
今回は、NNabla DCGANの学習済みモデルを使って、顔画像のモーフィングをやってみたいと思います。
こんにちは cedro です。
前回は、DCGANの学習済みモデルを使って、入力(ランダムノイズ)にオフセットを加えることで、生成する顔画像の「顔の向き」をコントロールしてみました。
しかし、これで終わっては、せっかく作ったDCGANの学習済みモデルがもったいないので、もうちょっと何か活用方法がないかなと色々考えていました。
そうした中、適当な「右向き」画像のベクトルと「左向き」画像のベクトルを見つけて、その間のベクトルを細かく補完して作成し、学習済みモデルにそのまま入力として与えてやれば、顔画像が「右向き」から徐々に「左向き」に変化する、いわゆるモーフィングがお手軽にできるのではないかと思いつきました。
ということで、今回は、DCGANの学習済みモデルを使って、顔画像のモーフィングをやってみたいと思います。
前回のプログラムを修正します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
from __future__ import absolute_import from six.moves import range import numpy as np import nnabla as nn import nnabla.logger as logger import nnabla.functions as F import nnabla.parametric_functions as PF import nnabla.solvers as S import nnabla.utils.save as save from args import get_args import os def generator(z, maxh=1024, test=False, output_hidden=False): """ Building generator network which takes (B, Z, 1, 1) inputs and generates (B, 3, 64, 64) outputs. """ # Define shortcut functions def bn(x): # Batch normalization return PF.batch_normalization(x, batch_stat=not test) def upsample2(x, c): # Twise upsampling with deconvolution. return PF.deconvolution(x, c, kernel=(4, 4), pad=(1, 1), stride=(2, 2), with_bias=False) assert maxh / 16 > 0 #with nn.parameter_scope("gen"): # (Z, 1, 1) --> (1024, 4, 4) with nn.parameter_scope("deconv1"): d1 = F.elu(bn(PF.deconvolution(z, maxh, (4, 4), with_bias=False))) # (1024, 4, 4) --> (512, 8, 8) with nn.parameter_scope("deconv2"): d2 = F.elu(bn(upsample2(d1, maxh / 2))) # (512, 8, 8) --> (256, 16, 16) with nn.parameter_scope("deconv3"): d3 = F.elu(bn(upsample2(d2, maxh / 4))) # (256, 16, 16) --> (128, 32, 32) with nn.parameter_scope("deconv4"): d4 = F.elu(bn(upsample2(d3, maxh / 8))) # (128, 32, 32) --> (64, 64, 64) with nn.parameter_scope("deconv5"): d5 = F.elu(bn(upsample2(d4, maxh / 16))) # (64, 64, 64) --> (3, 64, 64) with nn.parameter_scope("conv6"): x = F.tanh(PF.convolution(d5, 3, (3, 3), pad=(1, 1))) return x # Fake path nn.clear_parameters() z = nn.Variable((1, 100, 1, 1)) fake = generator(z) y = fake # 学習済みパラメーターの読み込み nn.parameter.load_parameters(".\\generator_param_130000.h5") # Create monitor. import nnabla.monitor as M monitor = M.Monitor("c:\\Users\\jun40\\dcgan_mor") monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=1, num_images=1, normalize_method=lambda x: x + 1 / 2.) # CSV file import csv read_fp=csv.reader(open("vector.csv","r")) i=0 for line in read_fp: line=list(map(float,line)) vector=np.reshape(line,[100,1,1]) z.d = vector y.forward() monitor_fake.add(i, fake) i=i+1 |
プログラムでは、そのCSVファイルから1行づつベクトルを読み出し、そのベクトルをそのまま入力として、画像生成する仕様にしています。
生成する画像はカラー64×64、生成枚数はCSVファイルに記録されているデータ数(行数)分です。dcgan_mor.py で保存します。
CSVファイルを準備します
前回作成したプログラムを使って、ランダムに画像生成させ、気に入った「右向き」画像と「左向き」画像を見つけ、そのベクトルを調べます。
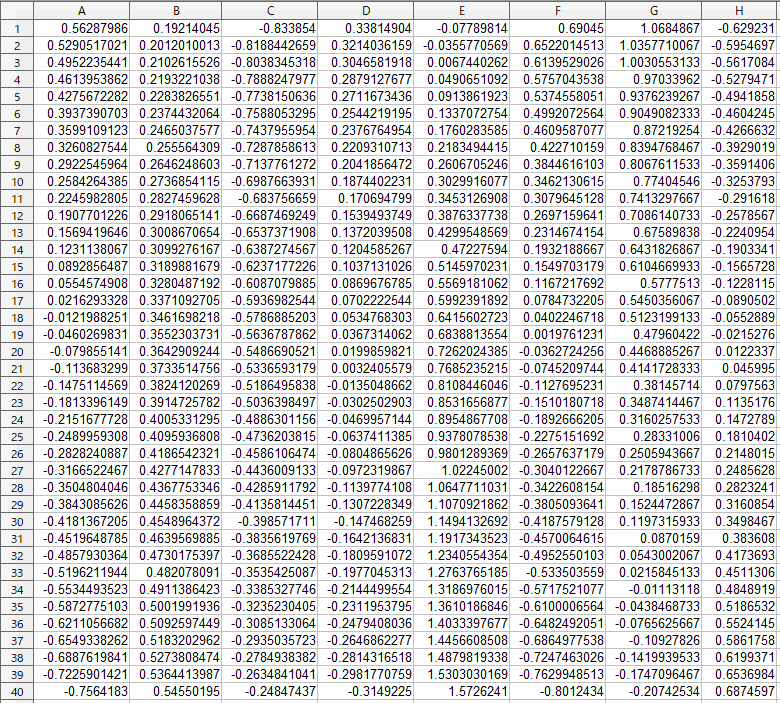
「右向き」から「左向き」まで、40個のベクトル(100次元)を作成します。
Calcで、1行目に「右向き」画像のベクトルをコピーし、40行目に「左向き」画像のベクトルをコピーして、2行目から39行目は各次元毎に単純平均で補完します。
これをコピーして、CSVファイル(vector.csv)を作成します。
プログラムを実行します
必要なプログラムを格納し、> Python dcgan_mor.py でプログラムを実行します。

おおっ!思ったよりもかなり綺麗な出来です。単純平均による補完なので、途中はかなり画像が崩れるかと心配したのですが、スタートとエンドの画像が似通っているせいか、問題ないようです。

作成した40枚の画像を使ってGIF動画(表示切替0.1秒/枚)にしてみました。結構いけます!
さらに調子に乗って、「右向き」→「左向き」→「右向き」とやってみます。

合計80枚の画像のGIF動画(表示切替0.1秒/枚)です。
やっぱり画像、そしてさらに動画となると、燃えますねー(笑)。
では、また。













コメントを残す