
今回は、話題のGPT-2学習済みモデルを使ってサクッと文章生成してみます。
こんにちは cedro です。
2/14 OpenAIは自然言語の文章を生成するモデル GPT-2 を発表しました。但し、あまりにも完成度が高いために、悪意を持った利用を恐れ、GPT-2 そのものではなく、縮小版モデルと論文のみが公開されています。
先回のブログでご紹介した様に、画像については、StyleGANという本物と見分けの付かないフェイク顔画像を生成するモデルが発表される中、今度は文章というわけですね。
ということで、今回は、話題のGPT-2学習済みモデルを使ってサクッと文章生成してみます。
GPT-2とは?
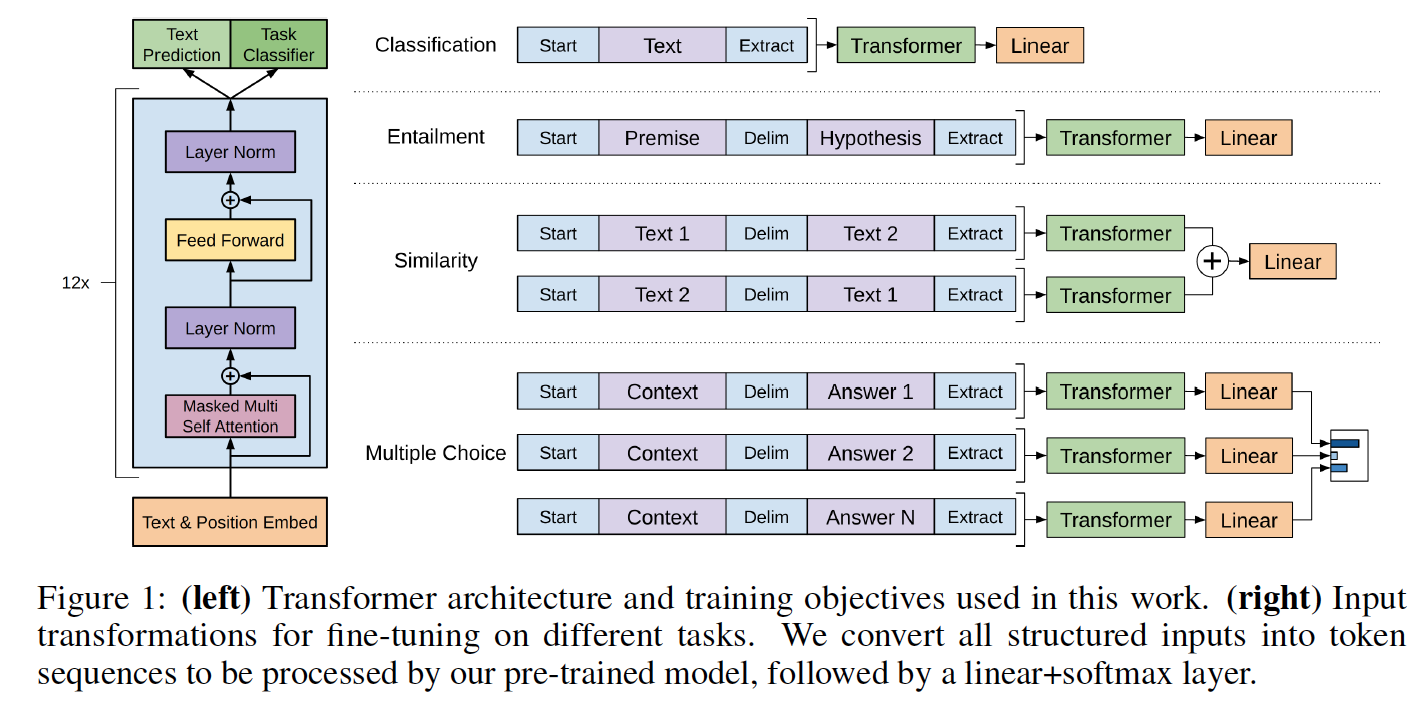
この図はGPTのアーキテクチャーを表したものです。以前、文章生成と言えば RNNモデル を使っていましたが、GPTはAttentionモデルを使っています。
私たちが言語を理解するとき、単語1つ1つを全て均等に理解しているわけではなく、ある特定の単語に注目して、その単語に関係が深い他の単語との相互関係から文を理解します。こうした方法をモデル化したのがAttentionモデルです。
GPT-2は、GPTを大幅にスケールアップしたもので、800万のWebページのデータセット(40GB)を、48層のネットワークで、15億個のパラメータを使って学習します。
あらゆるジャンルの極めて大量のデータを学習することによって、GPT−2はファインチューニング無し(Zero-shot)で、あらゆるジャンルの文章生成に対応します。
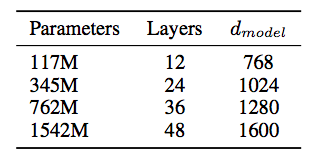
GPT-2には、この4つのモデルがあります。今回公開されているのは、一番小さな117M(パラメーターが1億個)のモデルです。
コードを動かす準備をします
今回は、Githubにある graykode/gpt-2-Pytorch のサンプルコードを使います。この後 Google Colab からGit Clone しますので、とりあえず、眺めてみるだけでOKです。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
