
1.はじめに
いつもは、このブログではディープラーニングの新しい技術をご紹介していますが、今回はちょっと毛色を変えて、その技術を心理学に応用してみるというお話です。
心理学には、顔を平均すると美しい顔になる「平均顔」というテーマがあります。現在、心理学で使われる平均顔を作る手法は、各データから目・鼻・口・顎などの顔のポイントの位置を検出し、各ポイントの平均位置を計算します。そして、各データの顔のポイントを平均位置に合うようにモーフィングして重ねます。そうすると、重なりが大きい部分は濃くなり、重なりが小さい部分は薄くなり平均顔が出来るというものです。
ディープラーニングをご存知の皆さんなら、ちょっと古臭い方法だなと思いますよね。と言うことで、今回は最新の画像生成モデルStyleGAN2を使って、心理学の「平均顔」について深掘りしたいと思います。
2.StyleGAN2をどう使うか
学習済みのGANジェネレータは、入力したベクトルに一対一で対応する画像を出力します。そして、下記の図(2015年DCGANの論文より)から分かるように、そのベクトルは演算することが可能です。
つまり、「平均顔」を求めるための顔画像を出力するベクトルを逆算で求めて、それらのベクトルを平均しGANジェネレータに入力してやれば、「平均顔」が得られるわけです。しかも、メガネを掛けた男性から男性を引くと「メガネ成分」が得られるように、成分計算も出来ます。

