
今回は、 AutoEncoderを使ってKaggle のクレジットカード取引データのどれが詐欺かを見破ってみたいと思います。
こんにちは cedro です。
皆さん、クレジットカードを使っていますか。私は小銭を扱うのが面倒だしポイントも付くので、金額に関わらずスーパーでもコンビニでも使えるところは全てクレジットカードを使っています。
ところで、クレジットカードをよく見ると、本来秘密にしなければならない重要な情報がカードに印字されていて、写真に撮られて情報を盗まれたり、落として見知らぬ人に使われてしまう心配がありますよね。
何だか気になって色々調べて見ると、クレジットカードを使う時の様々なデータを常に監視して、過去の実例から怪しいパターンを見つけると、直ぐ本人に問合せしたり、取引停止にして詐欺を未然防止する仕組みがあるようです。
そうした中、クレジットカード取引の異常検知に使うデータセットがあの有名なコンペティションサイト Kaggle にあることを知り、ぜひ試してみたくなりました。
ということで、今回は、 AutoEncoderを使ってKaggle のクレジットカード取引データのどれが詐欺かを見破ってみたいと思います。
データセットを入手する
今回使うデータセットは、2013年9月の欧州のクレジットカードの取引データです。2日間で284,807件の取引があり、その中に492件詐欺行為が含まれています。
kaggle のサイトにあるCredit Card Fraud Detection からデータセットをダウンロードし、適当なフォルダー(creditフォルダーとしておきます)の中に dataフォルダーを作り、そこに保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import pandas as pd import matplotlib.pyplot as plt from pylab import rcParams rcParams['figure.figsize'] = 10, 6 ### Visualize dataset # pandasで csv_dataを読み込む data = pd.read_csv("data/creditcard.csv") # 各列の要約統計量を書く print(data.describe()) print() # クラス設定(1は異常、0は正常) frauds = data[data.Class == 1] normal = data[data.Class == 0] # frauds(Classが1) の場合の Amount列のみ書く print(frauds.Amount.describe()) print() # normal(Classが0)の場合の Amount列のみ書く print(normal.Amount.describe()) # ヒストグラムを描く data.hist(figsize = (20, 20)) plt.show ### Histgram of Amount f, (ax1, ax2) = plt.subplots(2, 1, sharex=True) f.suptitle('Histgram of Amount ') ax1.hist(frauds.Amount, bins = 5) ax1.set_title('Fraud') ax2.hist(normal.Amount, bins = 60) ax2.set_title('Normal') plt.xlabel('Amount ($)') plt.ylabel('frequency') plt.xlim((0, 20000)) plt.yscale('log') plt.show() ### Time vs Amount f, (ax1, ax2) = plt.subplots(2, 1, sharex=True) f.suptitle('Time vs Amount') ax1.scatter(frauds.Time, frauds.Amount) ax1.set_title('Fraud') ax2.scatter(normal.Time, normal.Amount) ax2.set_title('Normal') plt.xlabel('Time (in Seconds)') plt.ylabel('Amount') plt.show() |
データセットの内容を見るコードです。credit フォルダーの中でこのコードを実行します。
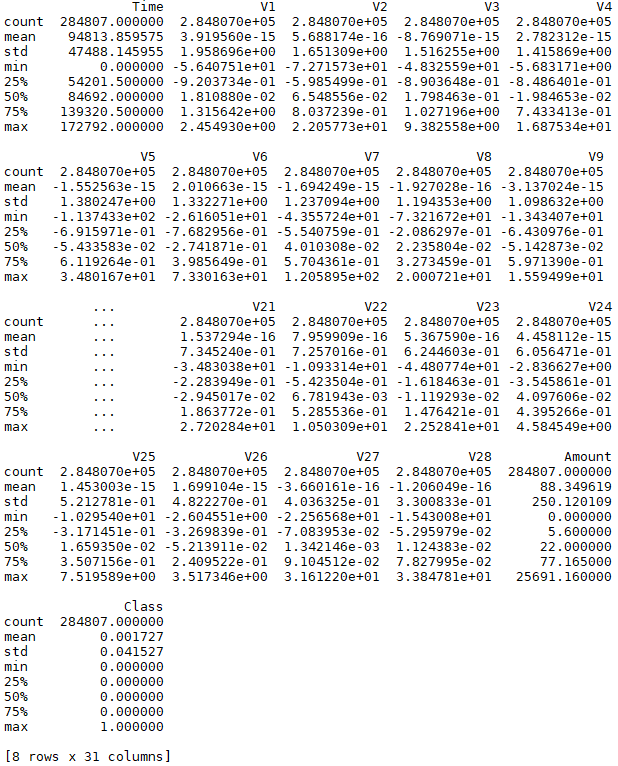
10行目で pandas でデータセットを読み込んだら、13行目の print( data.describe() ) だけで、全列の要約統計量(データ数、平均、標準偏差、最小値など)を一気に表示してくれます。pandas 便利!
