
1.はじめに
今回ご紹介するのは、StyleGANの全レイヤでコンテンツとスタイルのネットワークをミックスして高精度のスタイル転送を行うDualStyleGANです。
*この論文は、2022.3に提出されました。
2.DualStyleGANとは?
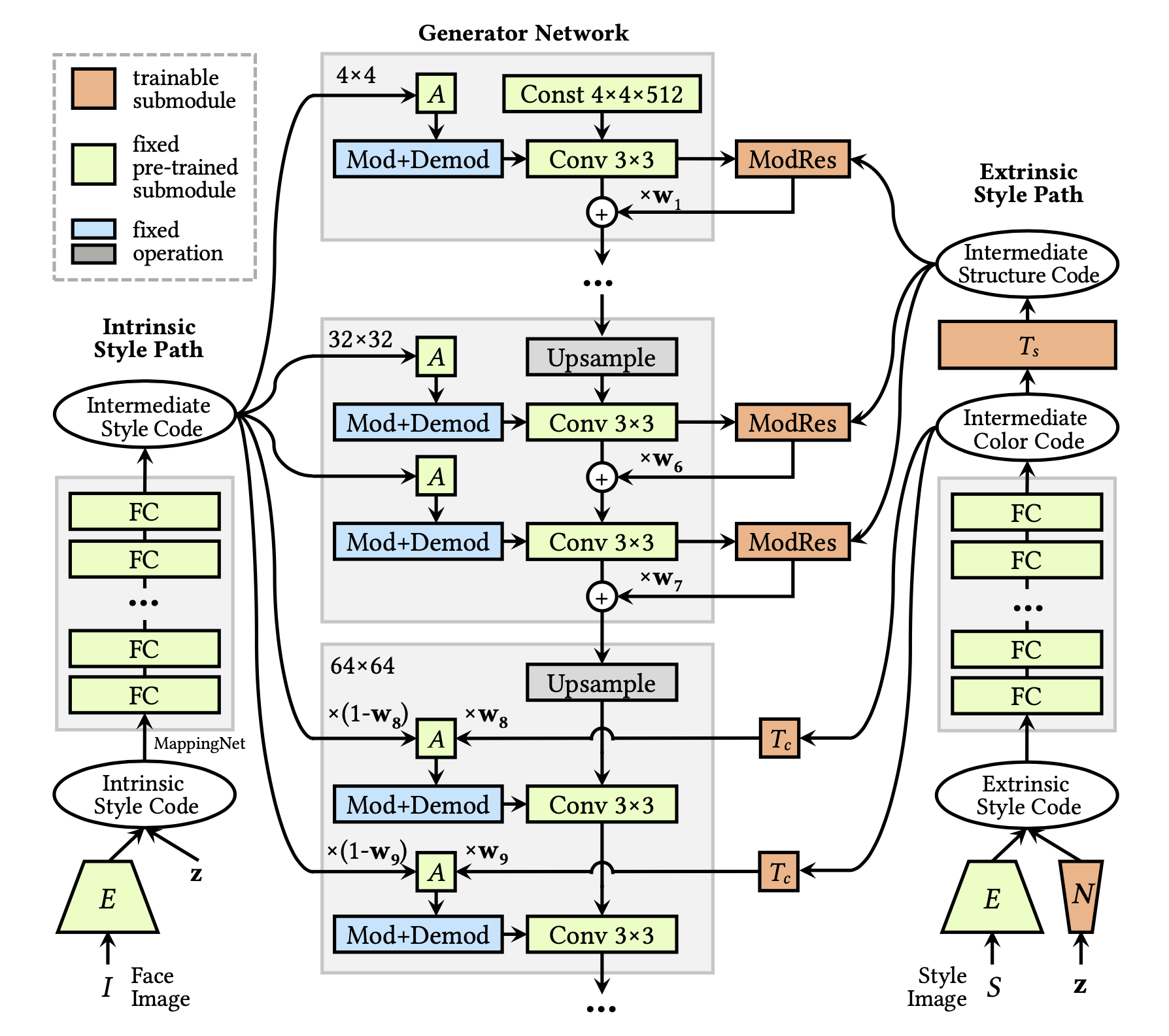
今までStyleGANでスタイル転送をする場合、コンテンツとスタイルのネットワークを低解像度レイヤと高解像度レイヤで切り替える手法が一般的でした。DualStyleGANは全レイヤでコンテンツとスタイルのネットワークをミックスすることによって高精度のスタイル転送を実現しています。
下記の図が、DualStyleGANのGenerator Networkで、左側がコンテンツ(Intrinsic Style Code)のネットワーク、右側がスタイル(Extrinsic Style Code)のネットワークです。そして、スタイルの内、基本的な構造に影響する低解像度レイヤ(〜32×32)への入力を構造、詳細部分に影響する高解像度レイヤ(64×64〜)への入力をカラーと呼んでいます。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title セットアップ !git clone https://github.com/cedro3/DualStyleGAN.git %cd DualStyleGAN !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force !pip install faiss-cpu !pip install wget %load_ext autoreload %autoreload 2 import numpy as np import torch from util import save_image, load_image, visualize import argparse from argparse import Namespace from torchvision import transforms from torch.nn import functional as F import torchvision import matplotlib.pyplot as plt from model.dualstylegan import DualStyleGAN from model.sampler.icp import ICPTrainer from model.encoder.psp import pSp |
次に、学習済みパラメータのダウンロードを style_type を指定して実行します。gdownを使ってgoogle driveからダウンロードしますが、最近時々ミスることがあるので最大10回までトライさせる仕様にしています。ここでは、 style_type は cartoon を選択しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
#@title 学習済みパラメータのダウンロード style_type = 'cartoon'#@param ['cartoon', 'caricature', 'anime', 'arcane', 'comic', 'pixar', 'slamdunk'] MODEL_PATHS = { "encoder": {"id": "1NgI4mPkboYvYw3MWcdUaQhkr0OWgs9ej", "name": "encoder.pt"}, "cartoon-G": {"id": "1exS9cSFkg8J4keKPmq2zYQYfJYC5FkwL", "name": "generator.pt"}, "cartoon-N": {"id": "1JSCdO0hx8Z5mi5Q5hI9HMFhLQKykFX5N", "name": "sampler.pt"}, "cartoon-S": {"id": "1ce9v69JyW_Dtf7NhbOkfpH77bS_RK0vB", "name": "refined_exstyle_code.npy"}, "caricature-G": {"id": "1BXfTiMlvow7LR7w8w0cNfqIl-q2z0Hgc", "name": "generator.pt"}, "caricature-N": {"id": "1eJSoaGD7X0VbHS47YLehZayhWDSZ4L2Q", "name": "sampler.pt"}, "caricature-S": {"id": "1-p1FMRzP_msqkjndRK_0JasTdwQKDsov", "name": "refined_exstyle_code.npy"}, "anime-G": {"id": "1BToWH-9kEZIx2r5yFkbjoMw0642usI6y", "name": "generator.pt"}, "anime-N": {"id": "19rLqx_s_SUdiROGnF_C6_uOiINiNZ7g2", "name": "sampler.pt"}, "anime-S": {"id": "17-f7KtrgaQcnZysAftPogeBwz5nOWYuM", "name": "refined_exstyle_code.npy"}, "arcane-G": {"id": "15l2O7NOUAKXikZ96XpD-4khtbRtEAg-Q", "name": "generator.pt"}, "arcane-N": {"id": "1fa7p9ZtzV8wcasPqCYWMVFpb4BatwQHg", "name": "sampler.pt"}, "arcane-S": {"id": "1z3Nfbir5rN4CrzatfcgQ8u-x4V44QCn1", "name": "exstyle_code.npy"}, "comic-G": {"id": "1_t8lf9lTJLnLXrzhm7kPTSuNDdiZnyqE", "name": "generator.pt"}, "comic-N": {"id": "1RXrJPodIn7lCzdb5BFc03kKqHEazaJ-S", "name": "sampler.pt"}, "comic-S": {"id": "1ZfQ5quFqijvK3hO6f-YDYJMqd-UuQtU-", "name": "exstyle_code.npy"}, "pixar-G": {"id": "1TgH7WojxiJXQfnCroSRYc7BgxvYH9i81", "name": "generator.pt"}, "pixar-N": {"id": "18e5AoQ8js4iuck7VgI3hM_caCX5lXlH_", "name": "sampler.pt"}, "pixar-S": {"id": "1I9mRTX2QnadSDDJIYM_ntyLrXjZoN7L-", "name": "exstyle_code.npy"}, "slamdunk-G": {"id": "1MGGxSCtyf9399squ3l8bl0hXkf5YWYNz", "name": "generator.pt"}, "slamdunk-N": {"id": "1-_L7YVb48sLr_kPpOcn4dUq7Cv08WQuG", "name": "sampler.pt"}, "slamdunk-S": {"id": "1Dgh11ZeXS2XIV2eJZAExWMjogxi_m_C8", "name": "exstyle_code.npy"}, } import