画像のベクトルを逆算で求める方法もちゃんとあって、例えば下記の様に専用のエンコーダを使う手法(e4e)を使うと、画像からベクトルへの逆算もあっと言う間です。
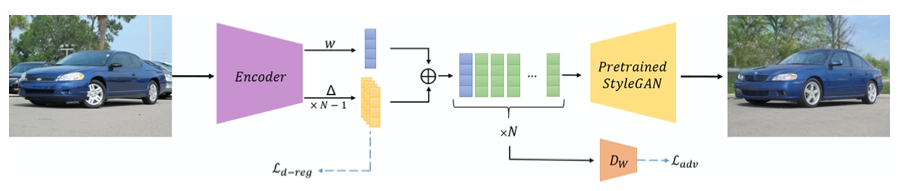
StyleGAN2が「平均顔」の分析に有効なことがお分かり頂けたかと思います。それでは、「平均顔」を深掘りして行きましょう。
3.平均顔を作る
今回の分析に使用するコードはGoogle Colabで動かす形にしてGithubに上げてありますので、まずそれについて説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# --- e4e セットアップ --- import os os.chdir('/content') CODE_DIR = 'encoder4editing' !git clone https://github.com/cedro3/average_face.git $CODE_DIR !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force os.chdir(f'./{CODE_DIR}') from argparse import Namespace import time import os import sys import numpy as np from PIL import Image import torch import torchvision.transforms as transforms sys.path.append(".") sys.path.append("..") from utils.common import tensor2im from models.psp import pSp # we use the pSp framework to load the e4e encoder. %load_ext autoreload %autoreload 2 # 学習済みパラメータのダウンロード import os import gdown os.makedirs('pretrained_models', exist_ok=True) gdown.download('https://drive.google.com/u/1/uc?id=1Du_8FzOPKJhk6aJmiOBhAWVe3_6vAyET', 'pretrained_models/e4e_ffhq_encode.pt', quiet=False) # ランドマークデータのダウンロード ! wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2 ! bzip2 -dk shape_predictor_68_face_landmarks.dat.bz2 # モデルに学習済みパラメータをロード model_path = 'pretrained_models/e4e_ffhq_encode.pt' #### ckpt = torch.load(model_path, map_location='cpu') opts = ckpt['opts'] opts['checkpoint_path'] = model_path opts= Namespace(**opts) net = pSp(opts) net.eval() net.cuda() print('Model successfully loaded!') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# --- ライブラリーインポート&関数定義 --- %tensorflow_version 1.x import numpy as np import scipy.ndimage import os import PIL.Image import sys import bz2 from keras.utils import get_file import dlib import argparse import numpy as np import dnnlib import dnnlib.tflib as tflib import re import projector import pretrained_networks from training import dataset from training import misc import matplotlib.pyplot as plt from tqdm import trange # -------------- フォルダー内画像表示 --------------- def display_pic(folder): fig = plt.figure(figsize=(40, 40)) files = os.listdir(folder) files.sort() for i, file in enumerate(files): img = Image.open(folder+'/'+file) images = np.asarray(img) ax = fig.add_subplot(10, 10, i+1, xticks=[], yticks=[]) image_plt = np.array(images) ax.imshow(image_plt) fig.tight_layout() ax.set_xlabel(str(i+1), fontsize=20) plt.show() plt.close() # -------------- ベクトルから画像を生成・保存 ------------- def vec2pic(vec_syn, dir): network_pkl = 