項目は Time, V1〜V28, Amount, Class と全部で31項目あり、データ数は284807個です。Time は取引時間(秒)、Amountは取引金額(ドル)、Class は0が正常・1が異常を表しています。V1〜V28は、様々な取引状況のデータなのですが、どういう内容なのかは丸秘です。
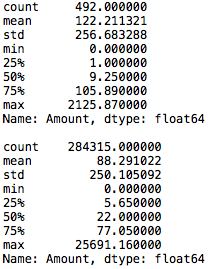
異常(Classが1)の場合と正常(Classが0)の場合のAmount 列です。17−24行目で表示します。異常の場合は492件あって最大金額は2125ドル、正常の場合は284315件あって最大金額25691ドルということが分かります。
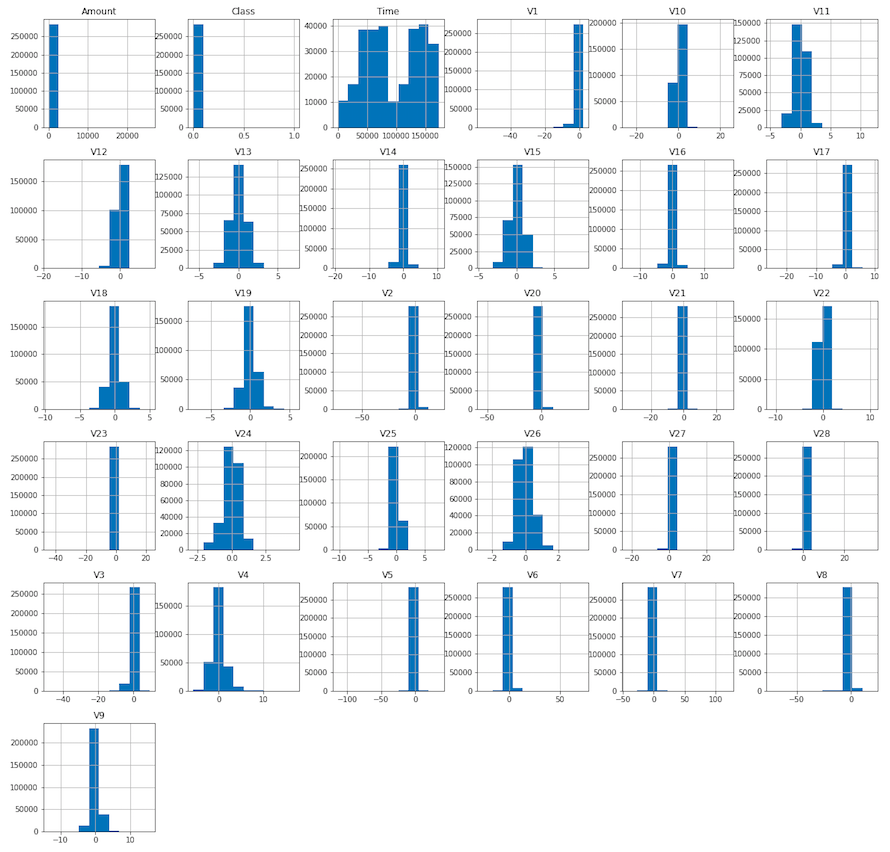
各列のヒストグラムです。27−28行目の data.hist( figsize = (20, 20) ) とplot.show() だけで表示できます。やっぱりpandas 凄い! 但し、表示順は実際の並びでなくアルファベット順です。
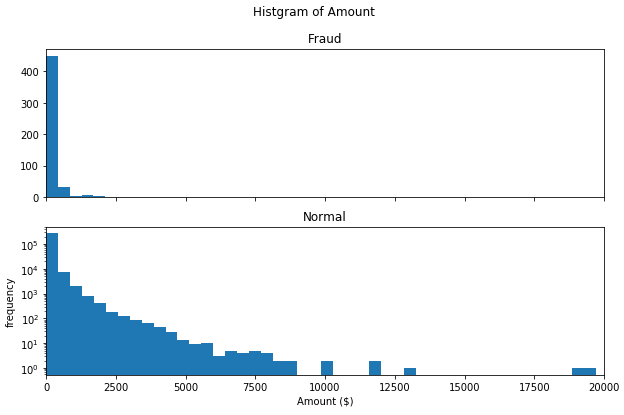
金額のヒストグラムです。33−45行目で表示します。異常(Fraud)の方が正常(Normal)より多額なのかと思いきや、むしろ少額ですね。一攫千金というよりは、目立たない様に少額で何回も使いたいということでしょうか。
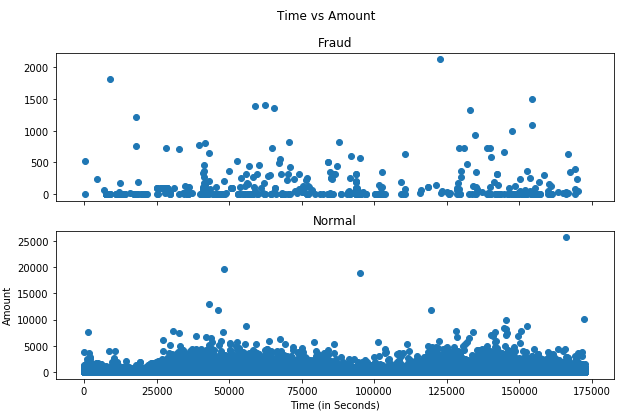
時間帯と金額の関係です。48−58行目で表示させます。時間の単位は秒で2日分のデータですので、横軸の最大は60秒×60分×24時間×2日=172800です。異常(Fraud)と正常(Normal)で差は特に無い様ですね。
AutoEncoderに学習させます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns from pylab import rcParams from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, MinMaxScaler from keras.models import Model, load_model from keras.layers import Input, Dense from keras.callbacks import ModelCheckpoint from keras import regularizers rcParams['figure.figsize'] = 10, 6 # True で学習する、 False で学習しない DO_TRANING = True ### データセットの前準備 # pandasで csv_dataを読み込む df = pd.read_csv("data/creditcard.csv") # Time列は影響なしとみてデータから外す data = df.drop(['Time'], axis=1) # dataをX_train と X_testに 8:2 で分割する X_train, X_test = train_test_split(data, test_size=0.2, random_state=42) # X_trainのデータは正常(Classが0)だけにする X_train = X_train[X_train.Class == 0] # y_testは X_testの Class列を使う y_test = X_test['Class'] # X_train, X_test のデータから Class列を外す X_train = X_train.drop(['Class'], axis=1) X_test = X_test.drop(['Class'], axis=1) # 標準化して numpy.ndarry 配列にする X_train = StandardScaler().fit_transform(X_train) X_test = StandardScaler().fit_transform(X_test) # X_train と x_test のシェイプ print('X_train.shape = ', X_train.shape) print('X_test.shape = ', X_test.shape) # test データの正常(0)と異常(1)の比率 uniq_test, counts_test = np.unique(y_test, return_counts=True) print("y_test count each labels: ", dict(zip(uniq_test, counts_test))) # Building the