
1.はじめに
今まで、画像生成モデルのドメイン変換をする場合、画像生成モデルに変換先ドメインのデータを少量学習(ファインチューニング)させるのが一般的でした。今回ご紹介するのは、画像生成モデルのドメイン変換を変換先ドメインの学習無しで実現する StyleGAN_NADAです。
*この論文は、2021.8に提出されました。
2.StyleGAN_NADAとは?
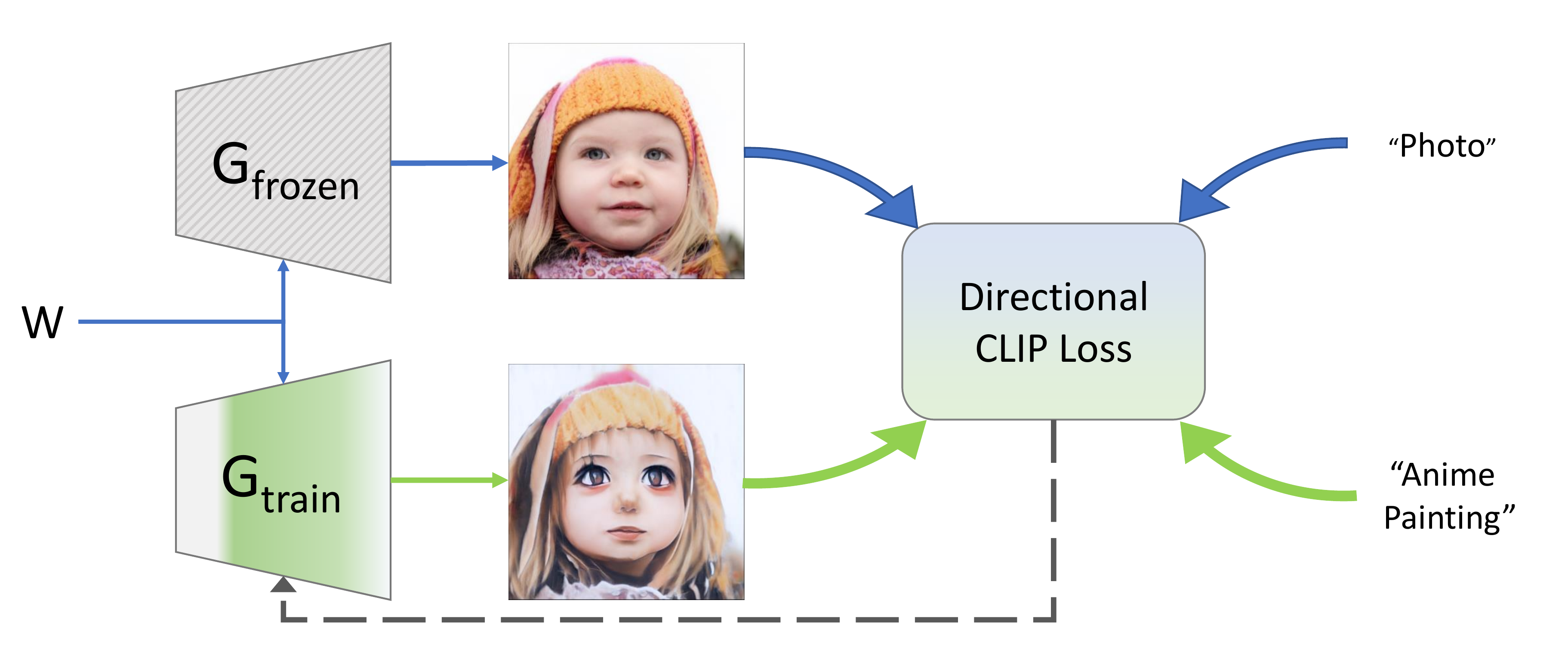
StyleGAN_NADAは、画像とテキストの特徴ベクトルをそれぞれ抽出できるCLIPを用いることで、変換先ドメインの学習無しで、ドメイン変換することが出来ます。下記は、StyleGAN_NADAの概要図です。
変換する画像の潜在変数Wを、パラメータを固定したジェネレーターG_frozenとパラメータを学習するジェネレーターG_trainに入力します。この2つのジェネレーターの生成画像と変換テキスト(「photo」を「Anime Painting」へ変換)をDirectional CLIP Lossに入力します。
Directional CLIP Lossでは、入力された画像とテキストの特徴ベクトルを抽出し3つのロスを計算します。1つ目はG_trainの生成画像の特徴ベクトルと「Anime Painting」の特徴ベクトルの類似度を最大化するためのロスで、これは当然です。
2つ目はG_frozenの生成画像からG_trainの生成画像への特徴ベクトルの差分と「photo」から「Anime Painting」への特徴ベクトルの差分の類似度を最大化するためのロスで、これによって変換の方向が明確になります。
3つ目はG_frozenの生成画像の特徴ベクトルとG_trainの生成画像の特徴ベクトルの距離を最小化するためのロスで、これはG_trainに余計な演出をさせないために加える制約項です。この3つのロスの合計を最小化するG_trainのパラメータを求めます。
それでは、早速動かしてみましょう。
3.Google Colab
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。今回コードは非表示にしてあり、コードを確認したい場合は「コードの表示」をクリックすると見ることが出来ます。
まず、セットアップを行います。色々な種類の画像生成モデルをダウンロードし試してみたい場合は、download_with_pydrive にチェックを入れておくとgoogle colab のダウンロード制限を回避できます(但し、このブロックの処理の時間は少し余分にかかります)。