Google Colab に接続します。ファイル/python3 の新しいノートブックを開いたら、ランタイム/ランタイムのタイプを変更でGPUを選択して保存します。そして、上記コマンドをコピペして動かします。
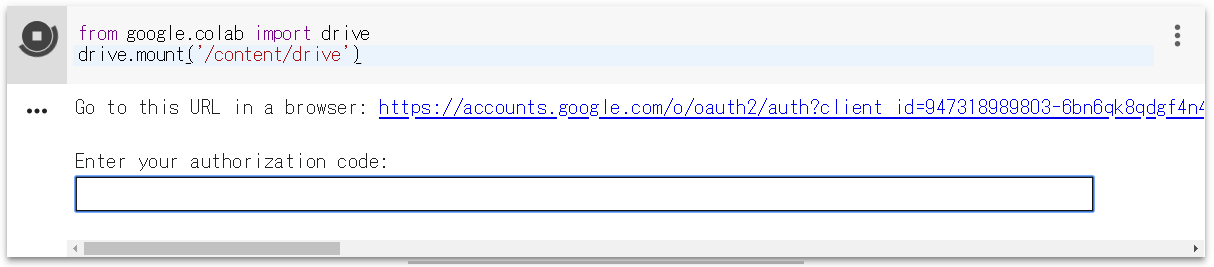
実行するとこんな表示が出ます。リンクをクリックし、アカウントを選択したら、authorization code が表示されるので、これを四角内にコピぺすれば、Googole Driveがマウントされます。
|
1 2 3 |
cd drive/My Drive !git clone https://github.com/graykode/gpt-2-Pytorch.git cd gpt-2-Pytorch |
Google Drive/My Drive にサンプルコードを git clone し、ディレクトリを gpt-2-Pytorch に移すコマンドです。 1行づつコピペして実行します。
|
1 2 |
!curl --output gpt2-pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin !pip install -r requirements.txt |
モデルをダウンロードし、必要なライブラリーをインストールするコマンドです。1行づつコピペして実行します。
コードを動かしてみます
(英文)A non-profit American AI (artificial intelligence) research company OpenAI, co-chaired by Mr. Eilon Mask, announced February 14 (local time) a language model GPT-2 that generates sentences of natural language.
