今回は、StarGANでセレブの顔を狙い通りに変化させてみたいと思います。
こんにちは cedro です。
以前、CycleGANで2つのドメインの相互変換(馬をシマウマに変換、少女時代のコスチューム入替)をやってみました。
そうすると今度は、複数ドメインの相互変換はどうなのよとなるわけですが、実はそれを実現する StarGANというのがあります。
ということで、今回は、StarGANでセレブの顔を狙い通りに変化させてみたいと思います。
StarGANとは?
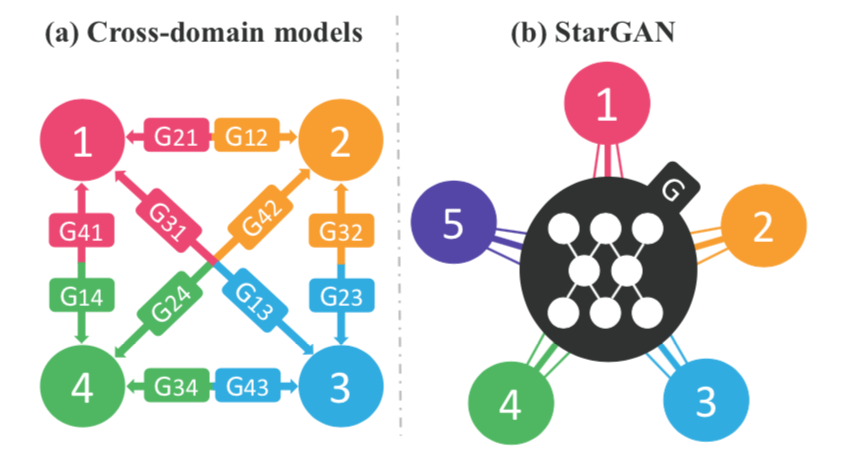
これは論文に出ている、CycleGAN と StarGAN の違いを表す概念図です。
(a)単純に考えると、全てのドメイン間の組み合わせでCycleGANを適用することになる訳ですが、これではGANの数がやたらと多くなり計算コストも莫大になります。
(b)そこで、1つのGANだけを使い、ラベルを使って複数のドメイン間を行き来できるようにしたのが、StarGANです。
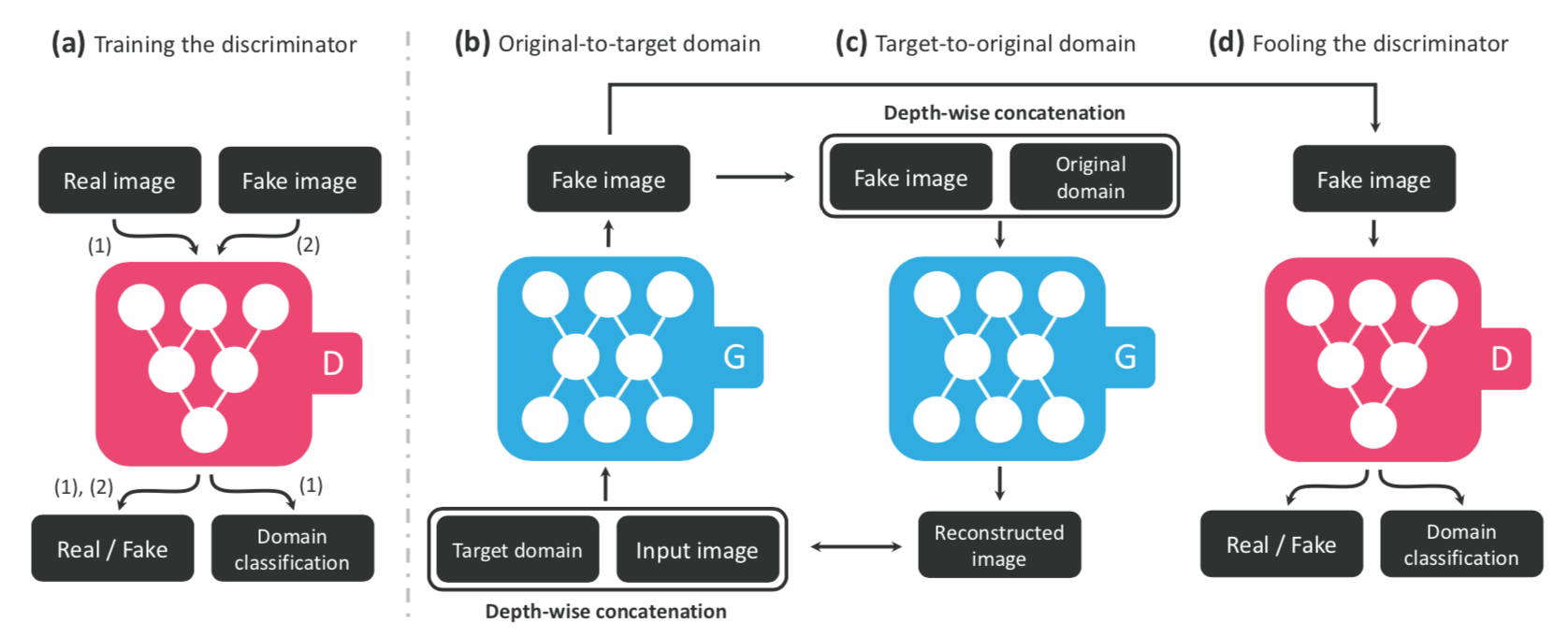
これも論文に出てくる、StarGANの学習プロセスを表す図です。
(a)Discriminator に Real_image とFake_image を入力し、RealかFakeか、どのドメインに属するかを判定させます。
一方、(b)Generator に input_image と目標ドメインを入力して、Fake_imageを生成させます。そのFake_imageを(d)Discriminator へ入力し、RealかFakeかと目標ドメインを判定させます。
それと同時に、そのFake_imageと元ドメインを(c)Generator に入力し、input_image と目標ドメインを再現させ、(b)Generator の入力と比較させます。
もっと詳しく知りたい方は、論文がこちらにあります。
コードを準備します
今回は、Githubにある、yunjey/StarGAN のサンプルコードを使わさせて頂きます。まず、クローンあるいはダウンロードして下さい。
ちなみに、yunjey さんは、StarGANの論文著者の一人です。
|
1 |
bash download.sh celeba |
最初に、CelebAのデータセットを準備します。mac や linux であれば bash が使えますので、上記コマンドを実行するだけです。簡単ですね。
別に、bash が使えなくても問題はありません。以下に、手動でどうやるかも書いておきます。
|
1 |
https://www.dropbox.com/s/d1kjpkqklf0uw77/celeba.zip |
bash が使えない方は、ブラウザに上記URLを入力し、celeba.zip をダウンロードして下さい。容量は、1.32GBです。
そして、ルートに data フォルダーを作成し、celeba.zip を解凍して出来た celeba フォルダーを格納します。これでOKです。
ちなみに、celeba フォルダーの中には、images フォルダー(この中にセレブの顔画像が入っています)と list_attr_celeba.txt (属性ファイル)が入っています。
コードを実行します
|
1 2 3 4 |
python main.py --mode train --dataset CelebA --image_size 128 --c_dim 6 \ --sample_dir stargan_celeba/samples --log_dir stargan_celeba/logs \ --model_save_dir stargan_celeba/models --result_dir stargan_celeba/results \ --selected_attrs Eyeglasses Black_Hair Blond_Hair Brown_Hair Male Young |
