
今回は、先回作ったプログラムでジェスチャーデータを作成し、ジェスチャー認識をさせてみます
こんにちは cedro です。
これは、SONY Neural Network Console でジェスチャー認識【前編】の続編です。
先回は、スマホに内蔵されている加速度センサーを使ってジェスチャーデータを作成するプログラムを作成しました。
今回は、そのプログラムを使ってジェスチャーデータを作成し、Neural Network Console でジェスチャー認識をさせてみたいと思います。
ジェスチャーデータの作成
それでは、早速ジェスチャーデータの作成に入ります。

これが、今回のジェスチャーです。アルファベット26文字がそれぞれ一筆書きになっています。

この一筆書きを、スマホを持った手で空中で行って、その時のスマホの加速度センサーの値を記録して、ジェスチャーデータとします。
*写真で、もう片方に持っているスマホは自撮り用です。
使用するのは、スマホとDropbox(PCとの共有用)です。作成手順は以下の通りです。

1)スマホのブラウザで https://cedro3.github.io/gesture/ を開きます。すると、上記の様なジェスチャーレコーダが表示され、プログラムが動き出します。
2)「測定開始」ボタンを押して、ジェスチャーの記録を開始します。約0.02秒に1回加速度センサー(x,y,z) の3つの値をローカルストレージに記録します。
3)「停止」ボタンを押して、ジェスチャーの記録を終了します。
4)「データ・ダウンロード」を押すと、ローカルストレージのデータをCSVファイルで書き出しスマホ内に保存します。CSVファイルは120行で固定(超えた分は削除、不足分は0データで埋める)です。
5)2)から4)を繰り返します。
