
家賃を推定するニューラルネットワーク
こんにちは、cedroです。
SONYは、Neural Network Libraries の導入事例として、不動産価格の推定を挙げています。
ソニー不動産の「不動産価格推定エンジン」に、Neural Network Librariesが使用されています。この技術を核として、ソニー不動産が持つ査定ノウハウやナレッジをベースとした独自のアルゴリズムに基づいて膨大な量のデータを解析し、不動産売買における成約価格を統計的に推定する本ソリューションが実現されました。本ソリューションは、「おうちダイレクト」や、「物件探索マップ」「自動査定」など、ソニー不動産の様々なビジネスに活用されています。
(SONY Neural Network Libraries のWebページより)
不動産価格を決める要素は様々なものがあって、時とともにその要素がどのくらい不動産価格に効くかも変化してくると思うので、メンテナンスが容易なこのアプローチはありでしょうね。
なんてことを考えながら、そう言えば「今までSONY Neural Network Console で試したのは、分類と画像生成だけだった」ことに気づきました。
と言うことで、今回は、家賃を推定するニューラルネットワークを題材に、回帰問題をやってみます。
データ収集と加工
今回もいつもの様に、とりあえず一通りやってみることを優先し、収集するデータは最小限とします。
データの入手先は、「ライフルホームズ」。よくTVで「おウチ見つかる、ホームズくん」ってCMをやってるところですね。
エリアは、若い女性に人気の「自由が丘」とします。
ライフルホームズのHPから、カテゴリー>借りる>東京>東急東横線>自由が丘 で検索すると917件ヒットしました。
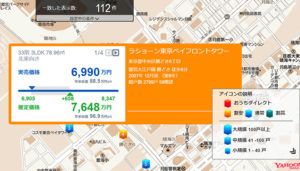
変数は3つ、専有面積、駅徒歩、築年数とします。出力は賃料で管理費込みとしました。
917件のデータの中から、ぞれぞれの変数が適当にばらつく様に、60個をサンプリング。
今回も先回同様、画像でも行列でもなく変数なので、データセットを作るのは、簡単です。
60個のデータを適当に分割(私は、学習用48個と評価用12個にしました)して、CSVファイルを2つ作るだけです。
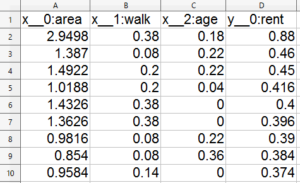
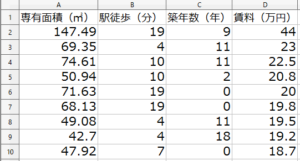
作成する2つのCSVファイルは、こんなイメージ。今回、yはラベルではなく変数なので、xと同様にy__0とします。
データはマニュアルにある様に、おおむね+1~-1にする必要があるので、生データに1/50を掛けています。
xと数字の間、yと数字の間は、マニュアルにも書いてあるように、「ダブルアンダースコア」であることに注意して下さい。
OpenOfficeのCalcで作成したら、CSV形式のUTF-8で保存して下さい(EXCELはマクロを使わないと無理です)。
学習ファイル(私は、rent_train.csv としました)と評価ファイル(私は、rent_test.csv としました)が出来たら、所定のフォルダーに収め(私は、C:直下のSNNC56としました)、SONY Neural Network ConsoleのDATASETに登録しておきます。
プロジェクトの作成
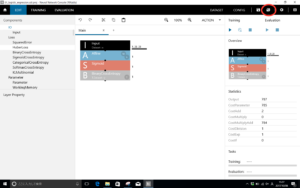
今回流用するプロジェクトは、もっともシンプルな 01‗logistic_regression.sdcproj です。
プロジェクトを読み込んだら、「赤丸」の名前を付けて保存を選んで、SNNC56にプロジェクトを保存します。
そして、必要な箇所を修正します。
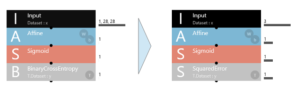
EDIT画面にして、ニューラルネットワークを変更します。
Input:画像から3つの変数に変更するので、1,28,28 → 3
最後のブロックを BinaryCrossEntropy を SquaredError に変更します。この SquaredError は、どういうレイヤーかと言うと
データセットの変数との二乗誤差を最小化するニューラルネットワークの出力層です。ニューラルネットワークにより回帰問題を解く際(連続値を出力するニューラルネットワークを最適化する際)に使用します。
マニュアルより
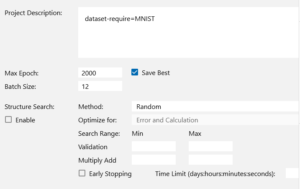
COFIG画面では、評価データが12個しかないのでBatch Sizeは12とし、Max Epochは2000とします。
Max Epochがいつもより大きいですが、回帰問題には学習回数が比較的かかるためです。とは言っても、データは60個だけですから、時間はたいしてかかりません。
DATASETをMNISTから入れ替えたら、学習のスタートです。
学習と評価
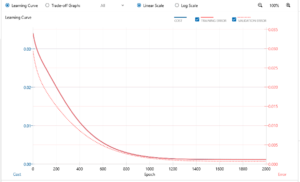
これで学習時間は約20秒。実に綺麗な学習曲線です。回帰問題という特性がそうさせるのでしょうか。
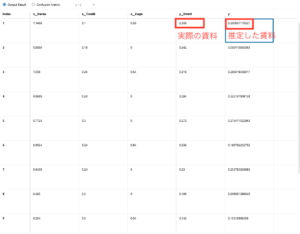
評価を実行して、Output Result の画面にします。x__2:rentが実際の賃料、y__0:rentが推定した賃料です。
一行目のデータをみると、実際0.368のところを0.390と推定しています。推定の結果は実際より+6%(0.390÷0.368-1=0.0597)大きかったようです。
分類問題ではないので、Confusion Matrix の画面はありません。
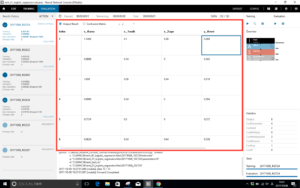
赤枠内で右クリックすると、評価データをCSVファイルでセーブできますので、結果を表計算ソフトで簡単にまとめることが出来ます。
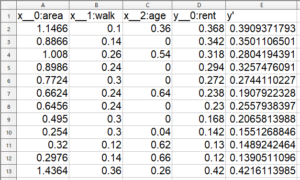
こんなイメージで評価結果データをCSVファイルでセーブできます。
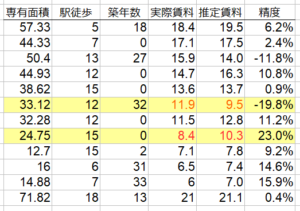
見やすくするためにデータを50倍して元に戻し、精度(推定賃料÷実際賃料-1)を計算すると、ー19.8%~+23.0%にばらついています。おおむね±20%の精度で推定できました。
賃料は、3つの変数だけで決まるわけではありませんので、まずまずの結果ではないでしょうか。
今回、回帰問題を初めてやったのですが、答えが数値で返ってくるのも、結構面白いものですね。
では、また。













コメントを残す