
1.はじめに
前回のブログ「GANの潜在空間に新垣結衣は住んでいるのか?」で分かったことは、StyleGAN2の学習済みモデルでは、任意の顔画像を生成する潜在変数を簡単に見つけられるということです。
ということは何か編集したい顔画像があるとき、StyleGAN2を使ってその顔画像を生成する潜在変数を見つけて、その潜在変数を操作すれば画像編集が可能になるはずです。
今回は、StyleGANが持つ特徴である、Style Mixingという手法を使って、新規画像をどれだけ編集する能力があるのかを見て行きたいと思います。
2.Style Mixingとは?
StyleGANは、今までのGANの様に1個の潜在変数Zから直接画像生成するのではなく、Mapping networkを使って潜在変数Zを潜在変数W(W0〜W17)にマッピングしてから画像生成を行います。
潜在変数Wはどういう形をしているかと言うと、
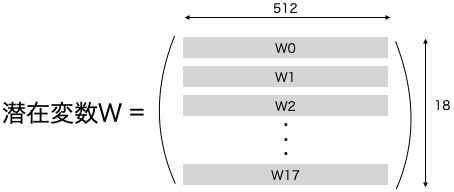
np.ndarrayで18行×512列の行列の形をしています。そしてW0〜W17が、StyleGANのSynthesis networkの各層に解像度低い方から順番に2個づつ入力されます。
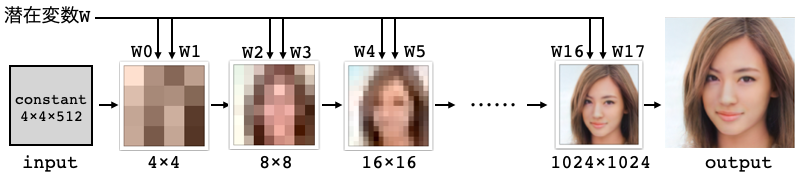
解像度によって画像生成をコントロールする内容は異なり、低解像度では顔の向き、顔の形、髪型など大局的なものをコントロールし、解像度が上がるに従って、目・口など細部のものをコントロールします。
ここで、下記の様に笑顔を出力するもう1つの潜在変数W’ があるとします。
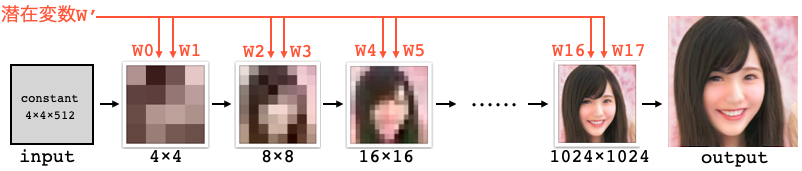
このとき、潜在変数WのW4, W5を潜在変数W’ のものに入れ替えると、
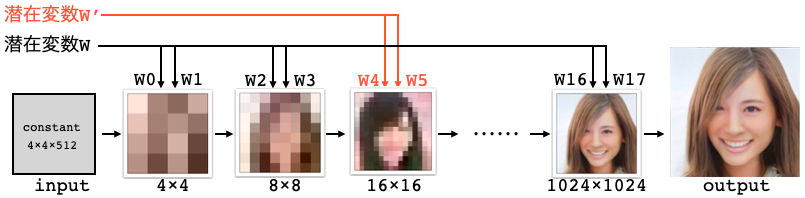
こんな風に出力画像は笑顔に変化します。これは、16×16の解像度に入力されているW4, W5が笑顔かどうかを決めるポイントである口をコントールするためです。このように、2つの潜在変数Wをミックスすることによって新たな画像を生成しようと言うのがStyle Mixingと呼ばれる手法です。
今回のコードもNVIDIAのStyleGAN2の公式コードを元に、Google Colabで動かすような形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
3.セットアップ
最初に、tensorflow1.15.0 を動かすために必要な cuda10.0 をインストールします(2022.10よりgoogle colab からcuda10.0が削除されたため)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title install cuda10.0 # download data !wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !rm /etc/apt/sources.list.d/cuda.list !sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub !sudo apt-get update !wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt install -y ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt-get update # install NVIDIA driver !sudo apt-get -y installnvidia-driver-418 # install cuda10.0 !sudo apt-get install -y \ cuda-10-0 \ libcudnn7=7.6.2.24-1+cuda10.0 \ libcudnn7-dev=7.6.2.24-1+cuda10.0 # install TensorRT !sudo apt-get install -y libnvinfer5=5.1.5-1+cuda10.0 \ libnvinfer-dev=5.1.5-1+cuda10.0 !apt --fix-broken install |
次に、githubからコードを取得します。
|
1 2 3 4 |
!pip install tensorflow==1.15.0 !pip install keras==2.2.4 !git clone https://github.com/cedro3/stylegan2.git %cd stylegan2 |
次に、使用する関数を定義します。コードの記載は省きますが、項目のみ記載します。
- display(vec_syn): 潜在変数vec_syn(n, 18, 512) によって生成されるn個の画像を表示します。
- generate_gif(vec_syn, idx): 潜在変数vec_syn(n, 18, 512)の中から指定したインデックス順に生成画像をトランジションさせるGIF動画を作成します。
- style_mixing(vec_syn, col_styles, truncation_psi): 潜在変数vec_syn(6, 18, 512)の中で指定したWの入れ替えを行った画像を作成します。
4.今回準備した潜在変数を見てみる
今回、用意した潜在変数は、以下の様な手順で作成したものです。詳細は、[こちら]を参照下さい。ご自分でも簡単に作れますので、ぜひやってみて下さい。
- 元画像の収集
- 顔画像の切り出し
- マルチ解像度データセットの作成
- 目的の画像を生成する潜在変数の探索
sampleにある潜在変数を読み込みます。vec_all.npyは全ての画像を集めたもので、それ以外はStyle Mixingのテスト用です。
|
1 2 3 4 5 6 7 |
vec_direction = np.load('sample/vectors/vec_direction.npy') vec_smile = np.load('sample/vectors/vec_smile.npy') vec_glass = np.load('sample/vectors/vec_glass.npy') vec_young = np.load('sample/vectors/vec_young.npy') vec_old = np.load('sample/vectors/vec_old.npy') vec_man = np.load('sample/vectors/vec_man.npy') vec_all = np.load('sample/vectors/vec_all.npy') |
下記のコードで、vec_allによって生成される画像の一覧を表示します。
|
1 |
display(vec_all) |

