
1.はじめに
以前、StyleGANを使った画像編集[1][2]についてご紹介しましたが、このとき時間が掛かるのが「潜在変数の推定」プロセスでした。今回は、このプロセスを高速に実行できる e4e(encoder4editing)という技術をご紹介します。
*この論文は、2021年2月に提出されました。
2.e4eとは?
潜在変数を推定するアプローチには2つの方法があります。1つはある潜在変数をStyleGANに入力して得た画像と目的の画像の誤差を最小化するようなループを廻して潜在変数を推定する方法、もう1つは画像を入力すると目的の潜在変数を直接出力する専用エンコーダを作る方法です。
ループを廻して潜在変数を推定する方法は、画像毎に行うため比較的精度は高いですが時間が掛かります。一方、今回ご紹介する、専用エンコーダを使う方法 e4e は、精度は若干落ちますが推定速度が圧倒的に早いのが特徴です。
以下に、e4eの学習時のフローを示します。
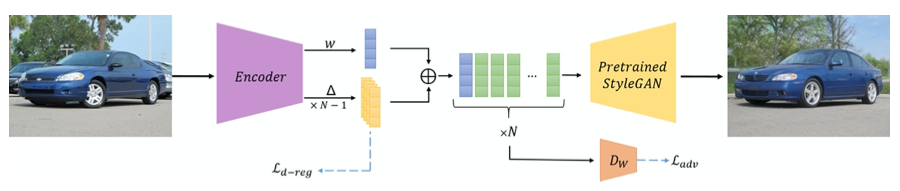
Encoderに画像を入力すると、1つの潜在変数 w とN個のオフセット△が出力され、これらを合成してN個の潜在変数(FFHQの場合はN=18)とし、Pretrained StyleGAN に入力します。
このとき、元画像と出力画像の誤差を表すロスに加えて、オフセットの分散(バラツキ)を表すロスを設定し、これら2つのロスの合計を最小化するように、Encoder のパラメータを学習します。オフセットの分散を減らすのは、推定した潜在変数の歪みを減らし画像の編集性を向上させるためです。
それでは、実際にコードを動かしてみましょう。
3.セットアップ
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# --- セットアップ --- import os os.chdir('/content') CODE_DIR = 'encoder4editing' !git clone https://github.com/cedro3/encoder4editing.git $CODE_DIR !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force os.chdir(f'./{CODE_DIR}') from argparse import Namespace import time import os import sys import numpy as np from PIL import Image import torch import torchvision.transforms as transforms sys.path.append(".") sys.path.append("..") from utils.common import tensor2im from models.psp import pSp # we use the pSp framework to load the e4e encoder. %load_ext autoreload %autoreload 2 # 学習済みパラメータのダウンロード import os import gdown os.makedirs('pretrained_models', exist_ok=True) gdown.download('https://drive.google.com/u/0/uc?id=1cUv_reLE6k3604or78EranS7XzuVMWeO', 'pretrained_models/e4e_ffhq_encode.pt', quiet=False) # ランドマークデータのダウンロード ! wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2 ! bzip2 -dk shape_predictor_68_face_landmarks.dat.bz2 # モデルに学習済みパラメータをロード model_path = 'pretrained_models/e4e_ffhq_encode.pt' #### ckpt = torch.load(model_path, map_location='cpu') opts = ckpt['opts'] opts['checkpoint_path'] = model_path opts= Namespace(**opts) net = pSp(opts) net.eval() net.cuda() print('Model successfully loaded!') |
4.事前準備
./images にある、事前に用意したサンプル画像は、以下の5枚です。ご自分が用意した顔画像があれば、このフォルダに追加(PC画面からドラッグ&ドロップでOKです)して下さい。

StyleGANが学習した顔画像は、顔のランドマーク(目・鼻・口など)が所定の位置に合わせてあるものが使われています。そのため、潜在変数を推定する場合も、それと同じようになるようにサンプル画像から顔を切り出します。顔を切り出した画像は、./images と同じファイル名で ./align に保存されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# --- 顔画像の切り出し --- import os import shutil from tqdm import tqdm if os.path.isdir('align'): shutil.rmtree('align') os.makedirs('align', exist_ok=True) def run_alignment(image_path): import dlib from utils.alignment import align_face predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") aligned_image = align_face(filepath=image_path, predictor=predictor) return aligned_image path = './images' files = sorted(os.listdir(path)) for i, file in enumerate(tqdm(files)): if file=='.ipynb_checkpoints': continue input_image = run_alignment(path+'/'+file) input_image.resize((256,256)) input_image.save('./align/'+file) |
次に、切り出した顔画像から潜在変数を推定します。エンコーダ方式なので、あっと言う間に完了します(顔の切り出しスピードより遥かに早いです)。推定した潜在変数は、./align と同じファイル名(拡張子はjpg → pt)で ./vec に保存されます。潜在変数から生成した画像は、./align と同じファイル名で ./vec_pic に保存されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# --- 潜在変数の推定 --- if os.path.isdir('vec_pic'): shutil.rmtree('vec_pic') os.makedirs('vec_pic', exist_ok=True) if os.path.isdir('vec'): shutil.rmtree('vec') os.makedirs('vec', exist_ok=True) img_transforms = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) path = './align' files = sorted(os.listdir(path)) for i, file in enumerate(tqdm(files)): if file=='.ipynb_checkpoints': continue input_image = Image.open(path+'/'+file) transformed_image = img_transforms(input_image) with torch.no_grad(): images, latents = net(transformed_image.unsqueeze(0).to('cuda').float(), randomize_noise=False, return_latents=True) result_image, latent = images[0], latents[0] tensor2im(result_image).save('./vec_pic/'+file) # vec_pic 保存 torch.save(latents, './vec/'+file[:-4]+'.pt') # vec 保存 |
それでは、「切り出した顔画像」と「潜在変数から生成した顔画像」を並べて表示し、そのクオリティを比較してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# --- 元画像と生成画像の表示 --- import matplotlib.pyplot as plt from PIL import Image import os def display_pic(folder): fig = plt.figure(figsize=(30, 40)) files = os.listdir(folder) files.sort() for i, file in enumerate(files): img = Image.open(folder+'/'+file) images = np.asarray(img) ax = fig.add_subplot(10, 10, i+1, xticks=[], yticks=[]) image_plt = np.array(images) ax.imshow(image_plt) ax.set_xlabel(folder+'/'+file, fontsize=15) plt.show() plt.close() display_pic('align') display_pic('vec_pic') |