6)一区切りついたら、ファイルマネージャーで、ローカルストレージから必要なCSVファイルを選択し、Dropboxに入れます。
7)ファイルマネージャーで、ローカルストレージのファイルを削除します。
8)2)に戻ります。
プログラムは、Android、iPhoneの両方で動きますが、iPhoneだと4)の時に、毎回 Dropbox を選び、ファイル名を付けてから保存するので少々面倒です。両方持っている方は、Androidの方がおすすめです。
*なお、プログラムの詳細は、前回のブログを参照下さい。
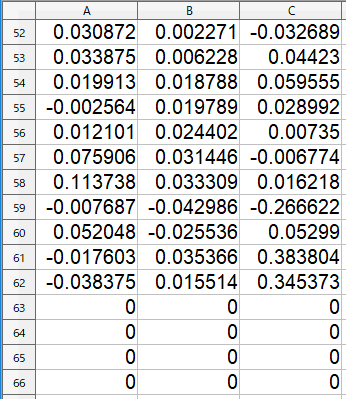
これが「A」のCSVファイルで、120行×3列です。この場合、62行目で測定が終了したので、63~120行までは「0」が埋まっています。
最初、立ってジェスチャーをやっていたのですが、どうしても膝を動かしながらのオーバーアクションになってしまいます(笑)。良い運動になりますが(笑)。
なので、立ってやるのは途中で止め、椅子に座ったままでやるジェスチャーに変更しました。こっちの方がジェスチャーがコンパクトになって、良いと思います。
アルファベット1文字づつフォルダーを計26個作り、1つのフォルダーにCSVファイルを20個づつ入れます。トータルで、26×20=520データを作成します。
1文字当たりデータが20個と手抜きですいません(笑)。
各フォルダーにCSVファイルを格納したら、学習・評価ファイルが簡単に作れるように、0.csv~19.csvにリネームしておきます。
これを学習用70%、評価用30%に振り分けて、学習ファイルと評価ファイルを作成します。
学習ファイル、評価ファイルはこんな感じになります。作成を完了したら、両方とも Neurak Network Console に登録します。
