
1.はじめに
通常、GANでアニメキャラを生成するというと顔のみです。しかし、今回ご紹介するのは、なんとアニメキャラの上半身を生成するGANです。
2.手法
先週、AIアーティストAydaoさん(@AydaoAI)が作成したGANモデルを使った、This Anime Does Not Exist というHPが公開されました。このHPでは、GANを使って、この世界に存在しないアニメキャラクターを生成することが出来ます。
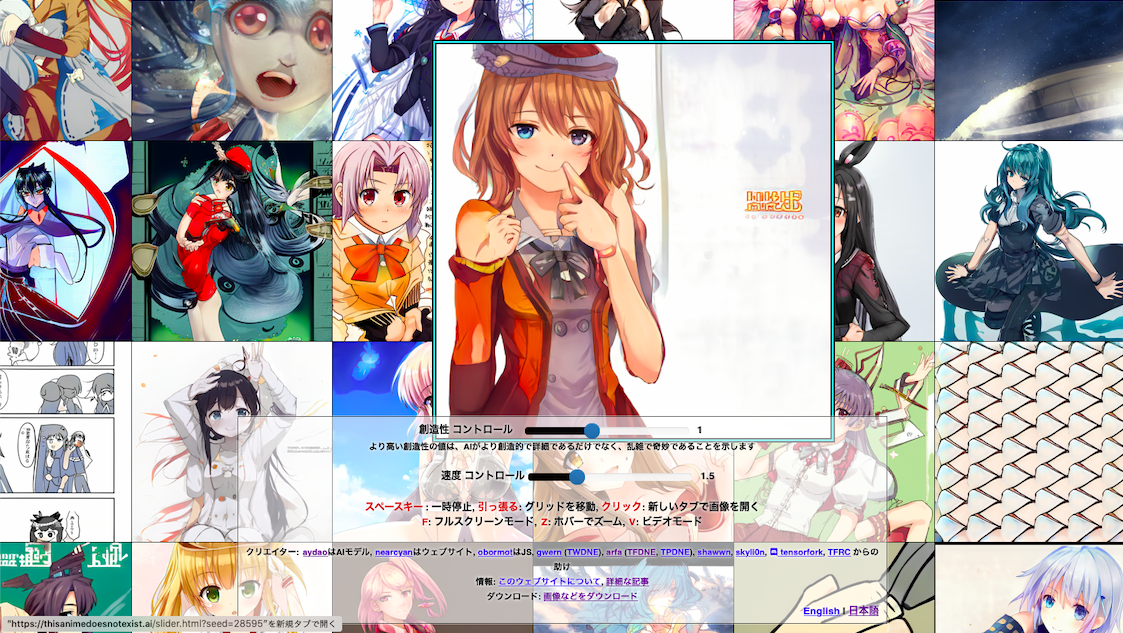
HPを開くと、この様に画面一杯にアニメキャラクターがスクロールする形で生成されます。そして、生成するときの創造性(Creativity)と画面のスクロール速度(Speed)をスライダーで設定出来ます。
GANをちょっとでも触ってみた人であれば、顔だけでなく上半身を画像生成することがどれほど大変なことか直ぐ分かると思います。Aydaoさんは、これを STyleGAN2を使い、膨大な学習データと転移学習・拡張によって実現しています。凄い!!!
