
1.はじめに
以前、「画像から物体を検知し、形を推定するタスク」を行うMask R-CNNをご紹介しました。今回は、エッジでのリアルタイム処理向けの、処理が高速なYolactEdge をご紹介します。
*この論文は、2020年12月に提出されました。
2.YolactEdgeとは?
まず、YolactEdgeのベースであるYolactのフロー図を示します。
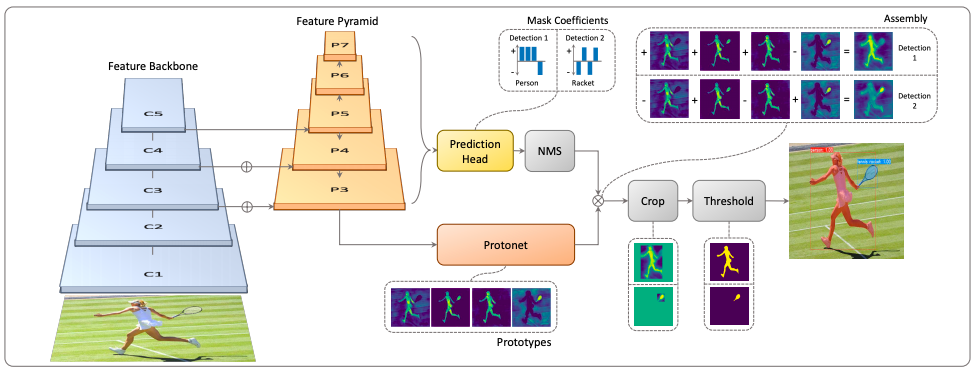
まず、Feature Backbone(CNNネットワーク)で画像から Feature Pyramid(特徴量をまとめたピラミッド)を抽出します。そして、Protonet で画像全体の全てのマスクを生成し、Prediction Head+NMSで各マスクの信頼度を求め、この2つを結合します。その後、Crop+Threshholdを行い出力を得ます。マスク生成と信頼度計算を並行して動かすのが高速化の秘密です。
このプロセスを改良し、さらなる高速化を実現したのが YolactEdge で、下記にそのフォローを示します。
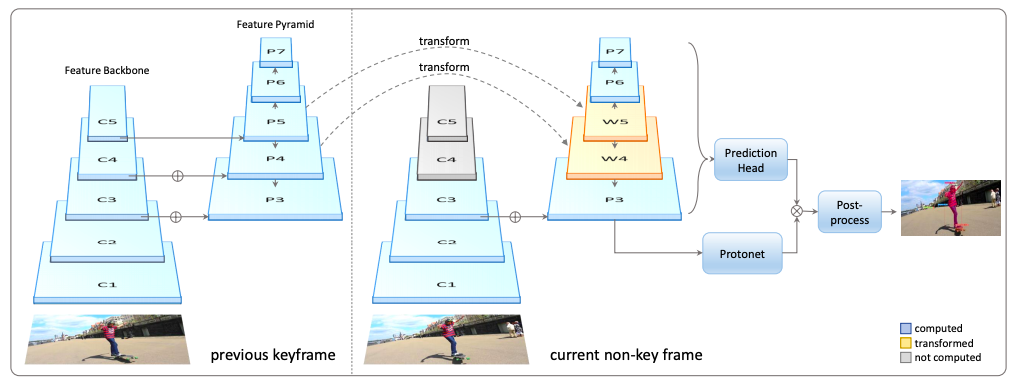
処理する画像がキーフレーム(場面が変わるフレーム)でなければ、画像は1つ前のフレームとほとんど変わらないはずです。そのため、画像から特徴量を抽出するところで、一部を前の画像の特徴量を使うことで計算量を削減しています。
また、YolactEdgeでは、TensorRTという推論最適化・実行ライブラリを採用することで、ネットワークを最適化し、低レイテンシ・高スループットの推論を実現しています。
これによって、550×550の画像に対して、Jetson AGXXavier(Nvidiaが開発したエッジ処理用デバイス)で最大30FPS、RTX 2080Tiであればなんと172FPSを実現すると報告されています。
それでは、実際にコードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。なお、今回はTensorRTはインストールしていません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# GPUの仕様チェック !nvidia-smi -L # Githubからコードをコピー !git clone https://github.com/cedro3/yolact_edge.git !git clone https://github.com/chentinghao/download_google_drive.git %cd yolact_edge !mkdir -p weights # 重みとCOCOデータのダウンロード !python ../download_google_drive/download_gdrive.py 1EAzO-vRDZ2hupUJ4JFSUi40lAZ5Jo-Bp ./weights/yolact_edge_54_800000.pth !python ../download_google_drive/download_gdrive.py 15jyd5CRJxNiA41UMjGbaSnmaytfeILfI ./calib_images_coco.zip !unzip -q calib_images_coco.zip # ライブラリーのインポート import cv2 from google.colab.patches import cv2_imshow from IPython.display import HTML from base64 import b64encode |
静止画を物体検知
下記のコードを実行し、物体検出するサンプル画像 (./pic/sample.jpg) を確認します。自分の画像でやってみたい場合は、ここに画像をアップロードして下さい。
|
1 2 3 |
# サンプル画像を表示 im = cv2.imread("./pic/sample.jpg") cv2_imshow(im) |