この様に、今回用意したのは、女性、メガネ女子、男性、熟女、子供など様々なジャンルの顔画像を生成する潜在変数です。ここで表示した顔画像は全て潜在変数から生成されていますので、いわゆるモーフィングは簡単に作成できます。ちょっとやってみましょうか。
|
1 2 3 |
from IPython.display import Image generate_gif(vec_all, [9, 11, 21, 17]) Image('./my/gif/anime_256.gif', format='png') |

潜在変数vec_allの9番目→11番目→21番目→17番目を少しづつ変化させて画像を生成してトランジションさせてみました。
5.StyleMixing
先程定義した関数 style_mixing()について詳細を説明します。
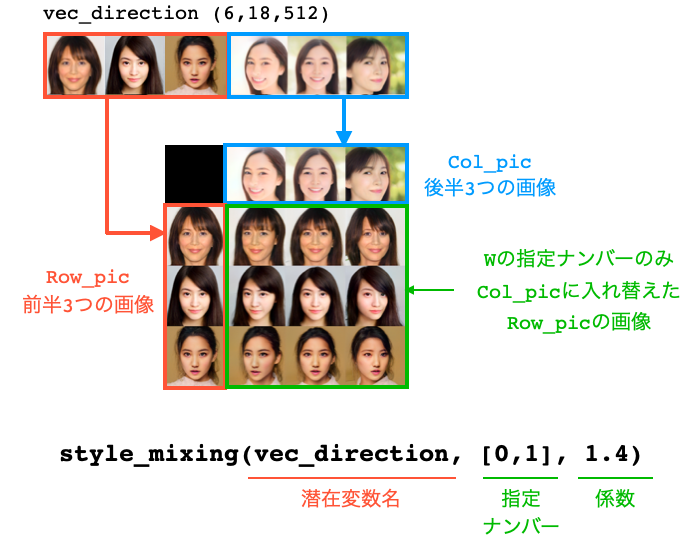
シェイプが(6, 18, 512)の潜在変数名について実行すると、前半3つが生成する画像をRow_picに、後半3つが生成する画像をCol_picに表示します。そして、Row_picとCol_picの交差するところに、Wの指定ナンバーのみCol_picに入れ替えたRow_picの画像を表示します。
係数は、入れ替えたWに掛ける係数です。通常は1で、効きを小さくしたい場合は1未満に、効きを強めたい場合は1を超える数値にします。
6.顔の向き
それでは、まず顔の向きをコントロールしてみます。
|
1 2 |
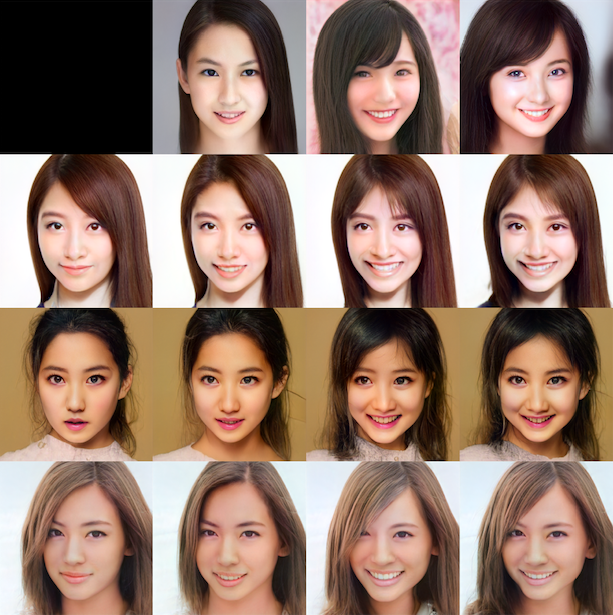
# Face_direction style_mixing(vec_direction, [0,1], 1.4) |

