
今回は、転移学習の実験をやってみて、その効果を確認してみます
こんにちは cedro です。
先回、学習データが少ない時に、認識精度を上げる手法として画像データの水増しを取り上げ、ImageAugmentation レイヤーを使った効果を確認しました。。
ところで、学習データが少ない時に、認識精度を上げる手法はもう1つあります。
ある領域で大量のデータを使って学習したモデルを利用して、別の領域で学習をさせることを考えます。
その際、低次のレイヤー(エッジや基本形状などを検出)は以前学習した内容を保持し、高次のレイヤー(物体全体の特徴量を検出)のみ学習させることで、少ないデータでも効率的な学習が可能になります。
これが転移学習(Transfer Learning)です。
今回は、Neural Network Console で転移学習の実験をやってみて、その効果を確認してみます。
実験の考え方
通常、ディープラーニングのフレームワークには、Alexnet 、VGGnet 、LesNet、GoogleNet 等の有名なネットワークに Image Net 等の大量のデータを使って学習させた 学習済みモデルが用意されていて、それを利用して転移学習するのが一般的です。
*Keras、Chiner、Tensoleflow、Caffe等には当然有ります。
しかし、Neural Network Console には、まだ学習済みモデルがありませんので、今回は実験というスタイルになります。
*SONYさんの今後の対応に期待です。
さて、今回の実験をどうするかですが、

一般物体認識のベンチマークとして有名な CIFAR10 というデータセットがあります。このブログで何度も登場しているので、おなじみですよね。
CIFAR10は、飛行機~トラックの10クラスの画像で、学習データが各クラス5,000枚づつありますが、結構識別は難しいです。
そして、さらにもう一段識別を難しくしたのが CIFAR100というデータセットです。
