
今回は、LSTMを使って、航空会社の乗客数を予測してみます。
こんにちは cedro です。
過去から現在までが一定のトレンドで推移していて、未来もそのトレンドが続くと仮定するならば、未来予測ができるはずです。
ニューラルネットワークの中には、過去の時系列データの流れからその後のデータを予測する、リカレントネットワークというのがあり、主に文章・対話の生成、音素・音声認識、 映像認識等に使われています。
今回は、LSTMを使って、航空会社の乗客数を予測してみます。
データセットの準備
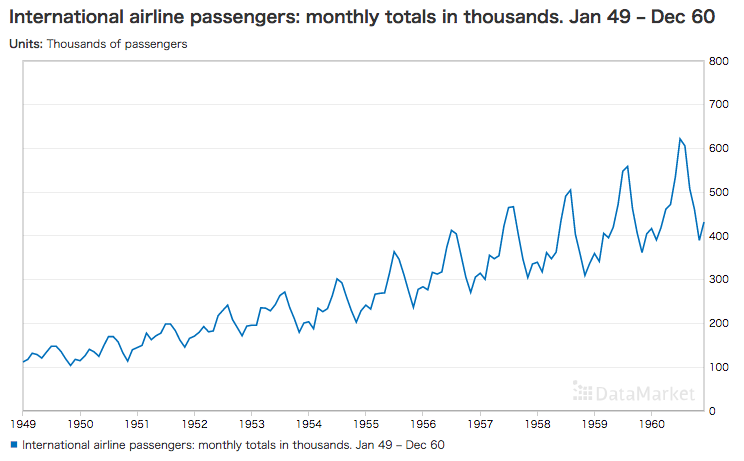
今回使うデータセットは、以前にもご紹介したことのある、1949年から1960年(12年間)のインターナショナル・エアラインズの乗客数の月別推移です。
毎年、ピークがあるのはバカンスで乗客数が急増するためでしょうか。明らかな季節変動要素を持ち、かつ長期的には綺麗な右肩上がりのトレンドで、サンプルデータとしてはもってこいです。
今回は、1949年から1958年の10年間を学習させ、1959年~1960年のその後の2年間を予測させてみたいと思います。
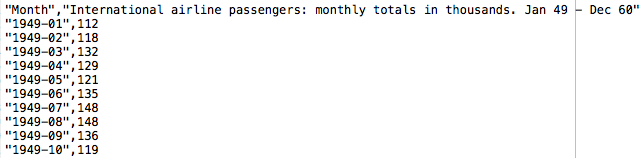
DataMarket でExpot タブを選択し、CSVファイルをダウンロードするとこんな内容になっています。1行目にタイトル、2行目以降、年月と乗客数が並んでいます。このファイルをプログラムと同じフォルダーに格納します。
プログラムを作成します
手順に沿って、プログラムを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from keras.models import Sequential from keras.layers.core import Dense, Activation from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import matplotlib.pyplot as plt import pandas as pd # read data passenger = pd.read_csv("./international-airline-passengers.csv", skipfooter=3) raw_data = np.array(passenger.iloc[:, 1].astype('float32')) raw_data = raw_data/600 |
必要なライブラリーをインポートしたら、pandas を使って CSVファイルを読み込みます。引数 skipfooter =3 は、最後3行分にメモが書いてあるので読み飛ばす指定です。
そして、np.array で乗客数データを配列の形で、raw_data に格納します。引数 iloc [ : , 1 ] は乗客数が書いてある列の指定です。
最後に raw_data を600で割っているのは正規化するためです。ニューラルネットワークに入力するデータは、概ね−1〜+1の範囲である必要があります。今回の乗客数のMAXは606だったので、ざっくり600で割ったというわけです。少し手抜きですね(笑)。
さあ、これでraw_data の中に12ヶ月×12年間=144個の乗客数データが格納されました。
|
1 2 3 4 5 6 7 8 9 10 |
# Make input data x, y = [], [] length = 12 for i in range(len(raw_data)-length-24): x.append(raw_data[i:i + length]) y.append(raw_data[i + length]) data = np.array(x).reshape(len(x), length, 1) target = np.array(y).reshape(len(y), 1) |
LSTMに入力する形式にデータを加工します。今回のデータは明確な季節変動のあるデータなので、12個の連続したデータを元に、13個目のデータを予測することにします。まず、配列 x, y を作ります。
for i in range ループの初回は、x にraw_data の0番目〜11番目のデータが追加され、y にraw_data の12番目のデータが追加されます。2回目はx にraw_data の1番目〜12番目のデータが追加され、y にraw_data の13番目のデータが追加されます。これを順次繰り返します。
繰り返し回数は、len(raw_data) – length -24 = 144 – 12 -24 = 108 回なので、これで108組のデータが作成できます。最後にシェイプを整えます。12個の連続データ data のシェイプは(108, 12, 1)。13番目のデータ target のシェイプは(108, 1)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Model building length_of_sequence = 12 in_out_neurons = 1 n_hidden = 300 model = Sequential() model.add(LSTM(n_hidden, batch_input_shape=(None, length_of_sequence, in_out_neurons), return_sequences=False)) model.add(Dense(in_out_neurons)) model.add(Activation("linear")) optimizer = Adam(lr=0.001) model.compile(loss="mean_squared_error", optimizer=optimizer) # Learning history = model.fit(data, target, batch_size=1, epochs=100, validation_split=0.1) predicted = model.predict(data) |
