
1.はじめに
通常、姿勢推定などのタスクではヒートマップを使った回帰の手法を使いますが、今回ご紹介するのはヒートマップを使わずに姿勢推定を行うKapaoという技術です。
*この論文は、2021.11に提出されました。
2.Kapaoとは?
通常、姿勢推定などのタスクではヒートマップを使った回帰のアプローチを取りますが、生成と後処理に大量の計算処理が必要です。
Kapao(Keypoints and Poses as Objects)は、もっと処理効率を上げるために、画像を細かなグリッドに分割して、人間のポーズオブジェクトとキーポイントオブジェクトを同時に検出・融合し姿勢推定を行います。
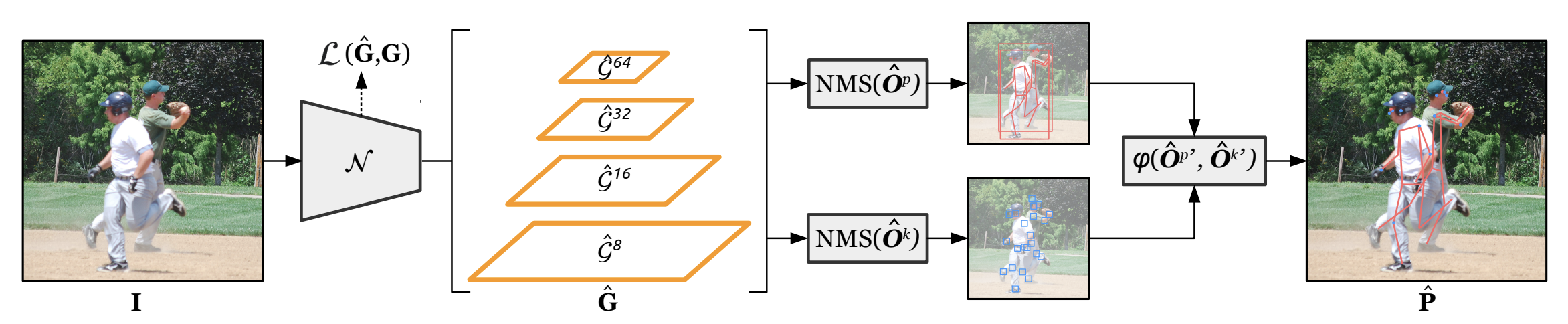
下記は、Kapaoのネットワークの概要です。入力画像を深い畳み込みネットワークでマッピングし、ポーズオブジェクトとキーポイントオブジェクトをそれぞれ検出した後、この2つの情報を融合し結果を得ています。
では、早速コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# githubからコードを取得 ! git clone https://github.com/cedro3/kapao.git %cd kapao # ライブラリー・インストール ! pip install torch==1.9.1 ! pip install torchvision==0.10.1 ! pip install pytube ! pip install imageio==2.4.1 ! pip install -r requirements.txt # 学習済みパラメータ・ダウンロード ! sh data/scripts/download_models.sh |
最初に、指定動画をYoutubeからダウンロードして変換するデモを demos/flash_mob.py を使って行います。–weights で学習済みパラメータの指定、–start で変換開始時間(秒)の指定、–end で変換終了時間(秒)の指定を行います。
|
1 2 |
# flash_mob_demo ! python demos/flash_mob.py --weights kapao_s_coco.pt --start 188 --end 196 |
作成された動画 flash_mob_inference_kapao_s_coco.mp4 のコーデックは MPEG4 Video で、このままでは扱いにくいので汎用性のあるコーデック H.264 に変換し flash_mob.mp4 で保存します。
|
1 2 |
# コーデック変換(MPEG-4 Video > H.264) ! ffmpeg -i flash_mob_inference_kapao_s_coco.mp4 -vcodec h264 -acodec mp3 flash_mob.mp4 |
動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 |
# 動画の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./flash_mob.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="70%" height="70%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
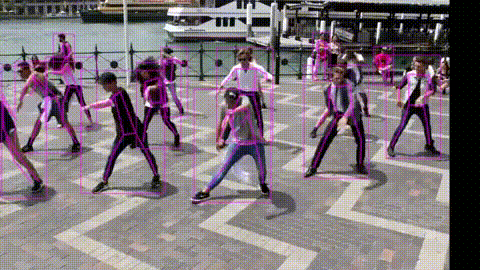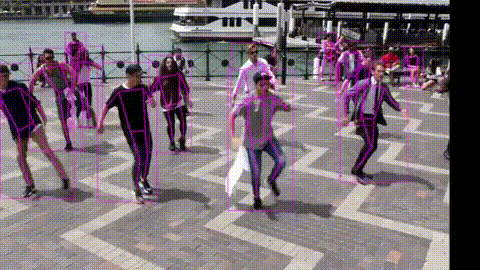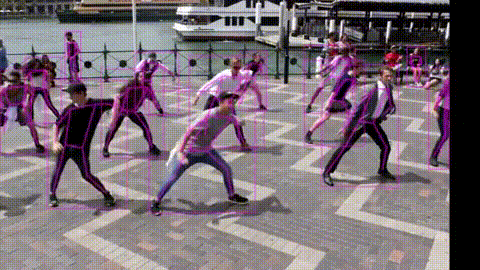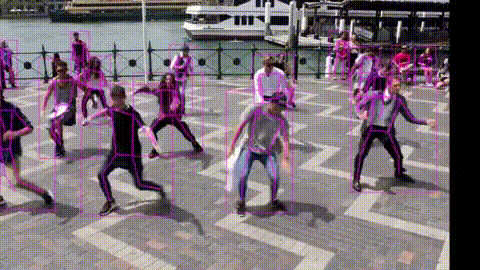
次に、movieフォルダーの動画を変換するデモを test.py を使って行います。–name で動画の指定、–weights で学習済みパラメータの指定、–start で変換開始時間(秒)の指定、–end で変換終了時間(秒)の指定を行います。
自分の動画でやりたい場合は、movieフォルダーに自分の動画をアップロードして、その動画を指定して下さい。
|
1 |
! python test.py --name './movie/sample.mp4' --weights kapao_s_coco.pt --start 0 --end 8 |
作成された動画 output.mp4 のコーデックは MPEG4 Video で、このままでは扱いにくいので汎用性のあるコーデック H.264 に変換し out.mp4 で保存します。
|
1 2 |
# コーデック変換(MPEG-4 Video > H.264) ! ffmpeg -i output.mp4 -vcodec h264 -acodec mp3 out.mp4 |
動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 |
