
謎のサンプルデータセット
こんにちはcedroです。
みなさん、SONY Neural Network Console の sample_dataset フォルダーの中を覗いたことはありますか。
そこにはお馴染みのMNISTの他に、iris_flower_dataset と random というフォルダーがあるんですが、今回は iris_flower_dataset の方のお話です。
最初このフォルダーを見つけた時は、「おーっ、SONYさんこんなところに flower なんて、花の画像を隠してるやん。」
「そういや、デモの動画でも、花の画像チラッと出してはったしなあ。どれどれ。」と思って、ワクワクしながら学習ファイルとおぼしき iris_flower_dataset_training_delo.を読み込んでみると。。。。

「なんやこれー。数字だけ並んでるだけで、なんの意味なのかさっぱりわからへん」とガッカリ。早々に、読み込んだデータセットは消して、すぐ忘れてしまいました。
それから2週間ほど経ったある日、ふとまたあのデータセットを思い出しました。
あれな、きっと意味あるぞ。わざとDATASETに登録せずに、フォルダーに放置してあるやんか。
あれな、気づけるもんなら気づいてみーちゅう、開発者の遊びやできっと。
エセ関西弁で、すいません。。。。
というわけで、今回は iris_flower_dataset の謎に迫りたいと思います。
80年前から蘇った有名なデータセット
謎は簡単に解けました。
iris flower data set とググったら、一番先頭に英語版ウイキペディアの iris flower data set がヒット。英語は不得意なので、「このページを訳す」をクリックして日本語訳にすると、
アイリスの花のデータセットまたはフィッシャーのアイリスのデータセットは、英国の統計 学者で生物学者 ロナルドフィッシャーが1936年の論文で導入した多変量 データセットです。 線形判別分析の一例として分類問題の複数の測定の使用 。 Edgar Andersonは3種の関連種の虹彩花の形態変化を定量化するためのデータを収集したので、 AndersonのIrisデータセットと呼ばれることがあります。 [2] 3種のうち2種はガペ半島で集められ、「同じ牧草地から集められ、同じ日に採取され、同じ装置で同じ人が同時に測定する」。 [3]
なんと iris flower data set は、今から80年前に、ロナルドフィッシャーという学者がやった実験の生データなんです。
しかも、驚くことに、その生データが英語版のウイキベテアにそのまま載っているんです。これって、学者冥利に尽きる出来事じゃないでしょうか。