'gdrive:networks/stylegan2-ffhq-config-f.pkl' _G, _D, Gs = pretrained_networks.load_networks(network_pkl) noise_vars = [var for name, var in Gs.components.synthesis.vars.items() if name.startswith('noise')] Gs_syn_kwargs = dnnlib.EasyDict() Gs_syn_kwargs.output_transform = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) Gs_syn_kwargs.randomize_noise = True Gs_syn_kwargs.truncation_psi = 0.5 for i in range(len(vec_syn)): vec = vec_syn[i].reshape(1,18,512) image = Gs.components.synthesis.run(vec, **Gs_syn_kwargs) img = PIL.Image.fromarray(image[0]) img.save(dir+str(i).zfill(3)+'.jpg') |
最初に、平均顔を作成するための画像データから、顔部分を所定の形で角度も考慮して切り取ります(これをalignと言います)。
pathで画像データが入っているフォルダーを指定すると、切り取った顔画像がalignフォルダーに保存されます。ここでは、path = ‘./images/sample1’(アジア系の女性20人)を指定しています。
|
1 2 |
# 画像フォルダーの指定 path = './images/sample1' |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# --- 顔画像の切り出し --- import os import shutil from tqdm import tqdm if os.path.isdir('align'): shutil.rmtree('align') os.makedirs('align', exist_ok=True) def run_alignment(image_path): import dlib from utils.alignment import align_face predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") aligned_image = align_face(filepath=image_path, predictor=predictor) return aligned_image files = sorted(os.listdir(path)) for i, file in enumerate(tqdm(files)): if file=='.ipynb_checkpoints': continue input_image = run_alignment(path+'/'+file) input_image.resize((256,256)) input_image.save('./align/'+file) display_pic('align') |

alignフォルダーに保存された、切り取った顔画像を表示しています。美人の方は少なく(失礼)、割と普通の顔の方が大半だと思います。
次に、この顔画像を生成するベクトルを逆算します。alignフォルダーにある顔画像を生成するベクトルを逆算してvecフォルダーに保存し、そのベクトルから生成した画像をvec_picフォルダーに保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# --- ベクトルの逆算 --- # フォルダーリセット if os.path.isdir('vec_pic'): shutil.rmtree('vec_pic') os.makedirs('vec_pic', exist_ok=True) if os.path.isdir('vec'): shutil.rmtree('vec') os.makedirs('vec', exist_ok=True) img_transforms = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) path = './align' files = sorted(os.listdir(path)) for i, file in enumerate(tqdm(files)): if file=='.ipynb_checkpoints': continue input_image = Image.open(path+'/'+file) transformed_image = img_transforms(input_image) with torch.no_grad(): images, latents = net(transformed_image.unsqueeze(0).to('cuda').float(), randomize_noise=False, return_latents=True) result_image, latent = images[0], latents[0] tensor2im(result_image).save('./vec_pic/'+file) # vec_pic 保存 torch.save(latents, './vec/'+file[:-4]+'.pt') # vec 保存 display_pic('vec_pic') |

