
今回は、VGG16の学習済みモデルをファインチューニングし、少ない学習データで高い認識精度を持つモデルを作ってみます。
こんにちは cedro です。
前回、VGG16の学習済みモデルを使って、1000カテゴリーの一般物体認識をやってみました。では、その1000カテゴリー以外の物体を認識させたい時どうするのか、さらに大量の画像データを集めて、また長時間かけて学習する以外方法はないのでしょうか。
そこで登場するのが、ファインチューニングです。これは、ニューラルネットワークが学習する時に、入力に近い層では点や線のような単純な模様を学習し、出力に近い層で複雑な模様を学習する性質を利用します。
つまり、入力に近い層はベーシックな内容を学習しているのでここは新たに学習させず、出力に近い層のみ学習させるわけです。こうすることで、少ない学習データでしかも早く学習が完了し、結構精度が出ます。
ということで、今回は、VGG16の学習済みモデルをファインチューニングし、少ない学習データで高い認識精度を持つモデルを作ってみます。
データセットを準備します

9/13のブログで使ったオリジナルデータセットを流用します。これは、CelebAデータセットから、属性ファイルを使って、4種類の画像を500枚づつピックアップしたもので、合計 500枚×4種類=2,000枚 です。
9/13のブログでは、Keras のサンプルプログラム CNNを使って、画像を900枚(各225枚×4=900枚)学習させました。その認識精度の結果は、ImageDataGenerator を使わない場合 77.44%、使う場合79.41% でした。
今回は、これと同じ条件で、VGG16の学習に画像を900枚だけ使ってファインチューニングし、認識精度がどうなるか試してみます。
プログラムを作成します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 |
from __future__ import print_function import keras from keras.applications import VGG16 from keras.models import Sequential, load_model from keras import models, optimizers from keras.optimizers import SGD from keras.layers import Dense, Dropout, Activation, Flatten from sklearn.model_selection import train_test_split from PIL import Image import os import numpy as np import glob batch_size = 32 num_classes = 4 epochs = 100 save_dir = os.path.join(os.getcwd(), 'saved_models') model_name = 'keras_vgg16_trained_model.h5' ### データセットの準備 folder = ["0","1","2","3"] image_size = 224 x = [] y = [] for index, name in enumerate(folder): dir = "./data/" + name files = glob.glob(dir + "/*.png") for i, file in enumerate(files): image = Image.open(file) image = image.convert("RGB") image = image.crop((25,45,153,173)) ### 128×128でセンタークロップ image = image.resize((image_size, image_size)) ### 224×224にリサイズ data = np.asarray(image) x.append(data) y.append(index) x = np.array(x) y = np.array(y) ### データを学習:評価=45%:55%でランダムに分割 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.55, random_state=111) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # y ラベルをワンホット表現に y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) ### モデル構築 vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3)) for layer in vgg_conv.layers[:-4]: layer.trainable = False model = models.Sequential() model.add(vgg_conv) model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(4, activation='softmax')) ### データは4種類 model.summary() model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) ### 学習 history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), shuffle=True) # Save model and weights if not os.path.isdir(save_dir): os.makedirs(save_dir) model_path = os.path.join(save_dir, model_name) model.save(model_path) print('Saved trained model at %s ' % model_path) # Score trained model. scores = model.evaluate(x_test, y_test, verbose=1) print('Test loss:', scores[0]) print('Test accuracy:', scores[1]) ### Plot accuracy & loss import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) #plot accuracy plt.plot(epochs, acc, "bo", label = "Training acc" ) plt.plot(epochs, val_acc, "b", label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("acc.png") plt.close() #plot loss plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.plot(epochs, val_loss, "b", label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.savefig("loss.png") plt.close() |
47行目で2000個の画像データを、学習:評価=45%:55%でランダムに分割しています。これによって、学習データは900枚になります。
59行目からが、モデルを構築する部分です。畳み込み13層は imagenet で学習した重みをそのまま使って学習させず、全結合3層のみ学習させます。オプチマイザーはSGDを使っています。
98行目からが、ロス・精度の時系列グラフを作成する部分です。
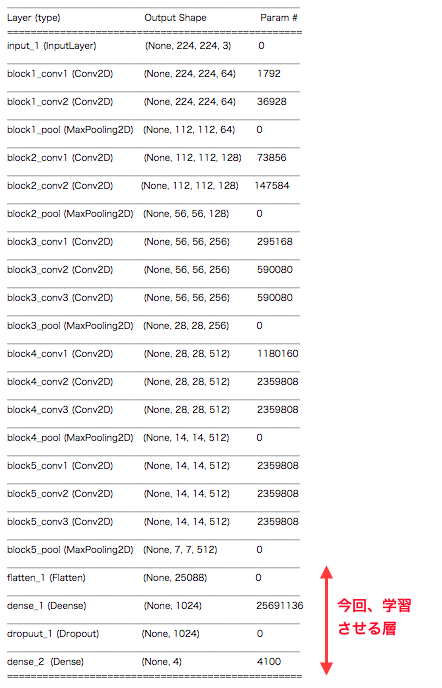
今回、学習させるのは、赤矢印の全結合3層(+Dropout)のみです。入力側の畳み込み13層は学習させません。
学習結果はどうなったか
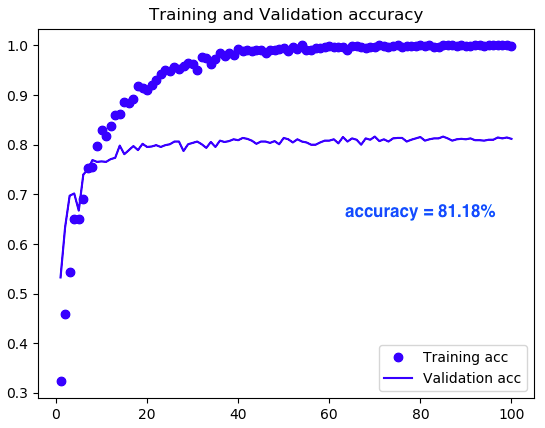
ImageDataGenerator を使わずに学習した場合です(先ほどのプログラムのまま)。Validation accuracy が30epoch で既に80%を超えていますので立ち上がりが早いです。9/13のCNNの場合と比べると、2〜3倍程度立ち上がりが早いです。もちろん、最終的な Validation accuracyは81.18% でCNNの場合より、+3.74 ポイント向上しています。
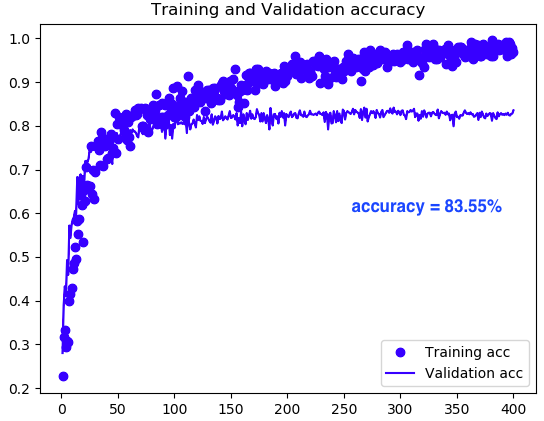
ImageDataGenerator を使って学習した場合です(プログラムにImageDataGeneratorを追加)。使わない場合と比べると立ち上がりはゆっくり目です。最終的な Validation accuracyは83.55% でCNNの場合より、+4.14 ポイント向上しています。
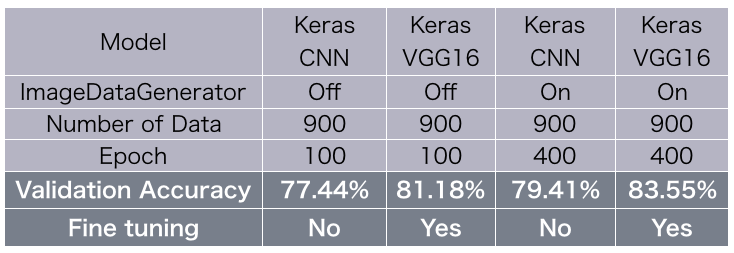
まとめるとこんな形になります。ファインチューング、結構効果的な手法のようです。
では、また。














コメントを残す