学習を実行する時は、コマンド python main.py の引数でどういう動作をさせるのか指定します。
ポイントだけ説明します。1行目の – -mode train が学習の指定で、 – -c_dim 6 は使用する属性の数の指定。4行目は使用する属性の名前の指定です。
ここでは、Eyeglasses, Black_Hair, Blond_Hair, Brown_Hair, Male, Young の6つの属性を使っています。なお、Celeba の属性についての詳しい説明が知りたい場合はこのブログでご覧下さい。
早速、学習させてみましょう。今回はGPUが必須です。属性数6個、200,000 iter を GTX1060 で学習すると約30時間ほど掛かりました。
|
1 |
parser.add_argument('--batch_size', type=int, default=7, help='mini-batch size') # 16 → 7 |
学習が完了したら、今度はテスト(推論)です。ただ、相互変換の結果画像がデフォルトでは16行×7列と縦長過ぎるので、main.py の73行目のdefault = 16 → 7 に変更して、7行×7列で表示させるようにします。
|
1 2 3 4 |
python main.py --mode test --dataset CelebA --image_size 128 --c_dim 6 \ --sample_dir stargan_celeba/samples --log_dir stargan_celeba/logs \ --model_save_dir stargan_celeba/models --result_dir stargan_celeba/results \ --selected_attrs Eyeglasses Black_Hair Blond_Hair Brown_Hair Male Young |
推論時も、コマンド python main.py の引数で動作を指定します。引数は、学習の時とほとんど同じで、1行目の – -mode train を – -mode test に変更するだけです。

生成した画像の中の1つです。一番左の列が Input で、そこから右へ順番に、メガネを掛ける(Eyeglasses)、黒髪に変える(Black_Hair)、ブロンドに変える(Blond_Hair)、茶髪に変える(Brown_Hair)、性別を変更する(Male)、年を取らせる(Young)という属性変化を掛けています。
今回使った CelebA の各属性データの数を見ると、Eyglasses 13,193個、Black_Hair 48,472個、Blond_Hair 29,983個、Brown_Hair 41,572個、Male 84,434個、Young 156,734個 とバラツキが半端ないですが、上手く属性変化が出来ているようです。

男としては、女性だけを見ているのが楽しいかなーということで、今度はInputが女性だけのパターンを選んでみました(笑)。

メガネを掛けている人のメガネ属性(glasses)を変化させると、なんとメガネが消えます。面白いですね。
では、また。














記事を読み、自分でも実行したくなる¥り実行してみました。
そこでお聞きしたいことがあります。
学習したことを実行する際、変換してほしい画像を変換するのにはどうしたらいいでしょうか?