# 動画の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./out.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="70%" height="70%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |

では、また。
(オリジナルgithub)https://github.com/wmcnally/kapao
2022.1 colabアップデート
リンク:https://github.com/cedro3/kapao/blob/master/kapao_latest.ipynb
(twitter投稿)














これって、AlphaPoseやOpenPoseと比べどれくらい処理が軽いでしょうか。
また、精度はどうですか?
ヒートマップを使わない事にメリット等はあるのでしょうか。
traceさん
論文では、KapaoをAlphaPoseやOpenposeと比較した場合、処理がどの程度早いかの記載はありませんが、シングルステージでは精度は確実に高いようです。
ヒートマップを使わないメリットは、後処理に関わる負担を軽減でき量子化誤差の影響を受けないことです。
返信ありがとうございます。
MMDの自動トレースに使ってみたいと思います。
数秒しか動画が作られないのはなぜでしょうか
9999みたいにせずに動画全部を処理したいです
traceさん
test.py は、–start で変換開始時間(秒)の指定、–end で変換終了時間(秒)の指定を行っていますので、そこを調整して下さい。
ありがとうございます。
やはり4秒間の動画になってしまいます。endは100にしています。
原因は分かりますか?
traceさん
残念ながら、こちらでは再現ができません。
—start はいくつでしょうか? —start 0 —end 100 になっていれば、100秒以内の長さの動画は全て変換されるはずです。
やはりエラーが出ます
Using device: cuda:0
/usr/local/lib/python3.7/dist-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Writing inference video: 45% 135/300 [00:09<00:11, 13.76it/s]
Traceback (most recent call last):
File "test.py", line 122, in
bboxes, poses, _, _, _ = post_process_batch(data, img, [], [[im0.shape[:2]]], person_dets, kp_dets)
File “/content/kapao/val.py”, line 108, in post_process_batch
kpd[:, :4] = scale_coords(imgs[si].shape[1:], kpd[:, :4], shape)
RuntimeError: unsupported operation: some elements of the input tensor and the written-to tensor refer to a single memory location. Please clone() the tensor before performing the operation.
エラーが発生して4秒になっているようです。
途中で止まっているっぽい感じです。
traceさん
変換開始4秒後にエラーが発生して停止するのであれば、ちょうど4秒後に姿勢検出を失敗する画像に出くわした事が考えられます。
エラーが発生した画像を確認してみて下さい。多分、姿勢推定が難しい画像になっていると思います。
endを20秒に設定したのですが、11秒で終わってしまいました。traceさんと同じメッセージが出ています。姿勢推定が難しい画像になっているのでしょうか?
Using device: cuda:0
/usr/local/lib/python3.7/dist-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Writing inference video: 57% 341/600 [00:29<00:22, 11.73it/s]
bravoastroさん
そうだと思います。Kapaoは姿勢推定に失敗するとエラーを起こして止まる設計になっているようです。姿勢推定に失敗したであろうシーンをチェックしてみて下さい。
サンプルソースありがとうございました。いろいろと動画試してみてうまく動きました。
推定したデータから良し悪しを測れるようになればいろいろと活用幅が広がりそうですね。
そういう推定結果データも出力できるものなんですかね?
ドイさん
現状は良し悪しの判定はできません。対象の教師データがあれば、そのデータと比較することで判定できるように見直すことはできると思います ^^