(和訳)Eilon Mask氏が共同議長を務める非営利のアメリカンAI(人工知能)研究会社OpenAIは、2月14日(現地時間)、自然言語の文を生成する言語モデル GPT-2 を発表しました。
OpenAIがGPT−2モデルを発表したニュースの冒頭です。この続きをGPT-2に生成させてみましょう。
|
1 |
!python main.py --text "A non-profit American AI (artificial intelligence) research company OpenAI, co-chaired by Mr. Eilon Mask, announced February 14 (local time) a language model GPT-2 that generates sentences of natural language." |
コマンド !python main.py の引数に – – text ” 文章生成させたい文章の冒頭 ” を付けて実行します。なお、実行は数回〜10回程度トライし、出来の良いものを採用しています。
以下に、生成した英文の一部をGoogle 翻訳で和訳したものを記載します。
(生成文)このソフトウェアは、世界最大のAI研究会社であるOpenAIの「ニュージーランド」の社長でもあるDr. Eilon Maskによって書かれました。
GPT-2として知られているプロジェクトの最初の反復は、間もなくリリースされる予定のGPT-3と呼ばれるAIシステムの新しいバージョンに統合されます。同社によると、GPT-2ソフトウェアは年末までに展開される予定だという。
GPT-2ソフトウェアは、OpenAIの “ニュージーランド”研究会社の共同創設者でもあるOpenAIの最高経営責任者であるDr. Eilon Maskによって開発されました。 Eilon Mask博士は2011年に創業し、ニュージーランド政府のAIチームの一員でした。
「私たちはこの新しい言語モデルの可能性に興奮しています。それは私たちが機械学習を使うという点で自然な進化です。人工知能研究から生まれてくる全く新しいタイプの人工知能研究があります。将来の可能性の世界」とDr. Eilon Maskは述べた。<| endoftext |> PJ Fleckmanは決して写真家として生計を立てることはできませんが、少なくともお金を稼ぐ方法を探しています。
まず、まずと言ったところでしょうか。もう1つやってみましょう。
(英文)Why did the Neanderthal people be destroyed 40,000 years ago?It is difficult to find an accurate answer, but the epidemic and climate change theories have been strongly considered. However, the latest research published in the journal Science Academy Bulletin in February points out another possibility. It was said that there was no ability to compete with Homo sapiens who came to European continent about 45,000 years ago.
(和訳)なぜ4万年前にネアンデルタール人が滅ぼされたのでしょうか?正確な答えを見つけることは困難ですが、流行と気候変動の理論は強く考慮されてきました。しかし、2月にScience Sciencemy Bulletin誌に発表された最新の研究は、別の可能性を指摘しています。およそ45、000年前にヨーロッパ大陸に来たホモサピエンスと競争する能力がないと言われました。
|
1 |
!python main.py --text "Why did the Neanderthal people be destroyed 40,000 years ago?It is difficult to find an accurate answer, but the epidemic and climate change theories have been strongly considered. However, the latest research published in the journal Science Academy Bulletin in February points out another possibility. It was said that there was no ability to compete with Homo sapiens who came to European continent about 45,000 years ago." |
上記コマンドを実行します。先程と同様に生成した英文の一部をGoogle 翻訳で和訳したものを記載します。
(生成文)研究者たちはまた、ネアンデルタール人は古代の自分の骨に似た化石化された人骨の残骸を見つけることもできたことを発見しました。ネアンデルタール人はネアンデルタール人を狩りにした可能性があり、他の種が殺されたか殺された可能性があると考えられています。
「それらの多くが動物が一般的であったアメリカに住んでいて死んだことを私たちは知っています」と、ネアンデルタールの化石を研究していたペンシルバニア大学の研究者、ポールM.ドミンゲス博士は言います。 「一部のネアンデルタール人が最初のホストとしてネアンデルタール人と共に亡くなった可能性もある」
調査結果は、2月5日に開催されたワシントンDCでのアメリカ科学アカデミーの会議中に行われ、すべての主要な科学機関の代表から聞かれました。
「我々は化石記録で見つかった全ての化石を調べたが、ネアンデルタール人と人間は非常に異なる種であることを我々は知っている」とドミンゲス博士は言う。 「彼らは両方ともネアンデルタール人の獲物として狩りと狩りをされています、そして実際にはそれらの何人かは彼らと一緒に亡くなったことを知っています。
科学者たちは、現在カリフォルニア大学バークレー校の人類学の助教授であるペンシルベニア大学の研究者であるPaul M. Dominguez博士が参加しました。ドミンゲス博士は30年以上にわたりネアンデルタール人と人間の集団を研究していました、そして、彼のチームはネアンデルタール人と人間の間の遺伝的および環境の違いを調べました。
縮小版と言うことと、英文用なので、とても悪用されて困るレベルとは思いませんが、どんなジャンルでも、このレベルで文章生成ができることを考えると、やはり凄いと思います。
では、また。














日本語版のGPT2ありますよ。