vec_picに保存された、ベクトルから生成された顔画像が表示されています。
それでは、ベクトルを順次平均しながら顔画像を生成してみましょう。vecフォルダーに保存されているベクトルを平均してvec_avgに保存し、その平均したベクトルから生成した画像をvec_avg_picに保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# ----------- ベクトルの平均処理 --------- # フォルダー・リセット import os import shutil if os.path.isdir('vec_avg'): shutil.rmtree('vec_avg') if os.path.isdir('vec_avg_pic'): shutil.rmtree('vec_avg_pic') os.makedirs('vec_avg', exist_ok=True) os.makedirs('vec_avg_pic', exist_ok=True) # ベクトルの平均処理 import glob files = glob.glob('./vec/*.pt') files.sort() avg = 0 for i, file in enumerate(files): latent = torch.load(file) avg = (i*avg+latent)/(i+1) torch.save(avg, './vec_avg/'+str(i).zfill(3)+'.pt') # ベクトルを保存 if i == 0: result = avg else: result = torch.cat((result, avg),0) vec = result.to('cpu').detach().numpy().copy() # ベクトルから画像を生成し保存 dir = 'vec_avg_pic/' vec2pic(vec, dir) # 保存した画像を表示 display_pic('vec_avg_pic') |

vec_avg_picフォルダーに保存している画像を表示しています。画像の下にある数字が平均するN数で、N数を増やしたときに、どう平均顔が変化して行くかが分かります。
でも、ちょっと小さいですよね。vec_avg_picフォルダーから間引いてピックアップして見てみましょうか。

画像の下にある数字が平均したN数です。N数が小さい内は顔画像が割と変化しますが、N数が増えるに従って徐々にある顔画像に収束して行くのが分かると思います。
それでは、平均化に使用した顔画像とN=20で平均した画像を比較して見てみましょう。


平均することによって、かなり美人になったと思いませんか。これが平均顔の威力です。心理学の論文では、ラングロフとログマン(1990)が「平均顔が魅力的である」ことを実証実験しています。
平均顔から分かることは、顔を構成するパーツの形は平均的でも、パーツの位置関係を平均することで、かなり美しく見えると言うことです。
人がなぜ平均顔を美しく感じるかについては、配偶者を選ぶ時の基準を「平均顔」にすると生存競争上有利で、その遺伝子が残ったからと言う説があります。なぜ、生存競争上有利かというと、顔の形が整っているということは成長するときに栄養が不足することなく育ち、様々な疾患も少ない傾向がある(これは論文で立証されています)ため、配偶者が健康である可能性が高いからです。
ここで、平均画像が収束して行く状況を可視化してみましょう。1〜N枚目の平均画像のベクトルと1枚目の画像のベクトルとのCOS類似度の推移をグラフ化します。COS類似度は、画像が全く同じとき1、画像が全く異なるとき0となる指数です。
StyleGANのベクトルは、ベクトルを18本まとめた(18,512)のシェイプをしているので18で割っていることに留意下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# --- 平均画像の収束状況確認 --- value = [] for k in range(len(vec)): result = 0 for i in range(18): cos = np.dot(vec[k,i],vec[0,i])/(np.linalg.norm(vec[k,i])*np.linalg.norm(vec[0,i])) result = result + cos/18 value.append(result) import matplotlib.pyplot as plt plt.plot(value) plt.ylabel('cos similarity') plt.xlabel('N') |
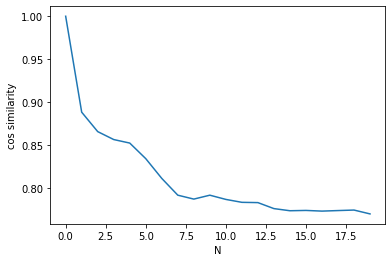
縦軸がcos類似度(cos similarity)、横軸が平均するN数です。10回くらい平均するとCOS類似度が安定し、平均顔がほぼ収束してくることが分かります。
用意した顔画像の多様性(バラツキ)についても数値化しておきましょう。各ベクトルと全ベクトルの平均とのCOS類似度を求めて、1からその平均を引いたものを多様性指数(variance)とします。
18本あるベクトルの内、最初の2本は顔の向きに関係し、9本目以降は細かなテクスチャに影響するものなので、顔の特徴を捉えるときのノイズになりやすいです。そのため、多様性を計算するときには、3〜8本目だけを使っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# -------- 多様性指数 ---------- # ベクトルの読み込み import glob files = glob.glob('vec/*.pt') files.sort() for i, file in enumerate(files): z = torch.load(file) if i == 0: vec = z else: vec = torch.cat((vec, z),0) # 平均ベクトル計算(18, 512) avg = 0 for i in range(len(vec)): avg = avg + vec[i] avg = avg/len(vec) # 各ベクトルと平均ベクトルのCOS類似度計算 var = 0 for i in range(len(vec)): tmp = torch.cosine_similarity(vec[i],avg) # vec[i]と平均ベクトルとのCOS類似度 tmp = torch.sum(tmp[2:8])/6 # 3〜8番目のみの平均をとる tmp = tmp.item() # テンソルから数字を取り出す var = var + tmp var = var/len(vec) var = 1 - var # 数値が大きいほど多様性が大きいにする print('variance = ',var) |
variance = 0.32784092724323277
これが多様性指数(variance)です。この数値が大きいほど多様性(バラツキ)が大きくなります。
さて今度は、男性をやってみましょうか。path = ‘./images/sample3’(アジア系男性20人)を指定して先程同様に分析し、平均化に使用した顔画像とN=20で平均した画像を比較して見てみましょう。