(自分の顔をinputする方法)
お返事お待ちしております。
やふやふさん
コメントありがとうございます。
StarGANの公式コードには潜在変数を探索するコードがないので私には無理ですが、StyleGAN2を使えば自分の顔の属性を変える(向きを変える、笑顔にする、メガネをかける等)ことが簡単に出来ますよ。下記①、②のステップでやってみて下さい。
①「GANの潜在空間に新垣結衣は住んでいるのか?」のコードで自分の顔写真の潜在変数を取得する。
▶︎sample/picに自分の顔写真を3つ入れてコードを実行して潜在変数を取得し、Numpyのバイナリファイルに保存する。
②「StyleGAN2を使って顔画像の編集をやってみる」のコードでその潜在変数を操作する。
▶︎保存したNumpyのバイナリファイルを読み込み、事前に準備してある色々な潜在変数(6, 18, 512)の前半3つと入れ替えてStyle_mixingを実行する。
お試し下さい。
cedroさん
返信ありがとうございます。
無事、実行することができました!
ありがとうございます。
追加で2つ質問があるのですが、
1.「StyleGAN2を使って顔画像の編集をやってみる」で出てきているいくつかの画像(例えば草刈正雄)は、潜在変数から生成された画像なのでしょうか?それとも画像をそのまま使っているのでしょうか?
2.探索した潜在変数によって生成した画像が元の画像とかなり違うのですが、どこかのコードを変更する必要があるのでしょうか?特に目に違和感があります。試行回数を増やしても見たのですが、あまり変化はみられませんでした。。。
初歩的な質問ですいませんがよろしくお願いいたします。
やふやふさん
コメントありがとうございます。
無事動いて良かったです。ご質問に回答します。
1)全て潜在変数から生成した画像です。その潜在変数は「GAN]の潜在空間に新垣結衣は住んでいるのか」のコードで探索(試行回数1000回)したものです。
2)探索した潜在変数によって生成した画像が元の画像を上手く再現できない場合が確かにあります。これは、StyleGAN2が学習した顔画像データセットには出て来なかった顔の要素を含んでいるためだと思われます。
cedeoさん
返信、回答ありがとうございます。
たびたびすいません。
1)試行回数を増やせば増やすほどTargetの画像には近つくものなのでしょうか?
現状、1,000回の試行回数を行なってもあまり再現ができていないのですが、この場合試行回数を3,000回、10,000回と増やしていけばいいってものなのでしょうか?それとも再現には限界があるため、画像を変更した方がいいのでしょうか?
2)「StyleGAN2を使って顔画像の編集をやってみる」で出てきている芸能人の顔が非常に上手く再現できているような気がするのですが、それは顔によって再現できる上限が決まっている(StyleGAN2が学習した顔画像データセットに似たような要素が出てきていた)という認識でよろしいでしょうか?
追加で、、、
3)作成したNumpyのバイナリファイルで編集する時、例えば男性化することを行う際は、1つのNumpyのバイナリファイルに画像をいれた方がよろしいのでしょうか?それとも
vec_test = np.vstack((vec_smile[:3],vec_man[3:]))
style_mixing(vec_test, [4,5,6,7], 1.0)
のように2つのNumpyのバイナリファイル(vec_smileとvec_man)で行っても問題ないでしょうか?
以上、よろしくお願いいたします。
やふやふさん
コメントありがとうございます。ご質問回答します。
1)経験から言いますと、試行回数300で結構イケてる画像を1000回までやると完成度が少し上がる感じです。今のお話ですと画像を変更すべきでしょうね。
2)仰る通り、StyleGAN2で学習した様々な顔のパーツを組み合わせても実現できない場合は上手く行かない様です。そういう意味で限界があります。ちなみにブログで使っている潜在変数は上手くできたものをピックアップして使っています。
3)はい、それで行けます。
cedroさん
返信、ご回答ありがとうございます。
たくさんの質問にお答えいただきありがとうございます。
いろいろと試していきたいと思います。
本当にありがとうございました。