Aydaoさんの作ったモデルの学習済みの重みは公開されていますので、今回はそれを元に Google Colab でAydaoワールドを覗いてみたいと思います。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
最初に、tensorflow1.15.0 を動かすために必要な cuda10.0 をインストールします(2022.10よりgoogle colab からcuda10.0が削除されたため)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title install cuda10.0 # download data !wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !rm /etc/apt/sources.list.d/cuda.list !sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub !sudo apt-get update !wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt install -y ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt-get update # install NVIDIA driver !sudo apt-get -y installnvidia-driver-418 # install cuda10.0 !sudo apt-get install -y \ cuda-10-0 \ libcudnn7=7.6.2.24-1+cuda10.0 \ libcudnn7-dev=7.6.2.24-1+cuda10.0 # install TensorRT !sudo apt-get install -y libnvinfer5=5.1.5-1+cuda10.0 \ libnvinfer-dev=5.1.5-1+cuda10.0 !apt --fix-broken install |
まず、セットアップを行います。
|
1 2 |
# github からコードをコピー !git clone https://github.com/cedro3/stylegan2.git |
|
1 2 3 |
# 学習済みの重みのダウンロード import gdown gdown.download('https://drive.google.com/u/1/uc?id=1_NUX9_xRGjce1KbCxT4frUsFWctlN4ZC', 'network-tadne.pkl', quiet=False) |
|
1 2 3 4 5 |
# TensorFlow_plugin セッティングと関数定義 !pip install tensorflow==1.15.0 !pip install imageio==2.4.1 %cd /content/stylegan2 from function import * |
次に、seedで指定した2枚の画像をブレンドした画像を生成してみましょう。seed は整数であれば何でもかまいません。
blending = 0.5 はブレンドするときの src_seed の比率です。 truncation_psi = 0.8 は画像を生成するときに学習画像からどれだけ離すか(創造的か)の設定です。
|
1 2 3 4 5 6 7 8 9 |
# seedで指定した2枚の画像をブレンドした画像を生成する src_seed = 6677 dst_seed = 7561 blending = 0.5 truncation_psi = 0.8 generate_images([src_seed, dst_seed], truncation_psi) print("Blended image (", blending, ")") blend_images(src_seed, dst_seed, blending=blending, truncation_psi=truncation_psi) |

「清楚なお嬢さん」と「ワイルドなお姉さん」を50:50でブレンドすると、「ワイルドなお嬢さん」が出来上がります。
次に、seedで指定した2枚の画像をモーフィングする動画を生成してみます。duration_sec = 5.0 は モーフィング時間(sec)、mp4_fps = 20 は動画のフレームレートです。
|
1 2 3 4 5 6 7 8 9 |
# seedで指定した2枚の画像をモーフィングする動画を生成する src_seed = 5126 dst_seed = 5805 truncation_psi = 0.7 duration_sec = 5.0 mp4_fps = 20 generate_images([src_seed, dst_seed], truncation_psi) output_filename = interpolate_between_seeds(seed_array=[src_seed, dst_seed], truncation=truncation_psi, duration_sec=duration_sec, mp4_fps=mp4_fps) |

|
1 2 |
# 生成した動画を再生する display_mp4(output_filename) |
2枚の画像の完成度が高いだけでなく、その中間画像も連続的で綺麗なことが分かります。
最後に、創造性に関係する truncation_psi をもっと大きく(最大2.0)して、ランダムにグリッドでモーフィングする画像を生成してみましょう。ここで、random_seed は乱数の系列を表します。