画像生成モデルは、顔画像「ffhq」選択します。これ以外にも、「cat」、「dog」、「church」、「horse」、「car」があります。

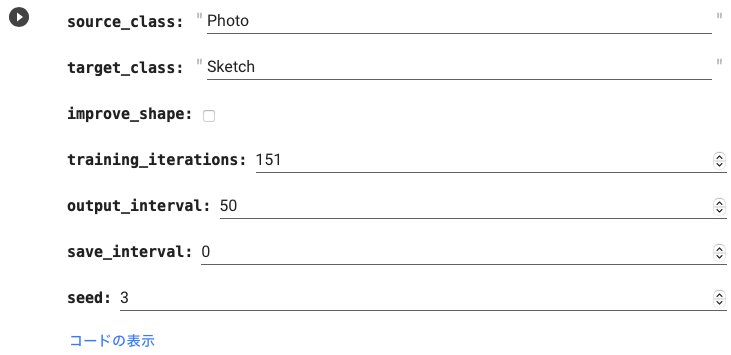
下記の設定を行い、学習を実行します。
- source_class : 元画像のクラス名
- target_class : 変換後のクラス名
- style_image_dir : 変換イメージ画像の保管フォルダー(〜3枚)
- improve_shape : 変換で形が大きく変わる場合に使用(時間がかかるので通常不使用)
- training_iteration : 学習回数
- output_interval : 画像表示・保存間隔。保存先は output/sample
- save_interval : 学習パラメータの保存間隔。保存先は output/checkpoint 。0で保存しません。
- seed : ランダムシードの指定(数字を変更すると画像が変わります)

学習回数を 50, 100, 150 と増やすと徐々に target_class = Sketch に最適化されて行くのが分かります。但し、学習回数は多ければ多いほど良いわけではなく最適値があります。それでは、source_class, target_class, training_iteration を変えて、いくつか試してみましょう。画像は最後のみ表示します。
source_class = face, target_class = illustration, training_iteration = 550

source_class = face, target_class = disney, training_iteration = 150
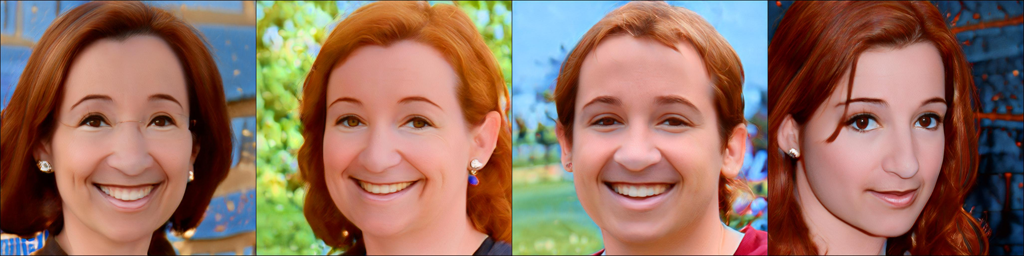
source_class = face, target_class = zombie, training_iteration = 550

それでは、直前で学習したモデルが保持されていますので、これを使ってランダムな潜在変数で画像生成してみましょう。ここでは、直前で source_class = Photo, target_class = Sketch で学習を行った場合を想定しています。trancation(多様性)は0.7で行います。ランダムな潜在変数を使っているので、実行する度に画像は変わります。


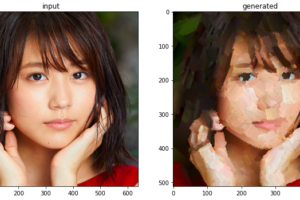
今度は、サンプル画像から潜在変数Wを求めて、同様にドメイン変換してみましょう。まず、画像から潜在変数を求めるエンコーダーを読み込みます。


次に、content/sample にある 001.jpg〜016.jpg のサンプル画像から、001.jpg を読み込んで、顔部分を所定の位置で切り取り、潜在変数を求めます。


求めた潜在変数から先程学習したモデルで画像を生成します。


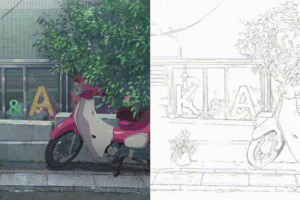
他のサンプルもいくつか試してみましょう。



ドメイン変換の質はCLIPの性能に制約を受けるわけですが、それにしても、変換先ドメインのデータを全く学習しなくても、ドメイン変換ができるのは面白いアイディアですね。
では、また。
(オリジナルgithub)https://github.com/rinongal/StyleGAN-nada
2021/10/11追記 StyleGAN -NADAで遊べるWebサービスが開設されました。 https://replicate.ai/rinongal/stylegan-nada このサイトでは、下記のような動画が作成できます。











コメントを残す