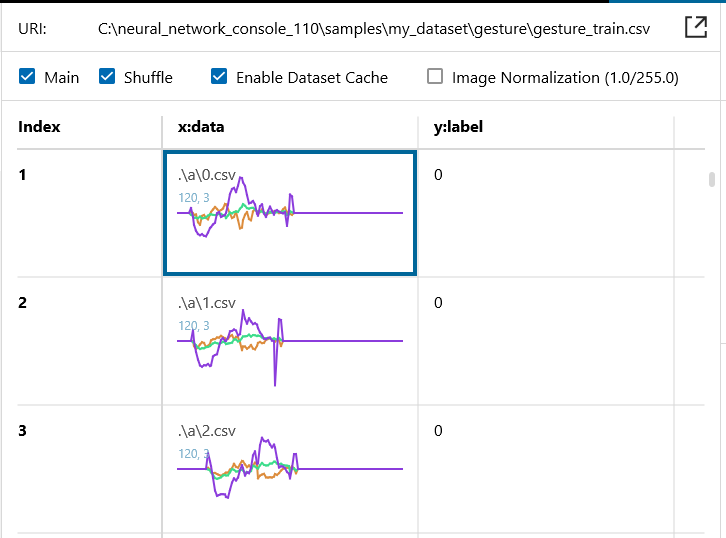
学習ファイルをNeural Network Console に読み込ませると、こんな感じ。この3つのグラフは「A」のジェスチャー波形で、x,y,z の3つの加速度センサーの値の時系列変化が読み取れます。
なお、スマホでCSVファイルを作る時にデータは正規化済みなので、Image Normalization のチェックは外しておいて下さい。
さあ、それでは、Neural Network Console で動かしてみましょう。
3つのジェスチャー認識の方法
それでは、Neural Network Console を使って、3つの方法でジェスチャー認識させてみます。
まず、原始的な多層パーセプトロン(MLP)。サンプルプロジェクトは 10_deep_mlpを流用します。
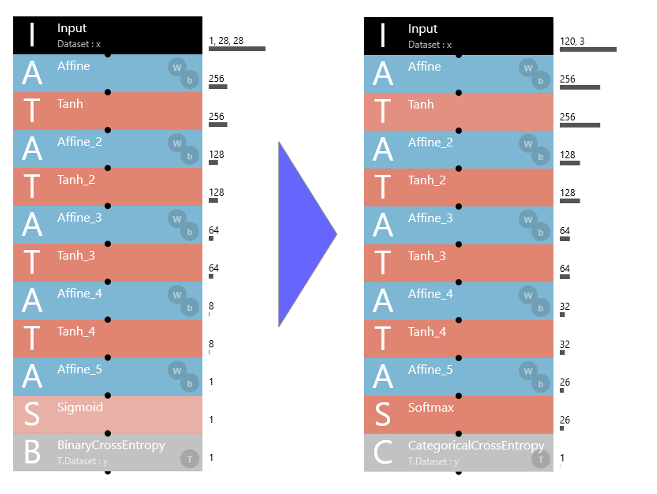
サンプルは2値分類なので、26分類に変更するために、Sigmoid を Softmax に、BinaryCrossEntropy を CategoricalCrossEntropy に変更します。
そして、Input を1,28,28 → 120,3 に、Affine_4 を8 → 32 に、Affine_5 を10 → 26 に変更します。
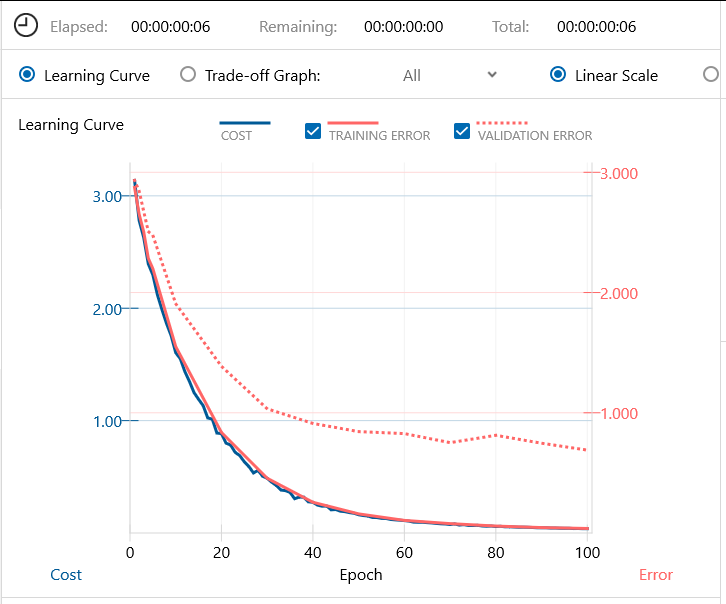
学習画面です。バッチ64、エポック100で学習を開始します。6秒で学習完了です。
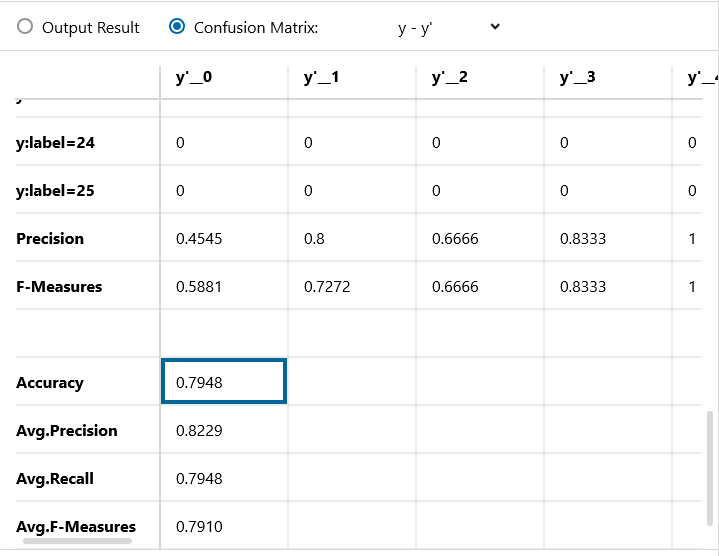
Confusion Matrix です。精度は79.48% 原始的なMLP(Multilayer perceptron)でも、8割くらいのジェスチャー認識ができました。