os os.makedirs('checkpoint/'+style_type, exist_ok=True) ! pip install --upgrade gdown import gdown # download pSp encoder for i in range(10): path = MODEL_PATHS["encoder"] if os.path.isfile('checkpoint/encoder.pt'): break else: path['name'] == 'encoder.pt' gdown.download('https://drive.google.com/uc?id='+path['id'], 'checkpoint/'+path['name'], quiet=False) # download dualstylegan for i in range(10): path = MODEL_PATHS[style_type+'-G'] if os.path.isfile('checkpoint/'+style_type+'/'+path['name']): break else: gdown.download('https://drive.google.com/uc?id='+path['id'], 'checkpoint/'+style_type+'/'+path['name'], quiet=False) # download sampler for i in range(10): path = MODEL_PATHS[style_type+'-N'] if os.path.isfile('checkpoint/'+style_type+'/'+path['name']): break else: gdown.download('https://drive.google.com/uc?id='+path['id'], 'checkpoint/'+style_type+'/'+path['name'], quiet=False) # download extrinsic style code for i in range(10): path = MODEL_PATHS[style_type+'-S'] if os.path.isfile('checkpoint/'+style_type+'/'+path['name']): break else: gdown.download('https://drive.google.com/uc?id='+path['id'], 'checkpoint/'+style_type+'/'+path['name'], quiet=False) # --- モデルのロード --- MODEL_DIR = 'checkpoint' DATA_DIR = 'data' device = 'cuda' transform = transforms.Compose( [ transforms.Resize(256), transforms.CenterCrop(256), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]), ] ) # load DualStyleGAN generator = DualStyleGAN(1024, 512, 8, 2, res_index=6) generator.eval() ckpt = torch.load(os.path.join(MODEL_DIR, style_type, 'generator.pt'), map_location=lambda storage, loc: storage) generator.load_state_dict(ckpt["g_ema"]) generator = generator.to(device) # load encoder model_path = os.path.join(MODEL_DIR, 'encoder.pt') ckpt = torch.load(model_path, map_location='cpu') opts = ckpt['opts'] opts['checkpoint_path'] = model_path opts = Namespace(**opts) opts.device = device encoder = pSp(opts) encoder.eval() encoder = encoder.to(device) # load extrinsic style code exstyles = np.load(os.path.join(MODEL_DIR, style_type, MODEL_PATHS[style_type+'-S']["name"]), allow_pickle='TRUE').item() # load sampler network icptc = ICPTrainer(np.empty([0,512*11]), 128) icpts = ICPTrainer(np.empty([0,512*7]), 128) ckpt = torch.load(os.path.join(MODEL_DIR, style_type, 'sampler.pt'), map_location=lambda storage, loc: storage) icptc.icp.netT.load_state_dict(ckpt['color']) icpts.icp.netT.load_state_dict(ckpt['structure']) icptc.icp.netT = icptc.icp.netT.to(device) icpts.icp.netT = icpts.icp.netT.to(device) print('Model successfully loaded!') |
コンテンツ画像を指定します。自分の画像を使用したい場合は、data/contentフォルダにアップロードして下さい。
|
1 2 3 4 5 6 7 8 9 |
#@title 画像入力 %matplotlib inline image_path = './data/content/02.jpg' #@param {type:"string"} original_image = load_image(image_path) plt.figure(figsize=(10,10),dpi=30) visualize(original_image[0]) plt.show() |