モデル構築をします。12個の連続データで次のデータを1つ予測するので、length_of_sequence = 12 、in_out_neurons = 1 です。隠れ層(n_hidden)の数は300個とします。
学習は、batch_size = 1 、epoch = 100 で行い、データの10%を評価に(validation_split = 0.1)使います。つまり、108個のデータの内、97個を学習に使い、11個を評価に使います。学習を完了すると、model.predict()でデータ予測を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Future prediction future_test = data[len(data)-1] future_result = [] time_length = 12 for i in range(24): test_data = np.reshape(future_test, (1, time_length, 1)) batch_predict = model.predict(test_data) future_test = np.delete(future_test, 0) future_test = np.append(future_test, batch_predict) future_result = np.append(future_result, batch_predict) |
学習結果を元に、1959年〜1960年を予測する部分です。future_test = data [ len(data) – 1] はdataの最後のデータ(1958年1月〜1958年12月)を意味します。future_result は予測した結果を保存する配列です。
for i in range ループでは、初回 future_test のシェイプを(1, 12, 1)に変換し、model.predict で翌月の乗客数 batch_predict を予測します。
そして、np.delete で future_test の0番目を消し、予測した翌月の乗客数 batch_predict を加えます。この結果、future_test は1958年2月〜1959年1月のデータに置き換わります。
最後に、future_result に予測した翌月の乗客数 batch_predict を追加します。これを24ヶ月繰り返します。完了すると、future_result に1959年1月〜1961年1月までの24ヶ月分の予測データが保存されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Plot Wave plt.figure() plt.plot(range(0, len(raw_data)), raw_data, color="b", label="raw") plt.plot(range(12,len(predicted)+12),predicted, color="r", label="predict") plt.plot(range(0+len(raw_data)-24, len(future_result)+len(raw_data)-24), future_result, color="g", label="future") plt.legend() plt.savefig("predict.png") plt.show() plt.close() # Plot Training loss & Validation Loss loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.plot(epochs, val_loss, "b", label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.savefig("loss.png") plt.close() |
波形表示の部分です。raw_data = 生データ(1949年〜1960年)は青色、predicted=学習時の予測データ(1950年〜1958年)は赤色、future_result = 学習後の予測データ(1959年〜1960年)は緑色で表示します。
最後に、ロス推移グラフ表示部分です。ここは、何回も出て来ているので、説明は不要でしょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