model input_dim = X_train.shape[1] encoding_dim = 14 input_layer = Input(shape=(input_dim, )) encoder = Dense(encoding_dim, activation="tanh", activity_regularizer=regularizers.l1(10e-5))(input_layer) encoder = Dense(int(encoding_dim / 2), activation="relu")(encoder) decoder = Dense(encoding_dim, activation='tanh')(encoder) decoder = Dense(input_dim, activation='relu')(decoder) autoencoder = Model(inputs=input_layer, outputs=decoder) autoencoder.summary() nb_epoch = 100 batch_size = 32 autoencoder.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath="model.h5", verbose=0, save_best_only=True) if DO_TRANING: history = autoencoder.fit(X_train, X_train, epochs=nb_epoch, batch_size=batch_size, shuffle=True, validation_data=(X_test, X_test), verbose=1, callbacks=[checkpointer]).history # Model loss plt.plot(history['loss']) plt.plot(history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper right'); plt.show() |
21−41行目で、学習データを作成します。細かな手順はコードのコメントを見て頂ければ分かると思います。最終的に、X_trainは以下の様なデータの集まりになります。

簡単に言うと、29列(31列からTimeとClassを除いた)のデータを1行づつ読み取り、29個の数字を学習データとして AutoEncoderの入力にします。そして、AutoEncoderはこれとできる限り同じ出力をだすことを学習します。
44−54行目はネットワークを構築部分。60−62行目はネットワークの最適化の部分で Optimiser = ‘adam’ , loss = ‘ mean_squared_error’ で行なっています。
64−66行目は学習した重みファイルを保存する部分、68−75行目は学習を実行する部分、78−84行目はロスの推移グラフを描く部分です。
では、早速実行してみましょう。mlpなのでノートパソコンで軽快に動きます。私のMacbookAir で20sec /epoch、100epochが約33分で完了します。
学習データは29個のデータの塊が227451 個あり、テストデータは29個のデータの塊が56962個あります。テストデータの中にある正常(0)の数は56864個、異常(1)の数は98個です。
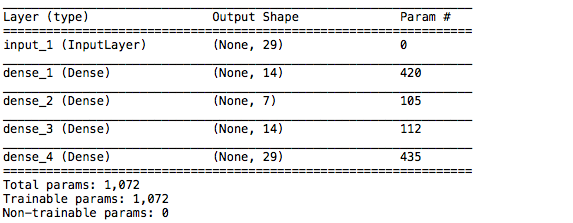
ネットワークSummaryです。先程の29個のデータが Input_1に入力され、AutoEncoder はdense_4に出来るだけそれと同じ29個のデータを出力することを学習します。
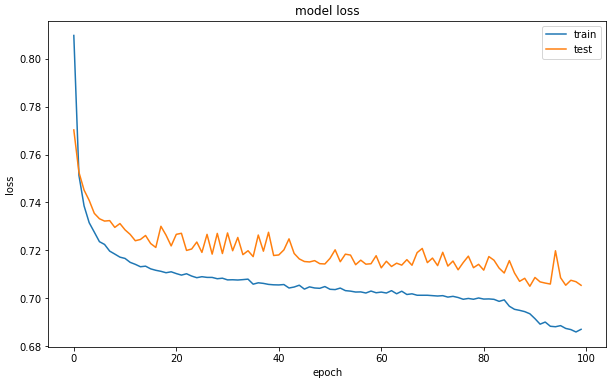
ロス推移グラフです。train_lossも test_lossも順調に下がった様です。
異常検知をする
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