alignを処理を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title align処理 if_align_face = True def run_alignment(image_path): import dlib from model.encoder.align_all_parallel import align_face modelname = os.path.join(MODEL_DIR, 'shape_predictor_68_face_landmarks.dat') if not os.path.exists(modelname): import wget, bz2 wget.download('http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2', modelname+'.bz2') zipfile = bz2.BZ2File(modelname+'.bz2') data = zipfile.read() open(modelname, 'wb').write(data) predictor = dlib.shape_predictor(modelname) aligned_image = align_face(filepath=image_path, predictor=predictor) return aligned_image if if_align_face: I = transform(run_alignment(image_path)).unsqueeze(dim=0).to(device) else: I = F.adaptive_avg_pool2d(load_image(image_path).to(device), 256) plt.figure(figsize=(10,10),dpi=30) visualize(I[0].cpu()) plt.show() |

次に、スタイルを選択します。スタイルは、画像ファイルの名前とスタイルの重みを登録した辞書exstylesの何番目を選ぶかをスライダーで指定します。
画像ファイルは、data/cartoon/images/train にあるものを使っています。cartoon 以外の style_type を使う場合は、該当するフォルダへこの情報を参考に画像をアップロードする必要がありますのでご注意下さい。
ここでは、辞書exstylesの26番目に登録されている画像ファイル名とスタイルの重みを使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#@title スタイルの選択 style_id = 26 #@param {type:"slider", min:0, max:316, step:1} # try to load the style image stylename = list(exstyles.keys())[style_id] stylepath = os.path.join(DATA_DIR, style_type, 'images/train', stylename) print('loading %s'%stylepath) if os.path.exists(stylepath): S = load_image(stylepath) plt.figure(figsize=(10,10),dpi=30) visualize(S[0]) plt.show() else: print('%s is not found'%stylename) |