CIFAR100 は、海洋哺乳類~乗り物の100クラスの画像で、学習データが各クラス500枚づつしかなく、さらに識別が難しいです。
今回は、CIFAR100をゼロから学習する場合と CIFAR10の学習済みモデルで CIFAR100を学習する場合とを比較してみたいと思います。
一度、飛行機~トラックの画像を学習した経験があれば、未経験の場合よりも、新たな画像を効率的に学習できるという考え方です。
実験の設定

ネットワークは、以前 VGGnet を参考に設計した mini_VGGnet_mark2 を使います。
このネットワークは、VGGnet をスケールダウンしたモデルですが、時代考証は無視して、当時はまだ発表されていなかった Batch Normalization を全てのConvolution の後に配備して、それなりに認識精度を強化したものです(笑)。
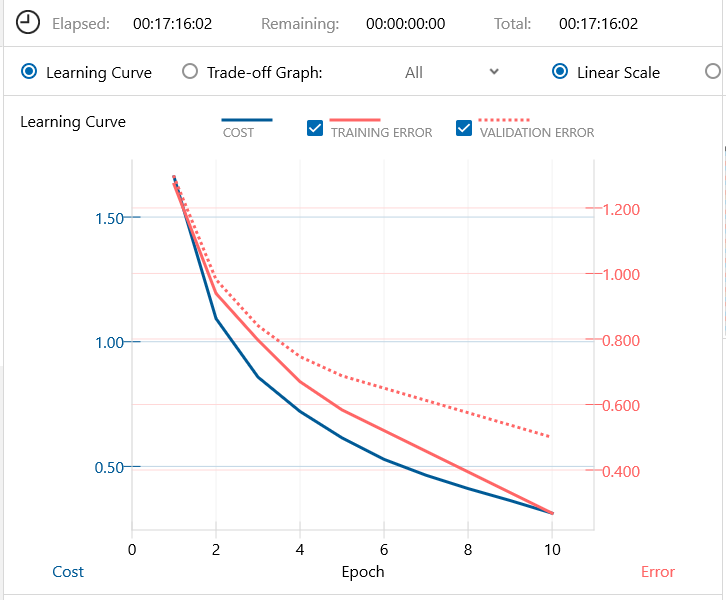
学習済みモデルは、その時にCIFAR10を17時間16分掛けて10エポック学習したものを使います。
たった10エポックの学習結果が学習済みモデルというのは誠に寂しい限りですが、私のGPU無しの環境ではこんなところです。まあ実験ということでご容赦下さい。
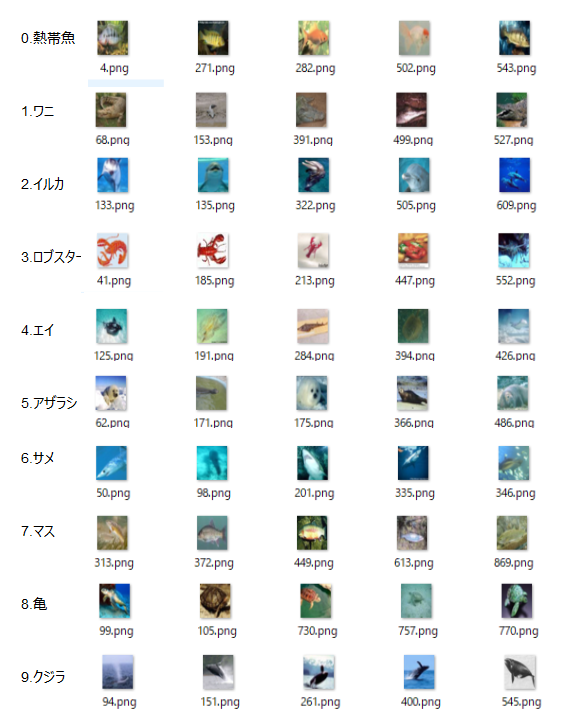
実験データセットは、学習済みモデルが10分類なので、CIFAR100の100クラスの学習データから10クラスを選んで作成しました。
CIFAR10が、乗り物(4種類)や陸の動物(6種類)の画像ですので、新しいものということで海や水辺の動物の画像を選んでみました。
各クラス500個の学習データを元に、学習:評価=8:2で振り分けたので、最終的に学習データは、各クラス400個になりました。
これで、学習用データ4,000個、評価用データ1,000個の実験データセットが出来ました。
実験をしてみます
