
1.はじめに
今回ご紹介するのは、音声から顔画像を動かす、Live Speech Portraits という技術です。
2.Live Speech Portraitsとは?
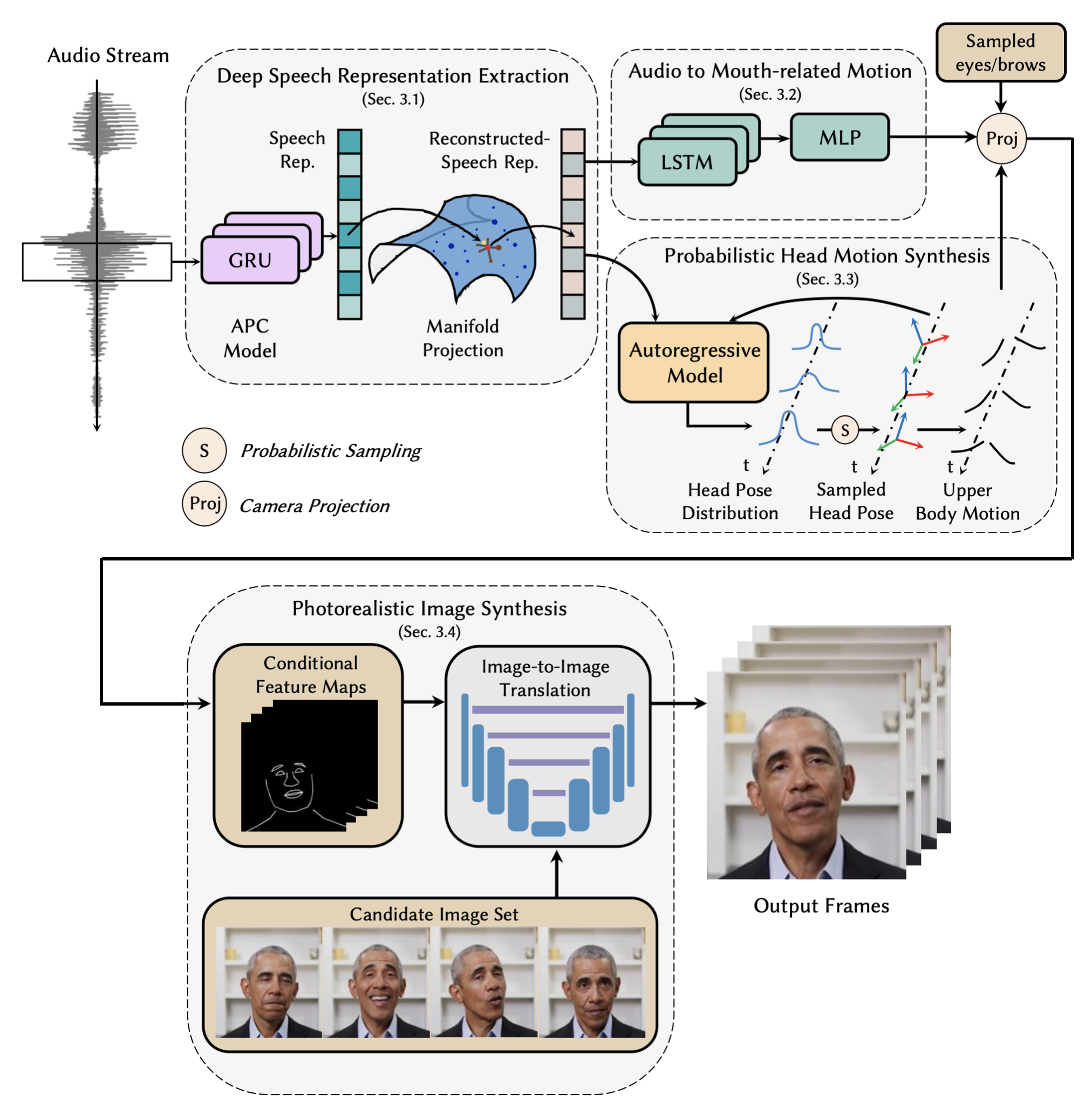
まず、音声(Audio Stream)からGRUとマニホールド投影を使って深い音声表現を抽出します(Deep Speech Representation Extraction)。
そして、LSTMとMLPを使った口の動きの予測(Audio to Mouth-related Motion)と自己回帰モデルを使った頭・上半身の動き予測(Probabilistic Head Motion Synthesis)をそれぞれ行い合成します。
最後に、合成した予測結果を条件付き特徴マップにまとめ、画像翻訳ネットワークで動画のフレームを出力します(Photorealistic Image Synthesis)。
では、早速コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# githubからコードを取得 ! git clone https://github.com/cedro3/LiveSpeechPortraits.git %cd LiveSpeechPortraits # ライブラリーのインストール ! pip install dominate ! pip install sox ! apt-get install sox libsox-dev libsox-fmt-all ! pip install librosa==0.6 ! pip install numba==0.48 # データのダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1L869kfYC5MK4UPfA30oDZvtUioHrh6Li', './live.zip', quiet=False) ! unzip live.zip -d data |
demo.pyを使って、音声に合わせて顔画像を動かしてみましょう。–idの後に人物名(May, McStay, Nadella, Obama1, Obama2)、–driving_audio の後に音声ファイル(wav)を指定します。
自分の用意した音声(wav)を使う場合は、data/input フォルダーに自分のPCからドラッグ&ドロップでアップロードして、–driving_audiodで指定して下さい。
|
1 2 |
# 音声に合わせて顔画像を動かす ! python demo.py --id Obama1 --driving_audio ./data/input/00083.wav |
demo.pyで作成される動画はaviなので、mp4に変換します。下記のコードのresults/の後に、人物/音声ファイル(拡張子なし)/音声ファイルを指定します。
|
1 2 3 4 5 6 7 |
# output.mp4をリセット import os if os.path.exists('./output.mp4'): os.remove('./output.mp4') # aviからmp4に変換 ! ffmpeg -i results/Obama1/00083/00083.avi output.mp4 |
それでは、動画を再生してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
# mp4の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
もう1つやってみましょうか。人物をObama1→May、音声ファイルを00083.wav→osaka.wavに変更して実行すると、
サッチャーが、おかんに説教する大阪の娘に変身します。ぜひ、色々やって楽しんでみて下さい。
では、また。
(オリジナルgithub)https://github.com/YuanxunLu/LiveSpeechPortraits













コメントを残す