それではスタイル転送を行ってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#@title スタイル転送 #@markdown From left to right: #@markdown 1. **pSp recontructed content image** #@markdown 2. **style transfer result**: both color and strcture styles are transferred #@markdown 3. **structure transfer result**: preserve the color of the content image by replacing the extrinsic color codes with intrinsic color codes #@markdown 4. **structure transfer result**: preserve the color of the content image by deactivating color-related layers with torch.no_grad(): img_rec, instyle = encoder(I, randomize_noise=False, return_latents=True, z_plus_latent=True, return_z_plus_latent=True, resize=False) img_rec = torch.clamp(img_rec.detach(), -1, 1) latent = torch.tensor(exstyles[stylename]).repeat(2,1,1).to(device) # latent[0] for both color and structrue transfer and latent[1] for only structrue transfer latent[1,7:18] = instyle[0,7:18] exstyle = generator.generator.style(latent.reshape(latent.shape[0]*latent.shape[1], latent.shape[2])).reshape(latent.shape) img_gen, _ = generator([instyle.repeat(2,1,1)], exstyle, z_plus_latent=True, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[1]*11) img_gen = torch.clamp(img_gen.detach(), -1, 1) # deactivate color-related layers by setting w_c = 0 img_gen2, _ = generator([instyle], exstyle[0:1], z_plus_latent=True, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[0]*11) img_gen2 = torch.clamp(img_gen2.detach(), -1, 1) vis = torchvision.utils.make_grid(F.adaptive_avg_pool2d(torch.cat([img_rec, img_gen, img_gen2], dim=0), 256), 4, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

左から、pSpの反転画像、色と構造の両方のスタイル転送、スタイルのカラーをコンテンツのカラーに置き換えたもの、色に関連するレイヤを非アクティブ化したものです。
それでは、色と構造のスタイル転送の度合いを、それぞれ6段階に変更した場合の画像をマトリックスで表現してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#@title 色と構造のスタイル転送マトリックス results = [] for i in range(6): # change weights of structure codes for j in range(6): # change weights of color codes w = [i/5.0]*7+[j/5.0]*11 img_gen, _ = generator([instyle], exstyle[0:1], z_plus_latent=True, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=w) img_gen = torch.clamp(F.adaptive_avg_pool2d(img_gen.detach(), 128), -1, 1) results += [img_gen] vis = torchvision.utils.make_grid(torch.cat(results, dim=0), 6, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

今度は、コンテンツが同一でスタイルが異なる画像のトランジションをやってみましょう。追加のスタイルを選択します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#@title 新たなスタイルの選択 style_id2 = 82 #@param {type:"slider", min:0, max:317, step:1} # try to load the style image stylename2 = list(exstyles.keys())[style_id2] stylepath = os.path.join(DATA_DIR, style_type, 'images/train', stylename2) print('loading %s'%stylepath) if os.path.exists(stylepath): S = load_image(stylepath) plt.figure(figsize=(10,10),dpi=30) visualize(S[0]) plt.show() else: print('%s is not found'%stylename2) |

