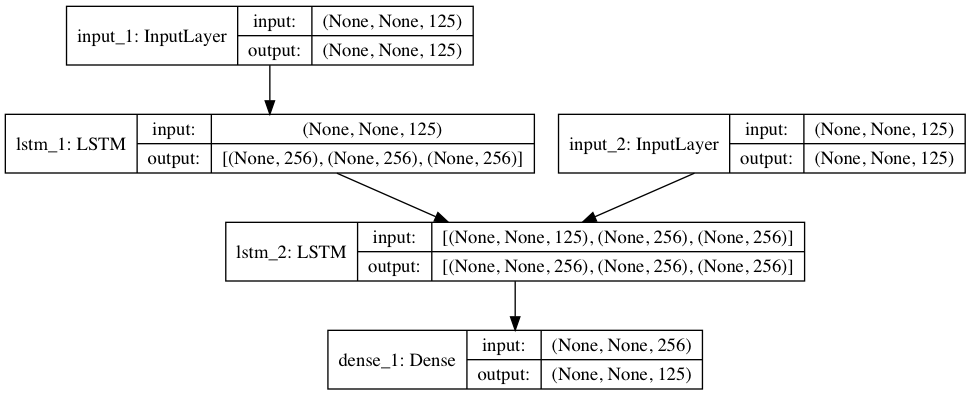
プログラムが保存したモデル(seq2seq_k.png)がこれです。

学習完了後の対話結果です。分かち書きしてないカタカナ文でも、結構読めます。例によって1文字単位の予測ですので精度はあまり良くないですが、なんとなく会話になっているのが面白いです(笑)。
seq2seq モデルは、原理的には、文字を入力してそれに対応する画像を出力することも、画像を入力して文字を出力することもできるわけで、相当応用範囲が広そうです。また、色々やってみたい気がします。
では、また。












コメントを残す