# 学習した重みファイルをロードする autoencoder = load_model('model.h5') # X_test データを入力として AutoEncoderで再現データを作成する predictions = autoencoder.predict(X_test) # X_test データと再現データの mse(平均2乗誤差)を計算する mse = np.mean(np.power(X_test - predictions, 2), axis=1) # mseとy_test のデータフレーム error_dfを作成する error_df = pd.DataFrame({'reconstruction_error': mse, 'true_class': y_test}) # ROC curve from sklearn.metrics import (confusion_matrix, precision_recall_curve, auc, roc_curve, recall_score, classification_report, f1_score, precision_recall_fscore_support) fpr, tpr, thresholds = roc_curve(error_df.true_class, error_df.reconstruction_error) roc_auc = auc(fpr, tpr) plt.title('ROC curve') plt.plot(fpr, tpr, label='AUC = %0.4f'% roc_auc) plt.legend(loc='lower right') plt.plot([0,1],[0,1],'r--') plt.xlim([-0.001, 1]) plt.ylim([0, 1.001]) plt.ylabel('True Positive Rate') plt.xlabel('False Positive Rate') plt.show(); # get data(precision, recall, th) precision, recall, th = precision_recall_curve(error_df.true_class, error_df.reconstruction_error) # Precision & Recall vs Reconstruction error plt.plot(th, precision[1:], 'b', label='Precision curve', color='r') plt.plot(th, recall[1:], 'b', label='Recall curve', color='b') plt.title('Precision and Recall vs mse') plt.xlabel('mse') plt.ylabel('Precision and Recall') #plt.xlim(0, 250) plt.legend(loc=1) plt.show() # Reconstruction error for different classes threshold = 3 groups = error_df.groupby('true_class') fig, ax = plt.subplots() for name, group in groups: ax.plot(group.index, group.reconstruction_error, marker='o', ms=3.5, linestyle='', label= "Fraud" if name == 1 else "Normal") ax.hlines(threshold, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold') ax.legend() plt.title("mse for different classes") plt.ylabel("mse") plt.xlabel("Data point index") plt.show(); # Confusion matrix y_pred = [1 if e > threshold else 0 for e in error_df.reconstruction_error.values] conf_matrix = confusion_matrix(error_df.true_class, y_pred) plt.figure(figsize=(5, 5)) LABELS = ["Normal", "Fraud"] sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d", square = True); plt.title("Confusion matrix") plt.ylabel('True class') plt.xlabel('Predicted class') plt.show() |
ポイントは、3−7行目の部分です。3行目はAutoEncoderが学習した重みファイルを読み込む部分、5行目はテストデータX_testをAutoEncoderに入力し、その出力をpredictions に入れる部分。