バランスの取れた好青年が現れました。これも、平均に使用した顔画像と比較するとかなり美男子ではないでしょうか。
4.多様性を上げる
平均顔をもっと美しくするには、どうしたら良いでしょうか。1つの方法は、多様性を上げることです。path = ‘./ images/sample2’(アジア系女性10人+欧米系女性10人)を指定して先程同様に分析し、平均化に使用した顔画像とN=20で平均した画像を比較して見てみましょう。


おっ、もう1段グレードアップした感じですよね。前の平均顔と比較してみましょう。

多様性を、0.3278から0.3386へ+0.0108上げることによって、美しさが1ランクアップしたことが分かると思います。
男性も多様性を上げてみましょう。path = ‘./ images/sample4’(アジア系男性10人+欧米系男性10人)を指定して先程同様に分析し、平均化に使用した顔画像とN=20で平均した画像を比較して見てみましょう。


これも、さらにイケメンになった感じですよね。前の平均顔と比較してみましょう。

多様性を、0.3250から0.3425へ+0.0175上げることによって、女性同様美しさが1ランクアップすることが分かると思います。
5.女性成分を加える
平均顔をさらに美しくする方法の2つ目は、女性成分や男性成分を利用する方法です。ベクトルは差を取ると、その方向へ向かう成分が得られます。つまり、女性の平均ベクトルAと男性の平均ベクトルBがあるとき、A-B で女性成分、B-A で男性成分が得られます。これを平均顔に加えると、いわゆる女子力や男子力をUPさせる効果があります。
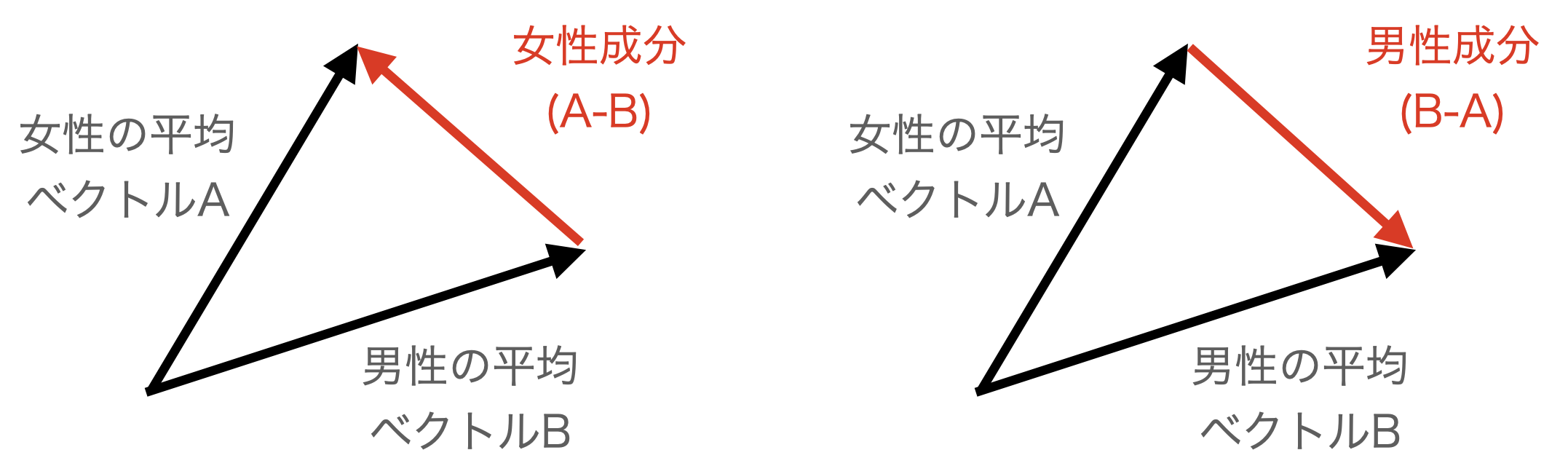
Google colabに、これをシミュレーションするブロックが最後から1つ前にありますので、それを使ってみましょう。./sample/vectorフォルダーに保存されているベクトルから、アジア系女性10人+欧米系女性10人の平均顔ベクトルをx2に、アジア系男性10人+欧米系男性10人の平均顔ベクトルをx4に読み込みます。
例えば、 x2 + (x2 – x4)*0.5 を計算すると、x2に女性成分を50%を加えることになるわけです。図で表現するとこんな感じです。

それではやってみましょう。なお、女性化した画像は、calcフォルダーに保存されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# -------- 女性成分、男性成分 ------- # フォルダーリセット import os import shutil if os.path.isdir('calc'): shutil.rmtree('calc') os.makedirs('calc', exist_ok=True) dir = 'calc/' # 平均顔ベクトルの読み込み x1 = torch.load('./sample/vector/1.pt') # アジア系女性20人の平均顔 x2 = torch.load('./sample/vector/2.pt') # アジア系女性10人+欧米系女性10人の平均顔 x3 = torch.load('./sample/vector/3.pt') # アジア系男性20人の平均顔 x4 = torch.load('./sample/vector/4.pt') # アジア系男性10人+欧米系男性10人の平均顔 x5 = torch.load('./sample/vector/5.pt') # ミス・ジャパン35人の平均顔 x6 = torch.load('./sample/vector/6.pt') # ミスター・ジャパン20人の平均顔 x7 = torch.load('./sample/vector/7.pt') # ミス・インターナショナル30人の平均顔 # ベクトル演算 # ---------------------- z1 = x2 + (x2 - x4)*0.3 # 女性化+30% z2 = x2 + (x2 - x4)*0.5 # 女性化+50% z3 = x2 + (x2 - x4)*1.0 # 女性化+100% z = torch.cat((x2, z1, z2, z3), 0) # (元画像, +30%, +50%, +100%)を表示 # --------------------- z = z.to('cpu').detach().numpy().copy() vec2pic(z, dir) display_pic(dir) |

1が元画像、2が+30%女性化、3が+50%女性化、4が+100%女性化した画像です。+100%まで行くと、少しやり過ぎな感じなので、+50%くらいが良い感じでしょうか。女性化による効果をまとめておきます。