トランジションを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#@title トランジション with torch.no_grad(): latent = torch.tensor(exstyles[stylename]).repeat(6,1,1).to(device) latent2 = torch.tensor(exstyles[stylename2]).repeat(6,1,1).to(device) fuse_weight = torch.arange(6).reshape(6,1,1).to(device) / 5.0 fuse_latent = latent * fuse_weight + latent2 * (1-fuse_weight) exstyle = generator.generator.style(fuse_latent.reshape(fuse_latent.shape[0]*fuse_latent.shape[1], fuse_latent.shape[2])).reshape(fuse_latent.shape) img_gen, _ = generator([instyle.repeat(6,1,1)], exstyle, z_plus_latent=True, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[1]*11) img_gen = F.adaptive_avg_pool2d(torch.clamp(img_gen.detach(), -1, 1), 128) vis = torchvision.utils.make_grid(img_gen, 6, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

次に、コンテンツとスタイルを乱数で指定したサンプルを表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#@title コンテンツとスタイルを乱数で指定 seed = 123 torch.manual_seed(seed) batch = 6 # sample 6 style codes with torch.no_grad(): instyle = torch.randn(6, 512).to(device) # sample structure codes res_in = icpts.icp.netT(torch.randn(batch, 128).to(device)).reshape(-1,7,512) # sample color codes ada_in = icptc.icp.netT(torch.randn(batch, 128).to(device)).reshape(-1,11,512) # concatenate two codes to form the complete extrinsic style code latent = torch.cat((res_in, ada_in), dim=1) # map into W+ space exstyle = generator.generator.style(latent.reshape(latent.shape[0]*latent.shape[1], latent.shape[2])).reshape(latent.shape) with torch.no_grad(): img_gen, _ = generator([instyle], exstyle, input_is_latent=False, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[1]*11) img_gen = F.adaptive_avg_pool2d(torch.clamp(img_gen.detach(), -1, 1), 128) vis = torchvision.utils.make_grid(img_gen, batch, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

スタイルを左から5番目の画像に合わせて一定にします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#@title スタイル一定 with torch.no_grad(): img_gen, _ = generator([instyle], exstyle[4:5].repeat(batch, 1, 1), input_is_latent=False, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[1]*11) img_gen = F.adaptive_avg_pool2d(torch.clamp(img_gen.detach(), -1, 1), 128) vis = torchvision.utils.make_grid(img_gen, batch, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

コンテンツを左から5番目の画像に合わせて一定にします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#@title コンテンツ一定 with torch.no_grad(): img_gen, _ = generator([instyle[4:5].repeat(batch,1)], exstyle, input_is_latent=False, truncation=0.7, truncation_latent=0, use_res=True, interp_weights=[0.6]*7+[1]*11) img_gen = F.adaptive_avg_pool2d(torch.clamp(img_gen.detach(), -1, 1), 128) vis = torchvision.utils.make_grid(img_gen, batch, 1) plt.figure(figsize=(10,10),dpi=120) visualize(vis.cpu()) plt.show() |

では、また。
(オリジナルgithub)https://github.com/williamyang1991/DualStyleGAN
(twitter投稿)













新しい、論文を次々と試されていてすごいと思います。この論文は私が1月ごろに実装した機能と原理はほぼ同じなのかなと。以下のURLから操作可能です。ページ中央のStyle Layerの横にあるスラーイダーで、色、顔、ポーズの3つに分類したレイヤーの範囲や位置を自由に動かして同時にMIXできます。スライダーを有効にるるには左横にある色、顔、ポーズの文字をクリック(色が変わる)する必要があり、その後、スライダーを移動させると選択されているスライダーで指定したレイヤーすべてがmixされた画像が8枚生成されます。
モデル選択機能もありますが、まだ学習が不十分であったり、データセットがダーティーなものもあり現在テスト段階なのでIPアドレスにドメインをリンクさせていません。大幅にリニューアルを予定しているところです。
同じ考え方の論文が出てきてびっくりしています。これからも有益な情報、よろしくお願いします。
URL:http://39.110.248.73
Topページ左側です。
上野さん
えー、凄いじゃないですか、これCVPR2022の採択論文なんですが、それより実装が早かったわけですね。
Deep Learningの世界はジャーナル誌や査読なんて言うかったるいプロセスはないので、思いっきりやっちゃって下さい!
応援してます。