これは、Row_pic の W0, W1 をCol_picに入れ替えたものです。W0, W1 は一番解像度の低い4×4に入力されるので、主に顔の向きやメガネの有無くらいにしか影響を与えません。なので、顔の向きだけを独立して変更することができます。
そのまま置き換えると効きが弱かったので、Col_pic の w0, w1 を1.4倍して、Row_pic と入れ替えています。
ちなみに、Col_pic の2番目の潜在変数は何かの画像から探索して見つけ出したのではなく、1番目と3番目の潜在変数の平均を使っています。こんなことが出来るのも、潜在変数で画像編集するアドバンテージです。
7.笑顔
つづいて、笑顔のコントロールです。
|
1 2 |
# Smile style_mixing(vec_smile, [4,5], 1.0) |
この画像は、Row pic の W4, W5 をCol_picに入れ替えたものです。笑いのポイントである口の形をコントロールするのは主に W4, W5 です。口の開け方が割とそのまま移動している感じですので、笑い方のニュアンスも編集できそうです。
8.メガネ
つづいて、メガネの有無のコントールです。
|
1 2 |
# Glass style_mixing(vec_glass, [0,1,2], 1.0) |

これは、Row_picの W0, W1, W2 をCol_picに入れ替えたものです。メガネに影響与えるのは主にW0, W1, W2 です。顔の向きと被ってしまうので、顔の向きも同時に変わります。
興味深いのは、メガネの形がそのまま移動するのではなく、Row_pic が個別に持つメガネの属性があるようです。従って、意図した形のメガネを掛けさせることは難しいです。
さて、そうするとメガネを外すことも出来そうですよね。それを試してみるには潜在変数vec_glassの前半と後半を入れ替えてやれば良いので、
|
1 2 3 |
# UnGlasses vec_glass1 = np.vstack((vec_glass[3:],vec_glass[:3])) style_mixing(vec_glass1, [0,1,2], 0.8) |

