1.はじめに
今回は、2018年に発表されたBigGANにOpenAIのCLIPを組み合わせて、テキストから画像を生成するモデルをご紹介します。
2.モデルの構成
BigGANは Imagenet の巨大な画像データセットをSA-GANを大幅に増強したネットワークで学習したもので、1000カテゴリーの画像を最大512×512ピクセルの高解像度で生成するGANモデルです。2018年にDeepMindが開発しました。
CLIPは画像と画像を説明するテキストのペア4億組を学習させることによって、画像からもテキストからも、その特徴を適切に表すベクトルを取得できるモデルです。2021年にGoogleが開発しました。
GANモデルは様々な画像を生成できますが、入力パラメータにランダムノイズを使うため、モデルによってはカテゴリー程度の指定ができますがそれ以上の指定はできず、ランダムな画像しか生成できません。
今回は、このBigGANとCLIPを組み合わせることによって、テキストから画像を生成するモデルを作成します。下記にそのモデルを示します。
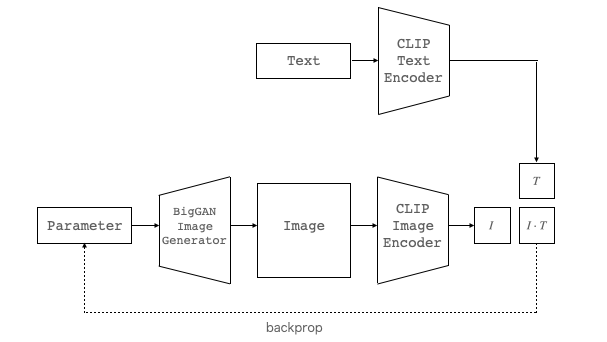
画像生成をしたい TextをCLIP Text Encoder に入力し、テキストの特徴ベクトルTを取得します。一方、Parmeter (ランダムノイズ)を BigGAN Image Generatorに入力し、出力Imageを CLIP Image Encoder に入力し、画像の特徴ベクトルIを取得します。
I と T は出来るだけ同じにしたいので、I と T の内積(COS類似度)が出来るだけ大きくなるように Parameter を最適化します。こうすることで、テキストの内容に沿った画像を生成できるようになるわけです。
それでは、コードを動かしてみましょう。
3.コード
コードはオリジナルを少しいじったものをGithubに上げてあります。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
最初に、セットアップを行います。big-sleep は pip 一発でインストールできます。
|
1 2 |
# 接続GPUのチェック ! nvidia-smi -L |
|
1 2 |
# big-sleep インストール !pip install big-sleep --upgrade |
それでは、テキストから画像を生成してみましょう。パラメータの設定内容について説明しておきます。
- SAVE_EVERY:設定したiter毎に生成した途中画像を表示します。
- SAVE_PROGRESS:Trueで生成した途中画像を保存します。
- LEARNING_RATE:学習率です。数字を増やすと創造性が増します。
- ITERATIONS:モデル内部での試行回数です。
- SEED:乱数SEEDの設定です。
LEARNING_RATEは、自分の生成したいテキストの内容によって上下させて適切な値を探ってみて下さい。探索ループの for epoch in range() の () 内の数字を増やすと解像度が若干上がりますが、時間が掛かるので上げるかどうかはお好みです。
では、TEXT = ‘an armchair in the shape of an avocado’ (アボガドの形をしたアームチェア)でやってみましょう。
|
1 |
TEXT = 'an armchair in the shape of an avocado' |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from tqdm.notebook import trange from IPython.display import Image, display from big_sleep import Imagine import random # パラメータ設定 SAVE_EVERY = 100 SAVE_PROGRESS = False LEARNING_RATE = 8e-2 ITERATIONS = 1050 SEED = random.randint(0, 10000) # モデルセッティング model = Imagine( text = TEXT, save_every = SAVE_EVERY, lr = LEARNING_RATE, iterations = ITERATIONS, save_progress = SAVE_PROGRESS, seed = SEED ) # 探索ループ for epoch in range(1): for i in trange(1000, desc = 'iteration'): model.train_step(epoch, i) if i == 0 or i % model.save_every != 0: continue filename = TEXT.replace(' ', '_') image = Image(f'./{filename}.png') display(image) |

もう1つ、TEXT = ‘Einstein and Chaplin drinking coffee at a cafe’ (アインシュタインとチャップリンがカフェでコーヒーを飲んでいる)でやってみましょう。

では、また。
(オリジナルGithub)https://github.com/lucidrains/big-sleep














コメントを残す