そして、ジェスチャーデータと言えば、時系列データ。時系列データと言えばリカレント・ネットワークです。
ということで次は、RNN(Reccurent Neural Network)でやってみます。
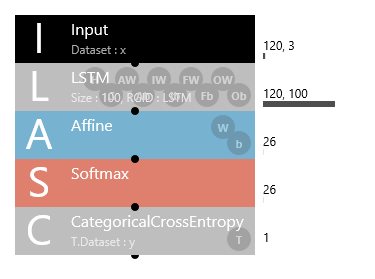
こんなシンプルなネットワークで大丈夫と思うでしょう?
しかし、2番目にある LSTMユニットは、サンプルプロジェクトにある long_short_term_memory(LSTM) の Recurrentinput から RecurrentOutput までを1つにまとめたユニットなので、こう見えて結構中身は濃いんです(笑)。
それにしても、この LSTMユニットは便利ですね。
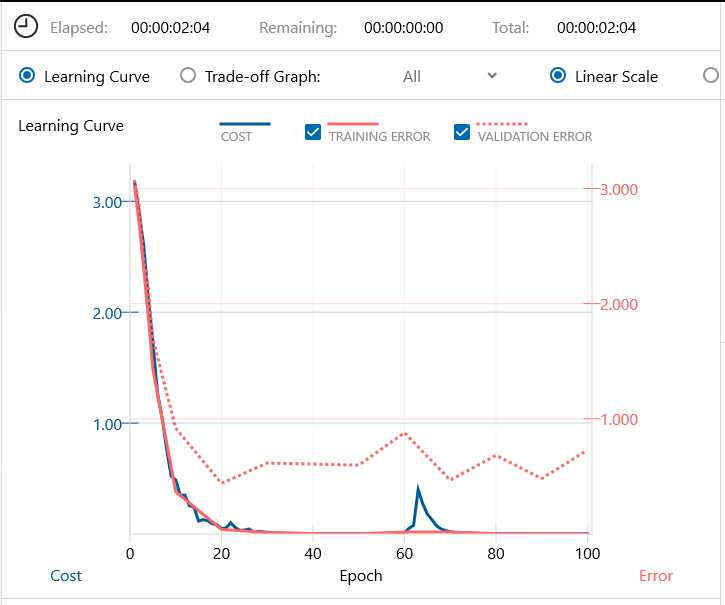
先程と同じく、バッチ64、エポック100で学習開始します。2分4秒で学習完了です。RNN系は、学習時間が結構掛かりますね。
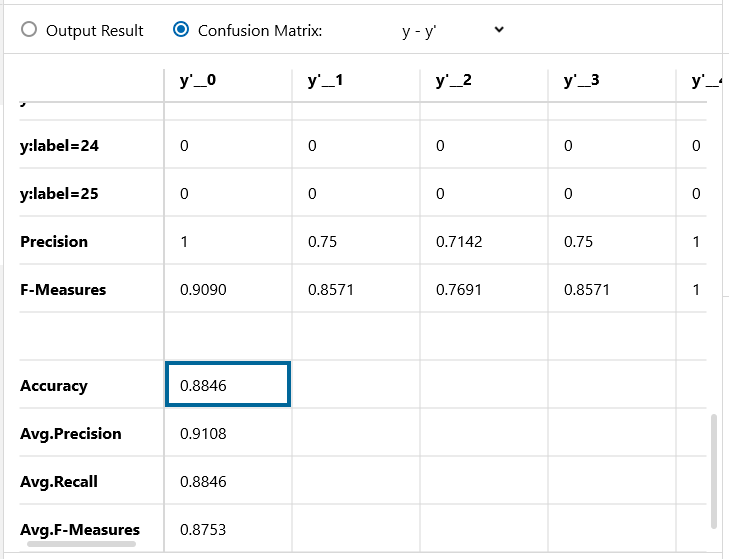
Confusion Matrix です。精度は88.46%!さすが、時系列データに強いRNNです。MLPと比べて、認識精度が約10%改善しました。
さて、Deep leraning の花形と言えば、CNN(Convolutional Neural Network)です。次は、CNNでやってみます。
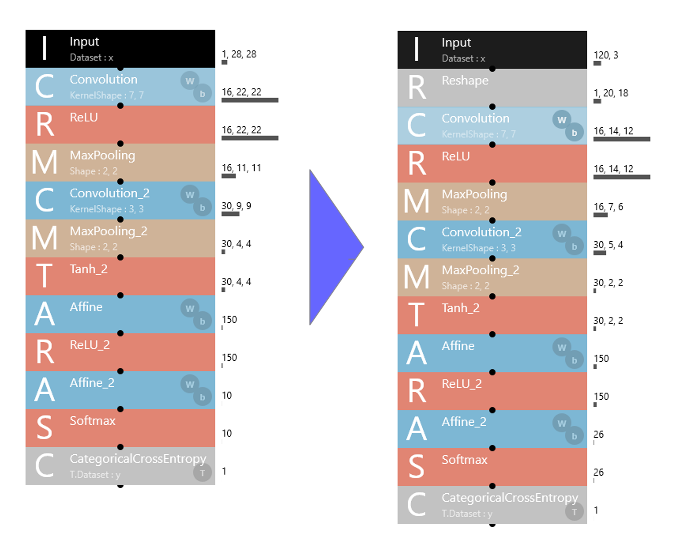
サンプルプロジェクト のLeNet を流用します。
Input が 120,3 のデータのままでは、CNNでは扱えないので、Inputの後に、Reshapeレイヤーを入れ、120,3 のデータを 1,20,18 にリシェイプ(120×3=1×20×18)します。