まず、学習無しモデルで、実験データセットを学習してみます。
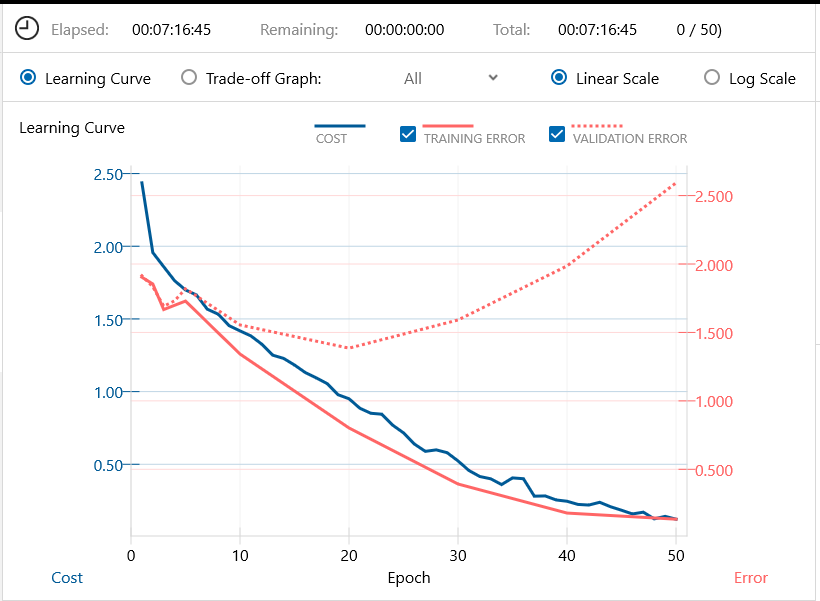
バッチ64、エポック50で学習を開始します。7時間16分で学習完了です。
中々 cost 曲線や Training error 曲線が下がらない一方で、Validation error は上昇の一途です。

Confusion Matrix です。さすが CIFAR100 、手強いです。認識精度は57.4%です。
さあ、今度は学習済みモデルを使った学習です。
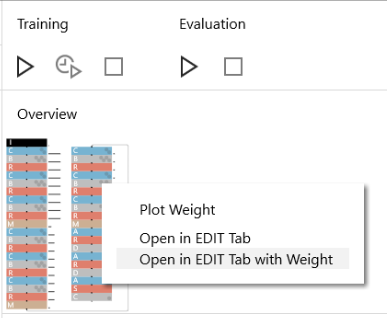
TRAINING 画面にして、Result History の中から目的のものを選択し、右上の Overview の部分で右クリックをし、「Open in EDIT Tab with Weight 」を選択します。そうすると、ネットワークが学習した重み付きで読み込まれます。
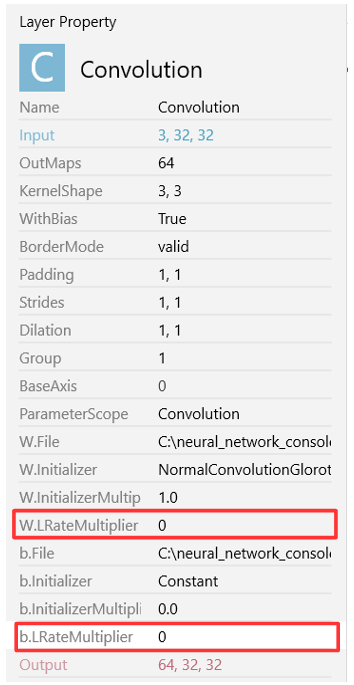
ネットワークの重みを学習するレイヤーの内(今回は Convolution 9個 とAffine 3個が対象です)、新たな学習はしないレイヤーを選んで、W.LRateMultiplier と b.LRateMultiplier を「0」に設定します。
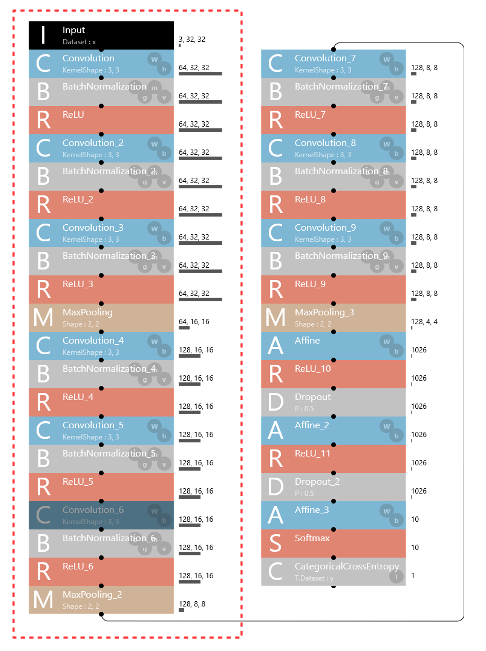
今回、赤い点線で囲んだ範囲(Convolutio の1~6)は新たな学習はしないことにします。つまり今回学習するのは Convolution の7~9と Affine の1~3のみとなります。
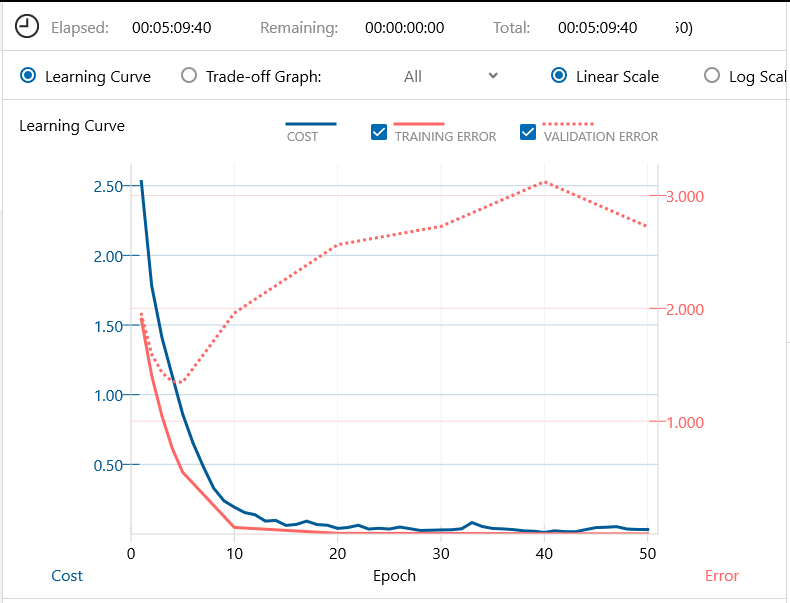
学習済みモデルを、同じくバッチ64、エポック50で学習スタートします。学習時間は、5時間9分と先程より2時間くらい短いです。
