
今回は、Keras のLSTMのサンプルプログラムを使って、日本語の文章生成をしてみます。
こんにちは cedro です。
先回、LSTMで航空会社の乗客数の予測をしてみました。具体的には、過去12ヶ月の乗客数のデータから翌月の乗客数を予測をし、これを繰り返すことで、将来のトレンド予測をしたわけです。
これを文章に置き換えるとどうなるのでしょうか。連続した文字列からその後の1文字を予測する。これを繰り返すと、文章生成ができるはずです。
今回は、Keras のLSTMのサンプルプログラムを使って、日本語の文章生成をしてみます。
データセットを準備します。
今回、使うサンプルプログラムは、lstm_text_generation.py で、データセットはニーチェの英文が使われているのですが、英語がほとんど出来ない私にとっては、英文の文章が生成されても、あまり意味がありません。
ということで、今回はアーネスト・ヘミングウェイの「老人と海」の日本語訳版を使うことにします。青空文庫で、「老人と海」のテキストファイル(ルビあり)をダウンロードし、サンプルプログラムと同じフォルダーに保管します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import sys import re path = './rojinto_umi.txt' bindata = open(path, "rb") lines = bindata.readlines() for line in lines: text = line.decode('Shift_JIS') # Shift_JISで読み込み text = re.split(r'\r',text)[0] # 改行削除 text = text.replace('|','') # ルビ前記号削除 text = re.sub(r'《.+?》','',text) # ルビ削除 text = re.sub(r'[#.+?]','',text) # 入力者注削除 print(text) file = open('data_rojinto_umi.txt','a',encoding='utf-8').write(text) # UTF-8に変換 |
ダウンロードしたテキストファイルをサンプルプログラムに適切に読ませるために、前処理を行います。このプログラムをサンプルプログラムと同じフォルダーに保存し、実行します。
実行すると、テキストファイルの形式(Shift-JIS)で読み込み、改行、ルビ、入力者注などを削除してから、サンプルプログラムが読めるように UTF-8に変換して、data_rojinto_umi.txt という名前で保存します。
あとはエディターを使い、手動で、文章の前後にある、余分な部分を削除します。前処理したファイルのサイズは167KBと、コンパクトです。
サンプルプログラムを修正します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from __future__ import print_function from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense, Activation from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import matplotlib.pyplot as plt # 追加 import numpy as np import random import sys import io path = './data_rojinto_umi.txt' with io.open(path, encoding='utf-8') as f: text = f.read().lower() print('corpus length:', len(text)) chars = sorted(list(set(text))) print('total chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) # cut the text in semi-redundant sequences of maxlen characters maxlen = 8 step = 1 sentences = [] next_chars = [] for i in range(0, len(text) - maxlen, step): sentences.append(text[i: i + maxlen]) next_chars.append(text[i + maxlen]) print('nb sequences:', len(sentences)) |
25-26行目は、学習のためのデータセットを作る部分です。サンプルプログラムは、40文字単位(maxlen=40)で次の1文字を予測し、それを3文字(step=3)づつずらしながらデータセットを作る仕様になっています。
これはアルファベット一文字づつを対象にしているためで、日本語の場合は漢字があり遥かに情報量が多いため、もっと短くしないと上手く学習出来ません。なので、8文字単位(maxlen=8)で次の1文字を予測し、それを1文字(step=1)づつずらしながらデータセットを作る仕様に変更しました。
|
1 2 3 4 5 6 7 8 9 10 |
def on_epoch_end(epoch, logs): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) start_index = random.randint(0, len(text) - maxlen - 1) start_index = 0 # 毎回、「彼は老いていた。」から文章生成 for diversity in [0.2]: # diversity = 0.2 のみとする print('----- diversity:', diversity) |
エポック毎に、生成文の最初の8文字をテキストから選ぶ部分です。7行目のstart_index で、テキストの何文字目から取得するかをランダムに選んでいますが、生成文のスタートは、毎回同じ方が成長度合いが見やすいので、8行目で強制的に0にしています。これで、毎回テキストファイルの最初の「彼は老いていた。」から文章生成することになります。
9行目の diversity は、数字が大きくなるに従って、予測確率の低い文字もある割合で採用する係数です。サンプルプログラムは、[ 0.2, 0.5. 1.0. 1.2 ] の4種類で文章生成していますが、ここでは 0.2 のみを使っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
history = model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback]) # Plot Training loss loss = history.history["loss"] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.title("Training loss") plt.legend() plt.savefig("loss.png") plt.close() |
サンプルプログラムの最後の部分です。学習ロスの推移を見たかったので、2行目の model.fit の前に history を追加し、8行目から学習ロス推移グラフを描かせる部分を追加しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
from __future__ import print_function from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense, Activation from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import matplotlib.pyplot as plt # 追加 import numpy as np import random import sys import io path = './data_rojinto_umi.txt' with io.open(path, encoding='utf-8') as f: text = f.read().lower() print('corpus length:', len(text)) chars = sorted(list(set(text))) print('total chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) # cut the text in semi-redundant sequences of maxlen characters maxlen = 8 step = 1 sentences = [] next_chars = [] for i in range(0, len(text) - maxlen, step): sentences.append(text[i: i + maxlen]) next_chars.append(text[i + maxlen]) print('nb sequences:', len(sentences)) print('Vectorization...') x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 # build the model: a single LSTM print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars))) model.add(Activation('softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def on_epoch_end(epoch, logs): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) start_index = random.randint(0, len(text) - maxlen - 1) start_index = 0 # 毎回、「老人は老いていた」から文章生成 for diversity in [0.2]: # diversity = 0.2 のみとする print('----- diversity:', diversity) generated = '' sentence = text[start_index: start_index + maxlen] generated += sentence print('----- Generating with seed: "' + sentence + '"') sys.stdout.write(generated) for i in range(400): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] generated += next_char sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() print_callback = LambdaCallback(on_epoch_end=on_epoch_end) history = model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback]) # Plot Training loss & Validation Loss loss = history.history["loss"] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.title("Training loss") plt.legend() plt.savefig("loss.png") plt.close() |
プログラム全体を載せておきます。
プログラムを動かします
テキストが167KBと小さいので、通常のノートパソコンで十分動きます。私のMacbook Air で 60epoch が1時間弱で完了しました。