これによって時系列要素は消えてしまいますが、いわば 20×18 の画像になりますので、CNNで扱えます。
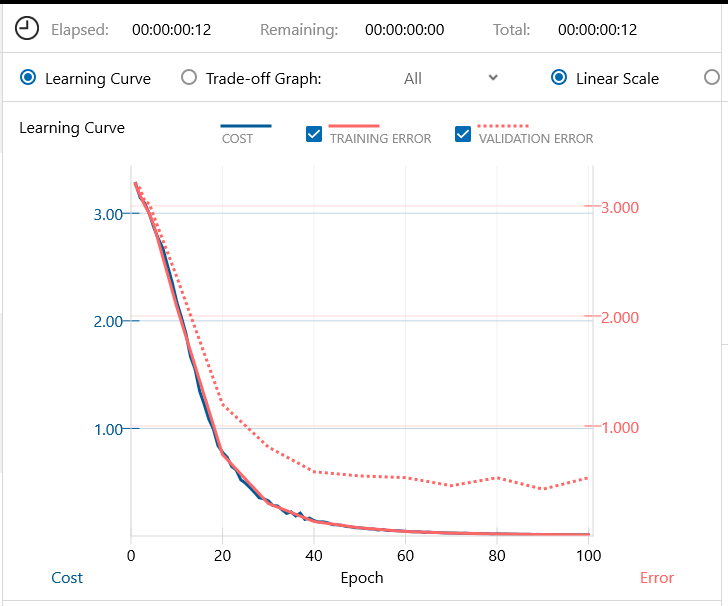
同じく、バッチ64、エポック100で学習します。学習時間は12秒。
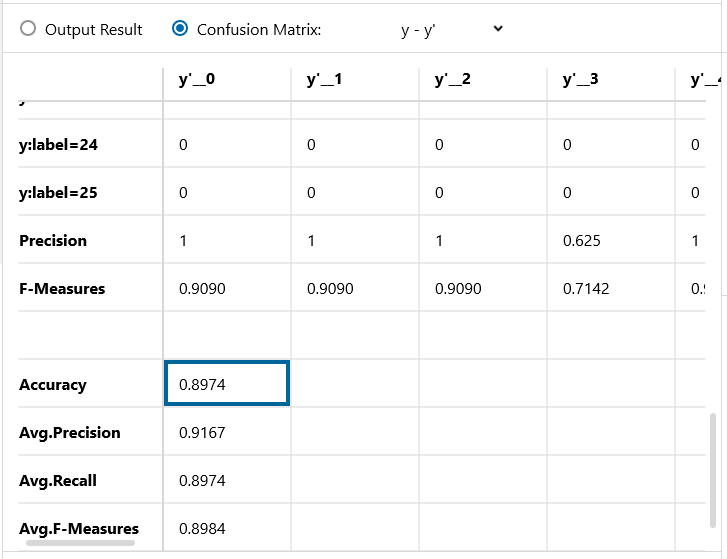
Confusion Matrix です。精度89.74%、さすがディープラーニングの花形CNN系! LSTMを+1.28 上回りました。
今回のジェスチャーデータは空間に書く文字の様なもので、画像の様な性格を持っているので、CNN系にも相性が良いようです。
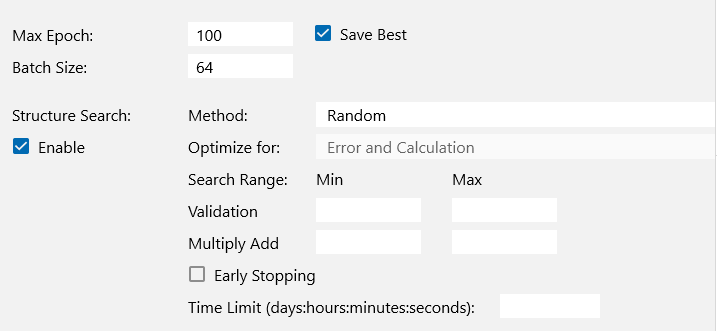
ネットワークをさらに改良すべく、構造自動探索機能を使ってみます。
Global Config で Structure Search の Enable にチェックを入れて学習開始です。
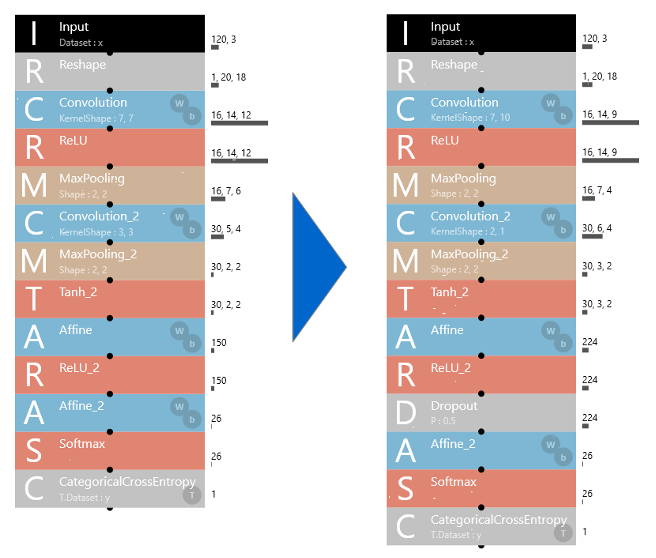
20回くらい試行錯誤した結果、これが一番良かったモデル。Dropout が追加され、若干ハイパーパラメーターも調整されています。
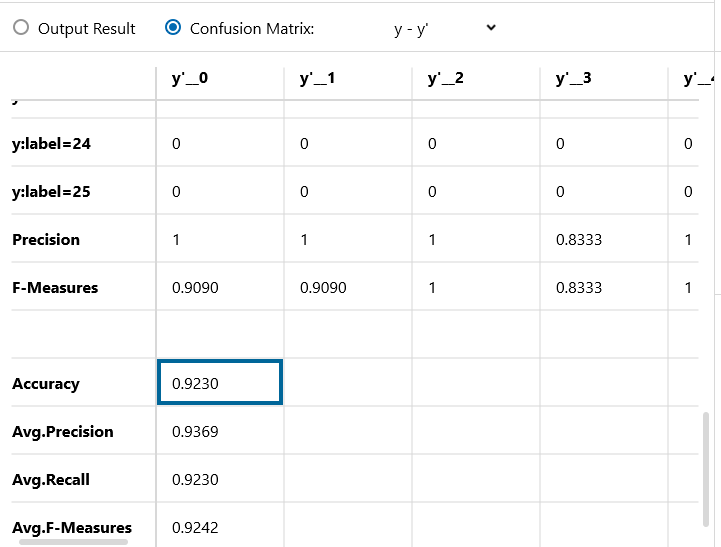
Confusion Matrix です。精度92.3%!1文字あたり20個という少ないデータながら、このあたりの精度までは簡単に行けるようです。
後は、もっと多層構造にして Batch Normalization を多用すると、もう少し精度UPできると思いますが、それはお好みと言うことで。
では、また。














コメントを残す