狙い通りメガネは外せました。しかし、Row_picの1行目と2行目はどこか違和感がありますよね。うーん、逆は難しいんでしょうか。
9.少女化
つづいて、少女のようにしてみます。
|
1 2 |
# Young style_mixing(vec_young, [4,5,6,7], 0.8) |
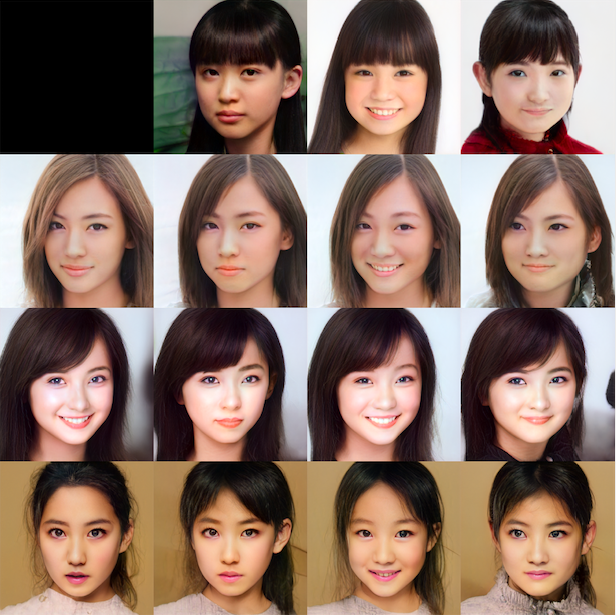
これは、Row_picの w4, w5, w6, w7 をCol_picに入れ替えたものです。顔の形や髪型が影響するw2, w3はそのままにして、口の形に影響するw4, w5 と目の形に影響する w6, w7だけを入れ替えています。
目と口の形を変えたり、特に目と口の位置関係を寄せると、結構幼さが出ますね。
そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=2:8でミックスして、Row_picに入れています。
10.熟女化
さて、今度は熟女の方を持って行きたいと思います。
|
1 2 |
# Old style_mixing(vec_old, [4,5,6,7], 0.6) |

先程同様、顔の形や髪型が影響するw2, w3はそのままにして、目の形や口の形に影響する w4, w5, w6, w7 だけを入れ替えています。目と口の形を変えるだけでも、少し歳をとった様に見えます。
そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=4:6でミックスして、Row_picに入れています。
11.男性化
最後に男性化です。
|
1 2 |
# Man style_mixing(vec_man, [4,5,6,7], 1.0) |

これはおまけです。同じく、w4, w5, w6, w7だけを入れ替えていますが、結果はイマイチですね(笑)。
12.まとめ
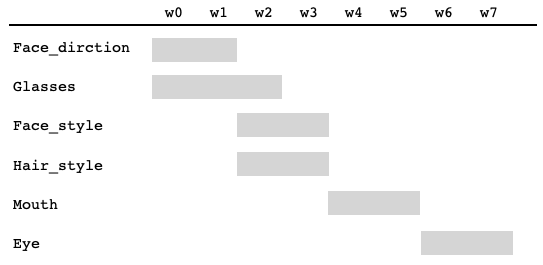
これは、顔画像の要素と関係する主な潜在変数wをの関係を大まかにまとめたものです。w8以上はコントラストや色などへの影響に留まり、直接顔への影響はほとんどないようです。
さて、学習済みStyleGAN2モデルを使った新規画像の編集は、面白いんですが実用面から見るとちょっと難しいかもしれませんね(笑)。
では、また。













記事を拝見させていただきました。
自分でも実際にやってみたいと思い、作成したのですがうまくいきませんでした。
もしよろしければ、GitHubにコードを載せていただけませんでしょうか。
yafuyafuさんへ
コメントありがとうございます。
コードは、( https://github.com/cedro3/stylegan2/blob/master/Edit_new_image.ipynb )
で表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせますので、お試し下さい。
*既にGithub ( https://github.com/cedro3/stylegan2 ) に上げてあり、上記のリンクでダイレクトにアクセスできます。
cedroさん
すいません、見落としてました。ありがとうございます。
はじめてコメントさせていただきます。
とてもきれいな画像を生成できていることに驚きました。
試しに手元の画像でやってみようとしたのですが、StyleGAN2がtensorflowgの1系にしか対応してないことや、
google Colabがtensorflowgの1系のサポートを終了+cudaのverが最低11なことが合わさって実行することが
できませんでした。
解決策などはありますでしょうか?
お忙しいところ恐縮ですが、お時間がありましたらご教授の程よろしくお願いいたします。
okdoroさん
Tensorflow1.x系で開発されたコードは結構あるので、古くなったとはいえcolabからcuda10が削除されると残念ですよね。
ということで、削除されたCuda10.0を新規にインストールするコードを追加しました。
再度、ブログのリンクから飛んでお試しください。
コメント失礼いたします。
すごくきれいな画像が生成できてますね!
少し気になって自前の画像で実行を試そうとしたのですが、
google Colabの現在の環境ではtensorflow1だとGPUが使えないみたいです。。。
何か解決策などはありますでしょうか?
よろしくお願いいたします。
emolabemo312さん
Colabからcuda10が削除され、tensorflow1.x系がそのまま動かせなくなりました。
ということで、Cuda10.0を新規にインストールするコードを追加しました。
再度、ブログのリンクから飛んでお試しください。