iris flower というは「アヤメ」なんです。
データの x0はsepal(がく)の長さ、x1はsepal(がく)の 幅、x2はpetal (花びら)の長さ、x3はpetal (花びら)の幅、をそれぞれcm単位で表しています。
そして、y:labelは花の種類を表していて、0は セトナ(setosa)、1は バーシクル(versicolor)、2は バージニカ(virginica)という種類 です。
こういうことを調べてから、改めてデータセットを眺めてみると、なにやらロマンを感じて来ました(笑)。
サンプルデータセットを動かしてみる
では、早速プロジェクトを作成して、サンプルデータセットを動かしてみましょう。
事前に、DATA SET画面で、iris_flower_dataset_training_delo.csv(学習ファイル)とiris_flower_dataset_Validation_delo.csv(評価ファイル)を登録しておきます。
流用するプロジェクトは、binary_connect_minst_MLP.sdcprojです。
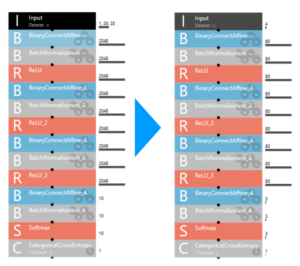
EDIT画面で、パラメーターを修正します。
INPUTは、画像でも行列でもなく、単に変数が4つなので、1,28,28 → 4
途中の2048のパラメーターは全部、2048 → 80 (適当です。どうせ後で自動最適化するので)
下から2〜4段目、10 → 3 (10分類のままでも動きますが、3分類にした方が安定性が増します)
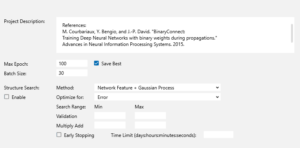
CONFIG画面で、評価データが30個しかないので Batch Sizeは30、Max Epochは100とします。
学習ファイルと評価ファイルをMNISTから入れ替えたら、さあ学習スタートです。
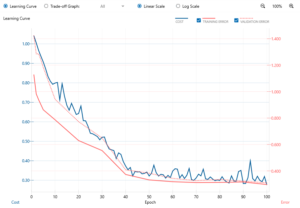
学習はあっと言う間に終わり、学習誤差も評価誤差も同じ様に低減しています。過学習の心配もない様です。
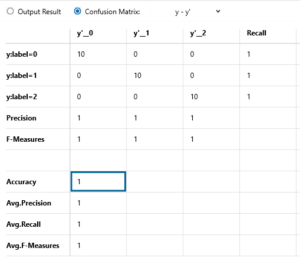
評価結果は、精度100%! なんとパーフェクトです。
自動最適化の必要もなし。
まあ、80年前に作成された、シンプルな線形分類のためのデータセットですからね。最新の SONY Neural Network Console に掛かれば、朝飯前という感じでしょうか。
オリジナルデータでもやってみる
今回、発見はもう1つあって、行列データでなく変数データであれば、データセットを作るのがメッチャ簡単だと言うこと。
行列データだと1個1個の行列データのファイルを作って、さらにその行列データのファイル名とラベルを対照させる学習ファイルと評価ファイルを作らないといけませんでした(日経平均をディープラーニングを参照)。
しかし、単なる変数であれば、変数の値を学習ファイルと評価ファイルに直接書いてしまえばいいわけです。
実際に自分でもオリジナデータを作ってみます。
テーマは女性の分類。
変数は身長、バスト、ウエスト、ヒップの4つ。種類は、国民的美少女、ポルノ女優、モデル女優の3種類(おいおい)。
急に80年前のロマンを感じる高尚な話から下世話な話にレベルが落ちてしまいました(笑)。
一応、備忘録でデータソースも書いておきますね。

国民的美少女:第15回全日本国民的美少女コンテスト 本選出場者 (N0.1~20)

ポルノ女優:世界の美女年鑑/ペントハウスペット (表示順から20名)

モデル女優:海外モデル女優人気ランキングTOP30 (1位~20位)

3つのグループの各変数を平均値でみると、国民的美少女は身長・スリーサイズとも抜きんでて小さいです(当たり前ですね)。そして、モデル女優とポルノ女優を比べると、モデル女優は身長が高くスリーサイズは若干小さ目。これなら上手く分類できそうです。
集めるデータ数は各20個×3種類=60個。これを学習に48個(80%)、評価に12個(20%)に振り分けます。
いつも少なくてすいません(笑)。
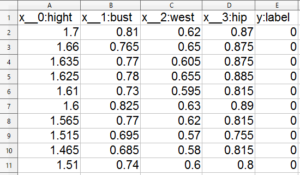
用意する学習ファイルと評価ファイルは、こんな形。データは概ね+1~-1にしないといけないので、cm単位のデータを1/100しています。
学習ファイルと評価ファイルに直接変数の値を書き込むので、CSVファイルはたった2つ作るだけで済みます。
注意して欲しいことは、マニュアルにも書いてありますが、1行目のXと数字の間にあるのは、ダブルアンダースコアだということです。
シングルアンダースコアだと、「変数Xが見つかりません」とエラーになります(私、実はこれでハマりました)。
なお、作成には、必ずOpenOfficeのCalcを使って、CSVファイルをUTF‐8で書き出して下さいね(EXCELはマクロを使わないと無理です)。
さて、先程作ったプロジェクトのデータセットだけ入れ替えて、学習スタートです。

iris flower data setと比べると、学習曲線がちょっと汚いですが、まあこんなもんでしょう。

評価結果は、こちらも精度100%でした。
変数だけのデータセットは簡単に作れるので、オリジナルデータをちょっと試して見るには、オススメです。
では、また。













コメントを残す