from keras.models import Sequential from keras.layers.core import Dense, Activation from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import matplotlib.pyplot as plt import pandas as pd # read data passenger = pd.read_csv("./international-airline-passengers.csv", skipfooter=3) raw_data = np.array(passenger.iloc[:, 1].astype('float32')) raw_data = raw_data/600 # Make input data x, y = [], [] length = 12 for i in range(len(raw_data)-length-24): x.append(raw_data[i:i + length]) y.append(raw_data[i + length]) data = np.array(x).reshape(len(x), length, 1) target = np.array(y).reshape(len(y), 1) # Model building length_of_sequence = 12 in_out_neurons = 1 n_hidden = 300 model = Sequential() model.add(LSTM(n_hidden, batch_input_shape=(None, length_of_sequence, in_out_neurons), return_sequences=False)) model.add(Dense(in_out_neurons)) model.add(Activation("linear")) optimizer = Adam(lr=0.001) model.compile(loss="mean_squared_error", optimizer=optimizer) # Learning history = model.fit(data, target, batch_size=1, epochs=100, validation_split=0.1) predicted = model.predict(data) # Future prediction future_test = data[len(data)-1] future_result = [] time_length = 12 for i in range(24): test_data = np.reshape(future_test, (1, time_length, 1)) batch_predict = model.predict(test_data) future_test = np.delete(future_test, 0) future_test = np.append(future_test, batch_predict) future_result = np.append(future_result, batch_predict) # Plot Wave plt.figure() plt.plot(range(0, len(raw_data)), raw_data, color="b", label="raw") plt.plot(range(12,len(predicted)+12),predicted, color="r", label="predict") plt.plot(range(0+len(raw_data)-24, len(future_result)+len(raw_data)-24), future_result, color="g", label="future") plt.legend() plt.savefig("predict.png") plt.show() plt.close() # Plot Training loss & Validation Loss loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.plot(epochs, val_loss, "b", label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.savefig("loss.png") plt.close() |
最後にプログラム全体を載せておきます。
プログラムを動かします
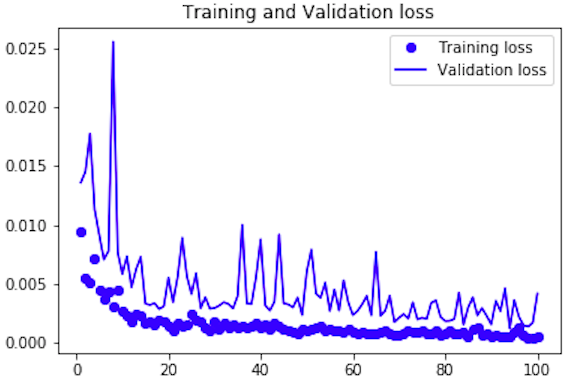
シンプルなプログラムですので、普通のPCで軽快に動きます。私のMacbook Air で約4分で完了しました。ロス推移グラフを見ると、順調にロスは下がっているようです。
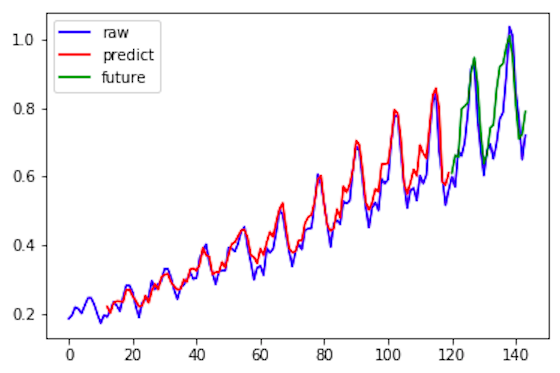
予測グラフです。青色が生データで、赤色が学習時の予測データ、緑色が予測データです。赤色を見るとまずまず上手く学習できている状況が読み取れます。また緑色の予測の部分も、結構いい感じではないでしょうか。
実は、1年前の10/21 のブログで、今回と同じネタを SONY Neural Network Console でやったことがあるのですが、あの時と比べると、データセットの作成やグラフ表示は効率的にやれるようになったし、python も多少分かって来ました。少し進歩したかな(笑)。
では、また。













コメントを残す