grid_width = 2 はグリッドの横の大きさ、grid_height = 2はグリッドの高さの設定です。 (ちなみに、grid_width = 1, grid_height = 1 だと動画を1つだけ生成します)
|
1 2 3 4 5 6 7 8 |
# ランダムにグリッドでモーフィング画像を生成する random_seed = 822 duration_sec = 5 mp4_fps = 30 grid_width = 2 grid_height = 2 output_filename = make_video(grid_size=[grid_width,grid_height], duration_sec=duration_sec, mp4_fps=mp4_fps, random_seed=random_seed) |
|
1 2 |
# 生成した動画を再生する display_mp4(output_filename) |
モーフィングの途中でtruncation_psi を大きくしているので、より創造的な(変化の大きい)画像が生成されていることが分かります。また、学習データの中には、漫画のコマ割りの様なデータも含まれているようです。random_seed の数字を色々変えて楽しんでみて下さい。
それにしても、Aydao ワールド、魅力的過ぎます。もう現実に戻って来れないかも。。。。
では、また。
twitterへの投稿














任意の画像をアップロードし読み込ませることは可能でしょうか。
二次元三次元問わず、任意の画像をアップロードしモーフィングさせる方法をご存じでしたらお教えいただけますと幸いです。
桜田ふぁみりあさん
コメントありがとうございます。
顔画像であれば、「GANの潜在空間に新垣結衣は住んでいるのか?」で画像を潜在変数にし、「StyleGAN2を使って顔画像の編集をやってみる」でモーフイングが作成できます。
cedro様
ご返信ありがとうございます。
「BigGAN TF Hub を使ってモーフィング動画を自動で作ってみる」のように、顔画像に限らないノージャンルのモーフィングをcolabなどで手軽に作成することはできますか。
桜田ふぁみりあさん
コメントありがとうございます。
私のブログではカバーしていませんが、StyleGANでもベッドルームとか車とか猫とかジャンルを絞れば可能です。BigGANはあまり画質が良くないですが学習した1000ジャンルの範囲であれば原理的に可能だと思います。いずれの場合でも顔画像と同様に潜在変数を求めて、モーフィングをかければOKです。
cedro様
毎度返信いただきありがとうございます。とても勉強になります。
質問ばかりで申し訳ないのですが、よろしければもう一つ教えてください。
「膨大な学習データと転移学習・拡張によって実現」された「Aydaoさんの作ったモデルの学習済みの重み」を用いて、
自分で用意した画像を与え転移学習させてみたいのですが、その方法について少し調べてみたものの道筋が朧気です。
本記事のプログラムを利用するなどの具体的な手順、そもそも可能なのかを含め助言いただけないでしょうか。
桜田ふぁみりあさん
コメントありがとうございます。
Aydaoさんの行った転移学習・拡張の詳細について知りたい場合は、このリンク [https://www.gwern.net/Faces#extended-stylegan2-danbooru2019-aydao] を読んでみて下さい。
それを元に、トライされてみてはいかがでしょうか。実現の可能性はあると思います。
自分でアニメ画像を用意して、そのアニメ画像に近い画像を潜在空間から探し出したいのですが、どうしたらよいでしょうか?
別記事「GANの潜在空間に新垣結衣は住んでいるのか?」で行っていることをアニメ画像でやるイメージです。
プニさん
ご覧いただいたアニメ生成モデルは、通常の方法では潜在変数が見つけにくいので、CLIPを利用してテキストで潜在変数を見つけるコラボをご紹介します。下記リンクです。
https://colab.research.google.com/github/nagolinc/notebooks/blob/main/CLIP_%2B_TADNE_(pytorch)_v2.ipynb
cedro様
はじめまして。2点お聞きしたいことがあり、ご連絡いたしました。
1.
2枚の画像(seedを指定)をブレンドされておりますが、
1枚はseedで指定、もう一枚は実際の画像をアップロードしてブレンドすることは可能でしょうか?
2.
2枚ではなく、複数枚の画像をブレンドすることも可能でしょうか?
まだまだ勉強不足で頓珍漢な質問をしていたら大変申し訳ございません。
プログラミング初心者さん
1.について
ご覧いただいたアニメ生成モデルは、転移学習でかなり拡張されていますので、通常の方法では潜在変数が見つけにくいので、難しいです。
2.について
画像を生成するベクトルをある比率で平均すればいいので、複数枚の画像をブレンドすることは可能です。ただし、function.pyの中にある、関数generate_imagesの修正が必要です。
cedro様
ご回答ありがとうございます。
1のご回答に対してなのですが、seed指定はせずに2枚とも実際の画像アップロードしてブレンドすることも難しいのでしょうか?
プログラミング初心者さん
ブレンドするためには、ブレンドしたい画像を生成する潜在変数を見つけて、その潜在変数をある比率で平均する必要があります。このアニメ生成モデル時は、転移学習でかなり拡張されていますので、「実際の画像から潜在変数を見つけることが難しい」です。