上段が切り出した顔画像、下段が潜在変数から生成した画像です。完全に同じという訳には行きませんが、切り出した顔画像とほぼ同じ画像を生成できる潜在変数が素早く推定できたことが分かります。これで、編集できる潜在変数が手に入りました。
5.編集
編集のために用意した潜在変数は、./editings/interfacegan_directions にあり以下の4つです。
age.pt: 年齢による顔の変化pose.pt: 顔の水平方向の回転smile.pt: 笑顔にするage+pose.pt: 年齢による顔の変化+顔の水平方向の回転
03.jpg を以下の設定で編集します。latent は対応する潜在変数 03.pt 、direction は年齢による顔の変化の潜在変数 age 、min は-50、max は50です。これは、潜在変数 03.pt に 潜在変数 age の-5 〜 5 倍(設定は内部で1/10されます)したものを加算して、StyleGANに入力し画像を生成するという設定です。

潜在変数 age に掛ける数字を少しづつ変化させながら、StyleGANが出力する静止画を保存します。まず 0からmin まで変化させ、次に minからmax まで変化させ、最後に maxから0 まで変化させます。静止画は、000001.jpg という形の6桁の連番名で ./pic に保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# --- 静止画の生成 --- import os import shutil if os.path.isdir('pic'): shutil.rmtree('pic') os.makedirs('pic', exist_ok=True) from editings import latent_editor from tqdm import trange folder = 'vec' latents = torch.load(folder+'/'+latent) editor = latent_editor.LatentEditor(net.decoder, False) interfacegan_directions = { 'age': 'editings/interfacegan_directions/age.pt', 'smile': 'editings/interfacegan_directions/smile.pt', 'pose': 'editings/interfacegan_directions/pose.pt', 'age+pose': 'editings/interfacegan_directions/age+pose.pt' } interfacegan_direction = torch.load(interfacegan_directions[direction]).cuda() cnt = 0 for i in trange(0, min, -1, desc='0 -> min'): result = editor.apply_interfacegan(latents, interfacegan_direction, factor=i).resize((512,512)) result.save('./pic/'+str(cnt).zfill(6)+'.jpg') cnt +=1 for i in trange(min, max, desc='min -> max'): result = editor.apply_interfacegan(latents, interfacegan_direction, factor=i).resize((512,512)) result.save('./pic/'+str(cnt).zfill(6)+'.jpg') cnt +=1 for i in trange(max, 0, -1, desc='max -> 0'): result = editor.apply_interfacegan(latents, interfacegan_direction, factor=i).resize((512,512)) result.save('./pic/'+str(cnt).zfill(6)+'.jpg') cnt +=1 |
./pic に保存された静止画からmp4動画を作成します。作成された動画は、output.mp4 で保存すると共に、./movie に age_03.mp4 という形で保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# --- mp4動画の作成 --- # 既に output.mp4 があれば削除する import os if os.path.exists('./output.mp4'): os.remove('./output.mp4') # pic フォルダーの静止画から動画を作成 ! ffmpeg -r 30 -i pic/%6d.jpg\ -vcodec libx264 -pix_fmt yuv420p output.mp4 # movieフォルダへ名前を付けてコピー import shutil os.makedirs('movie', exist_ok=True) shutil.copy('output.mp4', 'movie/'+direction+'_'+latent[:-3]+'.mp4') |
作成した、output.mp4 を再生します。
|
1 2 3 4 5 6 7 8 9 10 |
# --- mp4動画の再生 --- from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |

子供の顔からおばあちゃんの顔まで連続的に変化する動画が出来ました。
後は、「編集」以降を繰り返せばOKです。違う設定でやってみましょう。今度は、潜在変数 01.pt に 潜在変数 pose を使って編集してみましょう。


今度は、潜在変数 02.pt に潜在変数 smile を使って編集してみましょう。smile の場合は、少し弱目にした方が良いので、min 0 、max 30 にしています。


最後に、潜在変数 05.pt に 潜在変数 age+pose で編集してみましょう。これは年齢の変化と顔の回転が同時に編集できます。


では、また。
(Twitterへの投稿)














最初のセルでエラーが起きます
Filenotfoundみたいなのが出てくる
田中さん
コメントありがとうございます。
これは失礼しました。学習済みパラメータのダウンロードが上手くいっていなかったのが原因でした。リンク先を変更しましたので、もうOKです。
お楽しみ下さい。
釈迦に説法だと思うので恐縮ですが, 潜在変数空間上の属性ベクトル同士が必ずしも直交せず, ageを変化させるとglassも変化してしまうみたいな現象はInterFaceGANという論文で議論されています.変化させたくない属性ベクトルに対して並行に変化させることである程度抑制できるみたいです.
https://arxiv.org/pdf/2005.09635.pdf <- Fig.2を参照
しゅーとさん
情報ありがとうございます!