プログラムを実行すると、まずこんな表示が出ます。テキストの総文字数(corpus length)は56995文字、文字の種類(total chars)は1337種類、学習データセット数(nb_sequence)は56987個という意味です。
その後、約1分毎に400文字の文章が自動生成され、ターミナルに表示されます。これを眺めているのは、結構面白い。

学習したばかりの段階の生成文。「老人」ばっかり出てきますね(笑)。

かなり学習が進んだ段階の生成文。ところどころ、何か意味がありそうなことを言っている様な気がしないでもない(笑)。但し、全体的な文体は、確かに「老人と海」になっているのが凄い!
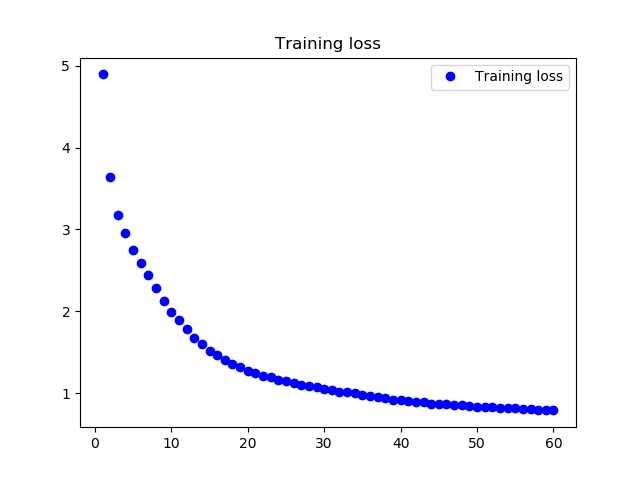
学習ロスの推移グラフです。順調に、学習は進んだようです。
今回は、LSTMによる単純な1文字単位の予測を使った文章生成ですが、PCが一生懸命予測をして文章生成をしているのを見ると、けなげで可愛いです。
では、また。














日本語対応について非常に参考になりました。ありがとうございます。
murata さん
コメントありがとうございます。
それは良かったです。
これからも分かりやすいブログを心がけて行きたいと思います。
今後とも、よろしくお願いします。
はじめまして。株式会社Books&Companyの野村と申します。今、我々の会社ではAIを使った小説制作にチャレンジしています。お忙しいとは存じますが、情報交換等を兼ねてご挨拶させていただきたいのですが、いかがでしょうか。実はほかのAI作家さんにもお声がけさせていただいており、ゆるくコミュニティのようなものが形成できないかと思っております。もちろん、対面ではなく、オンラインのみでも結構です。ご返信いただけますと幸いです。よろしくお願い申し上げます。
野村さん
コメントありがとうございます。
私のブログの文章生成に関して興味を持って頂き、嬉しいです。
ただ、私はディープラーニング関連のコードを趣味で少しいじっている程度でして、とてもAI作家なんて呼べる者ではありませんので、念のため。
昨年から今年に掛けてNLP(自然言語処理)は、ELMo、GPT、BERT、そしてGPT-2と急速に進んでいて、凄いAI作家が生まれる土壌は確実に作られて来ていると思います。
今後も、NLPに関する情報もブログにして行きたいと思っています。ちなみに、3/10のブログはGPT-2をご紹介します。
今後とも、よろしくお願いします。
cedro様
ご返信ありがとうございます(すみません、1週間以上気づきませんでした)。
もしよろしければ、下記メールアドレスにご返信いただけないでしょうか。
ご面会は無理でもオンラインだけでの情報交換ではいかがでしょう。
今日も別のAI作家さんとお会いすることになっております。
実は「AI小説大賞」を開催できればと思い、今いろいろな方にお目にかかっています。
公募文学賞にすれば、学生さんやフリーのプログラマーの方などが参加していただけるのではないかと思っております。
全部で20名のご応募があれば、立派なかつ世界初のイベントになると思います。
どうぞよろしくお願い申し上げます。
[…] Keras LSTMでサクッと文章生成をしてみる 上記サイトの一文字ずつ生成していく版。 単語に分かち書きしない分、こちらの方が理解しやすいです。 […]
とても勉強になる情報をありがとうございます。
いまディーブラーニングに手を染めたばかりなので、このようなサンプルは非常に助かります。
Traceback (most recent call last):
File “5.py”, line 6, in
from keras.optimizers import RMSprop
ImportError: cannot import name ‘RMSprop’ from ‘keras.optimizers’
という,エラーが出てしまいました.
なんででしょうか.どうしたら,実行できるでしょうか.
大橋真由さん
コメントありがとうございます。
Kerasのバージョンが上がって、エラーが出る様です。お手数ですが、
from keras.optimizers import RMSprop を
from tensorflow.keras.optimizers import RMSprop
に変更して下さい。そうすると動かせます。
わざわざ返信ありがとうございます.それでやってみます.