eval.pyを実行し、静止画から物体を検出します。引数は、1行目が学習済みの重みの指定、2行目は物体を検出する閾値(score_threshold)と検出数(top_k)、3行目は入力画像指定(image)と出力画像指定(output_img)、4行目はTensorRTを使わない指定です。。
自分の画像でやってみたい方は、入力画像指定(image)のところを修正して下さい。
|
1 2 3 4 5 |
# 静止画から物体検出 !python eval.py --trained_model=weights/yolact_edge_54_800000.pth\ --score_threshold=0.15 --top_k=100\ --image=pic/sample.jpg:output_img.jpg\ --disable_tensorrt |
|
1 2 3 |
# 検出画像を表示 im = cv2.imread("./output_img.jpg") cv2_imshow(im) |

人、馬、自転車、傘などを物体検知し、その形を推定しています。
ビデオから物体検知
下記のコードを実行し、物体検出するサンプルビデオ (./video/sample.mp4) を確認します。自分の動画でやってみたい方は、ここに動画をアップロードして下さい。
|
1 2 3 4 5 6 7 |
# サンプルビデオの確認 mp4 = open('./video/sample.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="80%" height="80%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
eval.py を実行し、ビデオから物体を検出します。引数は、1行目が学習済みの重みの指定、2行目は物体を検出する閾値(score_threshold)と検出数(top_k)、3行目は入力ビデオ指定(video)と出力ビデオ指定(output_video)、4行目はTensorRTを使わない指定です。
自分のビデオでやってみたい方は、入力ビデオ指定(video)のところを修正して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# ビデオから物体検出し、mp4動画を作成する !python eval.py --trained_model=weights/yolact_edge_54_800000.pth\ --score_threshold=0.15 --top_k=100\ --video=video/sample.mp4:output_video.mp4\ --disable_tensorrt # コーデック変換 import os import shutil if os.path.exists('./output.mp4'): os.remove('./output.mp4') ! ffmpeg -i output_video.mp4 -vcodec h264 -pix_fmt yuv420p output.mp4 |
|
1 2 3 4 5 6 7 |
# mp4動画の再生 mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="80%" height="80%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
人、車、バス、自転車などを物体検出し、形を推定しています。
では、また。
(オリジナルGithub)https://github.com/haotian-liu/yolact_edge
(Twitterへの投稿)














初心者です。
Yolact Edgeで自前でデータを用意してグー、チョキ、パーを認識させるシステムを作るにはどうすれば良いでしょうか。アノテーションツールは都合上使えません。
田中さん
コメントありがとうございます。
グー、チョキー、パーの認識については、オリジナルGithub(https://github.com/haotian-liu/yolact_edge)を見てカスタムデータセットで学習する方法もありますが、面倒なのでおすすめしません。
それよりも、学習不要な mediapipe をおすすめします。この Axross の記事(https://axross-recipe.com/recipes/136)を参考にされるのが良いと思います。
ご紹介ありがとうございます。
ご紹介のcolabでyolact_edgeを試みておりますが、unpickling errorが起きてしまいます。
colab内のpackageが変わったためでしょうか?
お教えいただけると助かります。
下記エラーです。
Traceback (most recent call last):
File “eval.py”, line 1237, in
net.load_weights(args.trained_model, args=args)
File “/content/yolact_edge/yolact.py”, line 1185, in load_weights
state_dict = torch.load(path, map_location=’cpu’)
File “/usr/local/lib/python3.7/dist-packages/torch/serialization.py”, line 608, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File “/usr/local/lib/python3.7/dist-packages/torch/serialization.py”, line 777, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: invalid load key, ‘<'.
やまさん
ご連絡ありがとうございます。
先月ありました Google drive のダウンロード仕様変更によって、学習済みパラメータのダウンロードが出来ていませんでした。その部分のコードは見直し済みですので、再度お試しください。
モデルファイルのアドレス変更がエラーの原因だということ理解しました。
更新先のcolabにてdetectron2のmaskrcnnよりも早そうな解析結果を確認しました。
感動です。
当初、https://github.com/haotian-liu/yolact_edge で進めておりましたが、うまくいかないのは同じ問題と確認しました。
断念するところでした。ありがとうございました。