さらに美人度がアップしましたね。心理学の論文では、ローズ(2000)が女性の平均顔に女性成分を加える(方法はStyleGAN2とは異なりますが、本質的には一緒)ことによって平均顔より美しくなると言っています。
次に、男性もやってみましょう。コードは先ほどと同様なので異なる部分のみ記載します。
|
1 2 3 4 5 6 7 |
# ベクトル演算 # ---------------------- z1 = x4 + (x4 - x2)*0.3 # 男性化+30% z2 = x4 + (x4 - x2)*0.5 # 男性化+50% z3 = x4 + (x4 - x2)*1.0 # 男性化+100% z = torch.cat((x4, z1, z2, z3), 0) # (元画像, +30%, +50%, +100%)を表示 # --------------------- |

1が元画像、2が+30%男性化、3が+50%男性化、4が+100%男性化した画像です。だんだん、ゴツゴツした野性味あふれる顔になって行きます。
但し、女性に好まれるのは男性化した顔ではないのです。心理学の論文では、ペレット(1998)が実験によって、女性にとって魅力的なのは男性成分を加えた顔ではなく、10〜20 %女性成分を加えた顔だと言っています。これは、なぜでしょうか?
女性が子孫を残そうとするとき、相手となる男性は野性味あふれる方が生殖能力が高くて良いわけですが、その場合は男性にやり逃げされ、生まれた子供の育成を援助してくれないリスクがあります。そのリスクを避け、長期的に良好な夫婦の関係を重視すると、むしろ少し女性化した男性を選ぶ方が女性にとって子孫を多く残すためには有利な戦略となったのではないか。その結果、そういう遺伝子が残ったとではないかという説があります。
この話には追加のパラメータがあって、リトル(2001)が実験した結果によると、女性の評定者自身が魅力的だと思っていればいるほど(少数派ですが)、男性成分の多い顔を好む傾向があるという結果も報告されています。
これには、自分を魅力的であると思う女性が、野性味あふれる男性の方を好むのは、女性が自分の魅力で野性味あふれる男を繋ぎ止める自信があるためではないかという解釈があります。
また、ウェリング(2008)の論文によれば、女性の評定者自身が自分を性欲が強いと思っていればいるほど(少数派ですが)、男性成分の多い顔を好む傾向があるということも分かっています。
では、男性を+20%女性化したものを見てみましょう。コードは省略します。

少し甘いマスクになりますね。そういえば、ジャニーズは、男っぽい人がほとんどいませんよね。甘いマスクの人ばかりなのは、そういう女性の遺伝子の性質を利用しているのかもしれません。
6.パーツを美しくする
単純平均→多様性UP→女性化と美しさを追求して来たわけですが、今まで見てきた中に究極の美女はいましたか?いませんよね。今までやって来たのは、顔を構成するパーツの位置関係の最適化のみですので。今度は顔を構成するパーツ自体の美しさを追求してみましょう。
path = ‘./images/sample5’(ミス・ジャパン_ファイナリスト34名)を指定して先程同様に分析し、平均化に使用した顔画像とN=34で平均した画像を比較して見てみましょう。


さすがミス・ジャパン、華やかですね。心理学の論文では、カニンガム(1986)が「美人コンテスト平均顔」という考え方で、平均顔よりさらに美しい顔を作り出せると言っています。
顔を構成するパーツが美しいので、単純に平均するだけでもかなりの美しさですね。最初にやった、アジア系女性20人の平均顔と比較してみましょうか。

顔を構成するパーツを見ると、ミス・ジャパンの方が、目・口が大きく、鼻が小さい、という特徴があるように見えます。先ほどのカニンガム(1986)も、「平均顔」と「美人コンテスト平均顔」には、顔を構成する各パーツの形(一部位置関係も含めて)に明らかな差があると言っています。
興味深いのは、多様性指数が0.2760とかなり低いことです。これは、ミス・ジャパンのファイナリストに選ばれた女性は、顔が整ったツブよりの女性が集まっていることの表れではないでしょうか。
男性もやってみましょう。path = ‘./images/sample6’(ミスター・ジャパン_ファイナリスト20名)を指定して先程同様に分析し、平均化に使用した顔画像とN=20で平均した画像を比較して見てみましょう。