7行目はテストデータX_testと出力の平均2乗誤差(mse = mean squared error)を計算する部分です。入力するテストデータが学習した正常データの場合 mse は小さいですが、学習したことのない異常データの場合 mse は大きくなり、異常検知出来ることが期待できます。
13−28行目はROC曲線を描かせる部分、32−42行目はprecision曲線 とRecal曲線を描かせる部分、45−58は何処に閾値を設けるのかのイメージを描かせる部分、61−69行目はConfusion matrix を描かせる部分です。
まずは動かしてみましょう。学習はしませんので、あっと言うまに完了します。
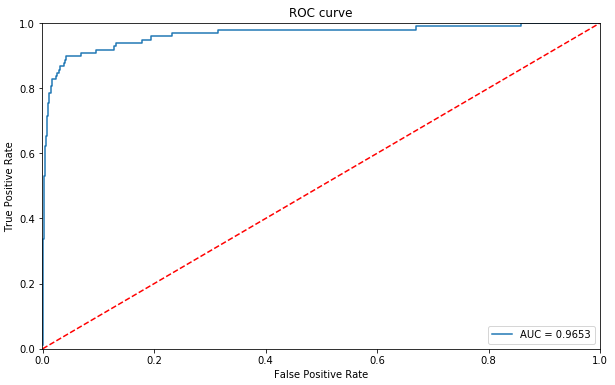
分類性能を表すROC曲線です。左角に寄っている程性能が良い訳ですが、今回の様に異常データが極めて少ない場合は、これだけでは良く分かりません。
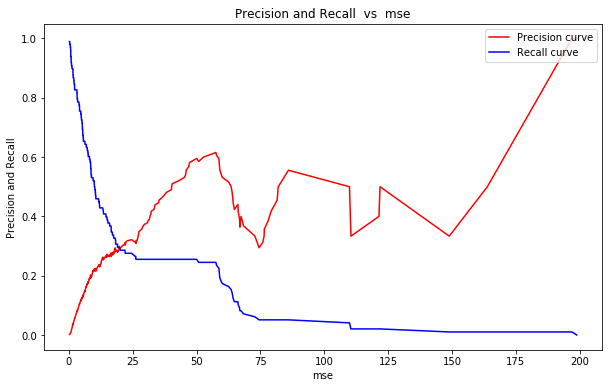
mse(テスト画像と再現画像の平均2乗誤差)とPrecision(適合率) とRecall (再現率)の関係です。Precision は異常と予測した中に実際の異常が含まれる確率、Recallは異常と予測した中に実際の異常の何%が含まれるかを表します。
Precision を上げたいなら mse を上げ、明らかな異常だけ摑まえる様にすれば良い訳ですが、そうするとReacll は下がってしまいます。Recall を上げたいならmse を下げ、少しでも怪しいものは異常として捕まえれば良い訳ですが、そうするとPrecisionは下がってしまいます。つまり、Precision とRecall は相反する関係になります。
mse のどのあたりで Threshold(閾値)を設けるのかは、Precision とReacll をどうバランスさせたいかで決まります。今回は、非常に発生頻度の少ない異常を見付けたいので、Precisionの悪化には目をつぶりReacllを優先させる方針を取るべきでしょう。
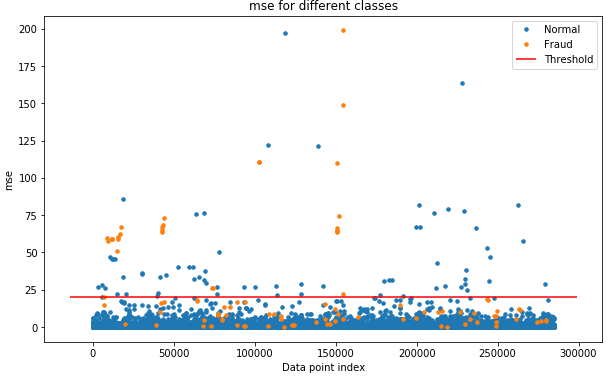
これは、mse のどの値でTreshold(閾値)を引くと、異常がどれだけ捕まりそうかを可視化したグラフです。青色が正常取引、オレンジ色が異常取引を表しています。現在、mse =20 でTresholdを引いていますが、もう少しTreshold を下げないと異常の捕まりが少ない様です。
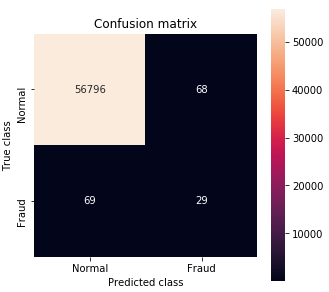
Confusion matrix です。正常データに比べて異常データがとても少ないので、かなりイビツな形になっています。いわゆる精度は Accuracy =(56796+29) / (56796+68+69+29) = 99.8%ですが、こういう場合はあまり意味がないですね。
現時点は、mse = 20で、Precision = 29 / (68+29) = 29.9% 、Recall = 29 / (69+29) =29.6% と丁度2つの指標が同じくらいですが、先程の方針通り、Precisionの悪化が容認出来る限りRacallを改善した方が良さそうです。
Treshold を調整してみます
先程のコードの45行目のTresholdの値を変更して実行すれば、色々な場合のConfusion Matrixが得られます。最終的に私が選んだのは、こんな設定です。
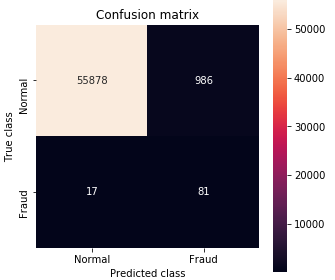
Treshold = 3で、Precision = 81 / (986+81) = 7.6% 、Recall = 81 / (81+17) =82.7% です。98件の異常取引のうち81件はその後の不正の未然防止が図れます。一方で、間違って取引停止にした 986人には「なぜ、使用停止になったかの説明とフォロー」をする必要がありますが、1000人未満なら何とか対応は出来るかと判断しました。
厳密に言えば、17人の不正の再発コストと986人への「なぜ使用停止になったかの説明とフォロー」のコストを比較して調整すべきですね。
最後に、学習+異常検知のコード全体を載せておきます。