低次レイヤーが学習済みのためか、cost曲線、Training error 曲線とも比較的早く収束して来る一方で、Validation error 曲線も戻して来ています。
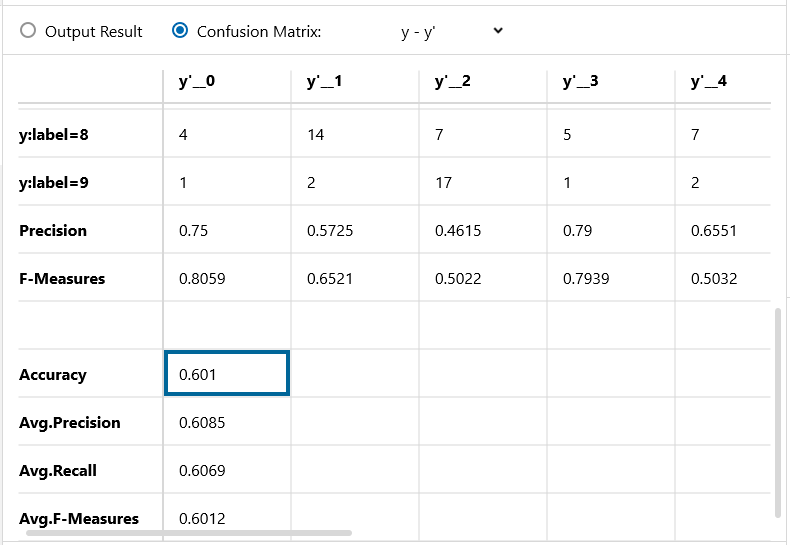
Confusion Matrix です。認識精度は60.1%で、学習済みモデルを使うことによって、識別精度が+2.7%改善し、収束も早くなりました。
学習済みモデルがショボイので、効果は小さいですが、通常の学習済みモデルを使えば、かなりの効果が期待できることが分かって頂けると思います。
SONYさん、学習済みモデルの設定、よろしくお願いします!(笑)
では、また。
PS. CIFAR10、CIFAR100のデータセットを読み込む方法
以前ブログで、Neural Network Console は Ver1.10から、CIFAR10 と CIFAR100 のデータセットを読み込むプログラムが追加され、そのプログラムを動かすためには、NNabla のインストールが必要とご説明していました。
しかし、NNabla のインストールの必要がない、もっと簡単な方法がありました。
誰もが一番最初に試してみる、01_logistic_regression を開いて、CONFIG画面にします。

そして、Project Description の記載を、dataset-require=MNIST から dataset-require=CIFAR10 に変更して、セーブします。
この後、01_logistic_regression を再び開くと、
こんなポップアップが出るので、「はい」を押せば、CIFAR10のダウンロードが開始し、データセットが作成されます。
なんと、CONFIG画面の Project Description に記述してあるデータセットが無いと、該当するプログラムが自動的に動く仕掛けになっているんです。
さすが、SONYさん!














コメントを残す