さすが、ミスター・ジャパンのファイナリスト、単なる平均顔とは全く違います。最初にやった、アジア系男性20人の平均顔と比較してみましょうか。

レベルが違いますよね。そして、ミス・ジャパンのときと同様、多様性指数は0.2921と低めですね。
さて、今までの流れで言うと、ここから多様性を上げる→女性成分をプラスと進めるわけですが、女性の多様性を上げた「ミス・インターナショナル」の画像は入手できるのですが、残念ながら男性の多様性を上げた「ミスター・インターナショナル」の画像は入手できないんです。
そのため、「多様性を上げる」はパスして、最後の「女性成分をプラス」をやってみましょう。まず、女性の場合です。コードは省略します。

そして、男性の場合です。

7.美人度は測定できるか?
最も美しい顔を決めて、その顔にどれだけ類似しているかをCOS類似度で求めれば、美人度が測定できるかもしれません。
path = ‘./images/sample7’(ミス・インターナショナル_ファイナリスト30人)を指定して分析し、平均化に使用した顔画像とN=30で平均した画像を比較して見てみましょう。


まさに正統派、これがミス・インターナショナルの平均顔です。今回のトライの中で最も美人なのは、この平均顔と言って良いでしょう。この画像にどれだけ似ているか(COS類似度が高いか)で、美人度を測ってみます。Google Colabにそのためのコードが最後のブロックにあります(説明は省略します)。
それでは、sample1(アジア系20人)、sample2(アジア系10人+欧米系10人)、sample5(ミス・ジャパン34名)とミス・インターナショナルの平均顔とのCOS類似度を計算し、分布をまとめてみます。

上段の数字がCOS類似度で、0.5未満、0.5以上〜0.6未満、0.6以上の3つに分け、どの画像が該当するのかをまとめています。ミス・ジャパンは全員0.5以上なので、大きく見れば矛盾はないなと思う反面、細部を見るとまだスッキリしない部分が多々あります。このあたりをどう改善するかは、今後の課題です。
では、また。
(文中にリンクのない画像データ)Flickr-Faces-HQデータセット(FFHQ)
(参考図書)美人の正体 – 外見的魅力をめぐる心理学 – 越智啓太














初めまして。いつも楽しく拝見させて頂いてます。
StyleGAN2をの「平均顔」で日本人の顔でベクトルの逆算をすると
写真のよってはかなり元の顔から乖離する場合があります。
(極端な二重瞼になったり、西洋人ぽくなります)
これはやはり海外の技術を使っているので
仕方のない事なのでしょうか。
nakata_net555さん
仰る通り、学習したデータセットに日本人の顔があまり含まれていないため、そういう傾向が出ています。しかしながら、StyleGANの反転技術は最近かなり進歩して来て、最近ご紹介した下記のブログでは、かなり改善がされていますので、一度お試し下さい。
http://cedro3.com/ai/hyperstyle/
cedroさんのTwitterを拝見し、とてもわかりやすくこちらのブログで解説されているので、
AI技術による画像、音声、動画処理に非常に興味を持ちました!毎日少しずつ試しています。
早速こちらをGoogle Colabで動作させようとしたのですが、
ライブラリーインポート&関数定義でエラーが出てしまいました。
自身で修正をしようと色々調べてやってみたのですが、
tensorflow1.0を現versionでどうしても動作させることができませんでした。
こちらの修正はcedroさんにとって難しいものなのでしょうか?
過去の記事にお手を煩わせてしまうのは申し訳ないので、
もし負担がない範囲であれば修正していただけると非常に嬉しいです。
ソリュンさん
12/1にcolabに組み込みのPythonが3.7から3.8にアップデートされました。
Python3.8では、Tensorflow1.15.0や1.14.0は動きません。
Colabでpython3.7を動かす方法はありますが、結構面倒臭いです。時代は急速に変わっています。もう、Tensorflow1.15.0や1.14.0にはサヨナラする頃なのかもしれませんね。
なるほど、そうだったんですね。ご回答ありがとうございます!
これからもブログの更新楽しみにしています。