では、また。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns from pylab import rcParams from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, MinMaxScaler from keras.models import Model, load_model from keras.layers import Input, Dense from keras.callbacks import ModelCheckpoint from keras import regularizers rcParams['figure.figsize'] = 10, 6 # True で学習する、 False で学習しない DO_TRANING = False ### データセットの前準備 # pandasで csv_dataを読み込む df = pd.read_csv("data/creditcard.csv") # Time列は影響なしとみてデータから外す data = df.drop(['Time'], axis=1) # dataをX_train と X_testに 8:2 で分割する X_train, X_test = train_test_split(data, test_size=0.2, random_state=42) # X_trainのデータは正常(Classが0)だけにする X_train = X_train[X_train.Class == 0] # y_testは X_testの Class列を使う y_test = X_test['Class'] # X_train, X_test のデータから Class列を外す X_train = X_train.drop(['Class'], axis=1) X_test = X_test.drop(['Class'], axis=1) # 標準化して numpy.ndarry 配列にする X_train = StandardScaler().fit_transform(X_train) X_test = StandardScaler().fit_transform(X_test) # X_train と x_test のシェイプ print('X_train.shape = ', X_train.shape) print('X_test.shape = ', X_test.shape) # test データの正常(0)と異常(1)の比率 uniq_test, counts_test = np.unique(y_test, return_counts=True) print("y_test count each labels: ", dict(zip(uniq_test, counts_test))) # Building the model input_dim = X_train.shape[1] encoding_dim = 14 input_layer = Input(shape=(input_dim, )) encoder = Dense(encoding_dim, activation="tanh", activity_regularizer=regularizers.l1(10e-5))(input_layer) encoder = Dense(int(encoding_dim / 2), activation="relu")(encoder) decoder = Dense(encoding_dim, activation='tanh')(encoder) decoder = Dense(input_dim, activation='relu')(decoder) autoencoder = Model(inputs=input_layer, outputs=decoder) autoencoder.summary() nb_epoch = 100 batch_size = 32 autoencoder.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath="model.h5", verbose=0, save_best_only=True) if DO_TRANING: history = autoencoder.fit(X_train, X_train, epochs=nb_epoch, batch_size=batch_size, shuffle=True, validation_data=(X_test, X_test), verbose=1, callbacks=[checkpointer]).history # Model loss plt.plot(history['loss']) plt.plot(history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper right'); plt.show() # 学習した重みファイルをロードする autoencoder = load_model('model.h5') # X_test データを入力として AutoEncoderで再現データを作成する predictions = autoencoder.predict(X_test) # X_test データと再現データの mse(平均2乗誤差)を計算する mse = np.mean(np.power(X_test - predictions, 2), axis=1) # mseとy_test のデータフレーム error_dfを作成する error_df = pd.DataFrame({'reconstruction_error': mse, 'true_class': y_test}) # ROC curve from sklearn.metrics import (confusion_matrix, precision_recall_curve, auc, roc_curve, recall_score, classification_report, f1_score, precision_recall_fscore_support) fpr, tpr, thresholds = roc_curve(error_df.true_class, error_df.reconstruction_error) roc_auc = auc(fpr, tpr) plt.title('ROC curve') plt.plot(fpr, tpr, label='AUC = %0.4f'% roc_auc) plt.legend(loc='lower right') plt.plot([0,1],[0,1],'r--') plt.xlim([-0.001, 1]) plt.ylim([0, 1.001]) plt.ylabel('True Positive Rate') plt.xlabel('False Positive Rate') plt.show(); # get data(precision, recall, th) precision, recall, th = precision_recall_curve(error_df.true_class, error_df.reconstruction_error) # Precision & Recall vs Reconstruction error plt.plot(th, precision[1:], 'b', label='Precision curve', color='r') plt.plot(th, recall[1:], 'b', label='Recall curve', color='b') plt.title('Precision and Recall vs mse') plt.xlabel('mse') plt.ylabel('Precision and Recall') #plt.xlim(0, 250) plt.legend(loc=1) plt.show() # Reconstruction error for different classes threshold = 3 groups = error_df.groupby('true_class') fig, ax = plt.subplots() for name, group in groups: ax.plot(group.index, group.reconstruction_error, marker='o', ms=3.5, linestyle='', label= "Fraud" if name == 1 else "Normal") ax.hlines(threshold, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold') ax.legend() plt.title("mse for different classes") plt.ylabel("mse") plt.xlabel("Data point index") plt.show(); # Confusion matrix y_pred = [1 if e > threshold else 0 for e in error_df.reconstruction_error.values] conf_matrix = confusion_matrix(error_df.true_class, y_pred) plt.figure(figsize=(5, 5)) LABELS = ["Normal", "Fraud"] sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d", square = True); plt.title("Confusion matrix") plt.ylabel('True class') plt.xlabel('Predicted class') plt.show() |














コメントを残す