
再びユーミンの歌詞生成をやってみます
こんにちは cedro です。
さて、先回は、ユーミンの歌詞をベクトル化し、Neural Network Console の LSTM を使って、歌詞の自動生成をする可能性を探ってみました。
その結果、なんとか行けそうな感触を得ましたので、今回は、本格的にやってみたいと思います。
分かち書きの不満を解消する
先回、ユーミンの歌詞を分かち書きする時に、不満な点がありました。
|
1 2 3 |
小さい 頃 は 神様 が いる て 不思議 に 夢 を かなえる て くれる た やさしい 気持 で 目覚める た 朝 は おとな に なる て も 奇蹟 は おこる よ カーテン を 開く て 静か だ 木 洩れる 陽 の やさしい さ に 包む れる た だ きっと 目 に うつる 全て の こと は メッセージ 小さい 頃 は 神様 が いる て 毎日 愛 を 届ける て くれる た 心 の 奥 に しまう 忘れる た 大切 だ 箱 ひらく とき は 今 雨上がり の 庭 で くちなし の 香り の やさしい さ に 包む れる た だ きっと 目 に うつる 全て の こと は メッセージ カーテン を 開く て 静か だ 木 洩れる 陽 の やさしい さ に 包む れる た だ きっと 目 に うつる 全て の こと は メッセージ |
「神様 が いて」 → 「神様 が いる て」となってしまうのです。これは出てくる単語を辞書に載っている基本形に変更しているためです。
この基本形への変更は、どのような単語が使われているのか分析する場合には有効ですが、今回の様な歌詞合成には不向きです。
なので、今回は、この変更は無しで行うことにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import MeCab import sys tagger = MeCab.Tagger('-Owakati -F\s%f[6] -U\s%m -E\\n') fi = open(sys.argv[1], 'r') fo = open(sys.argv[2], 'w') line = fi.readline() while line: result = tagger.parse(line) fo.write(result) line = fi.readline() fi.close() fo.close() |
分かち書きをするプログラムです。
tagger = MeCab.Tagger('-Owakati -F\s%f[6] -U\s%m -E\\n') のところの -Owakati が、基本形への変更をしないためのオプションです。wakati2.py で保存します。
|
1 2 3 |
$ python wakati2.py yuming.txt yuming_wakati2.txt |
プログラム wakati2.py を実行します。yuming.txt を分かち書きした結果が、yuming_wakati2.txt に格納されます。
|
1 2 3 |
小さい 頃 は 神様 が い て 不思議 に 夢 を かなえ て くれ た やさしい 気持 で 目覚め た 朝 は おとな に なって も 奇跡 は おこる よ カーテン を 開い て 静か な 木洩れ陽 の やさし さ に 包ま れ た なら きっと 目 に うつる 全て の こと は メッセージ 小さい 頃 は 神様 が い て 毎日 愛 を 届け て くれ た 心 の 奥 に しまい 忘れ た 大切 な 箱 ひらく とき は 今 雨上がり の 庭 で くちなし の 香り の やさし さ に 包ま れ た なら きっと 目 に うつる 全て の こと は メッセージ カーテン を 開い て 静か な 木洩れ陽 の やさし さ に 包ま れ た なら きっと 目 に うつる 全て の こと は メッセージ |
今度は単語の変質は無くなりました。
後は微調整ですが、実は拘り始めると結構手間がかかります。
今回、日本語の繋がりだけに焦点を絞りたかったので、日本語だけで意味が通るところは、英語の部分は全て削除しました。
但し、September blue moon の様に、「君はSeptember blue moo」みたいに日本語の中に英語が組み込まれている場合は、仕方なく September_blue_moo と特別な単語にしておきました。
あと、Mecab は結構細かく単語を分割するので、好みに応じて、全体を見ながら単語を結合して調整します。
例えば、「あの ひと」→「あの人」とか。この時、エディターの置換を使って、データ全体の「あの ひと」を「あの人」に変換することに注意です。
これ、やり出すときりがないので、適当なところで切り上げます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from gensim.models import word2vec import logging import sys logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.LineSentence(sys.argv[1]) model = word2vec.Word2Vec(sentences, sg=1, size=100, min_count=1, window=10, hs=1, negative=0) model.save(sys.argv[2]) |
ユーミンモデルを作成するプログラムです。これは前回と全く同じです。train.py で保存します。
|
1 2 3 |
$ python train.py yuming_wakati2.txt yuming2.model |
プログラム train.py を実行します。yuming_wakati2.txt を使って yuming2.model (ユーミンモデル)が作成されます。
ユーミンモデルで遊んでみる
単語をベクトル化すると、Neural Network Console で読めるようになる以外に、嬉しいことがあります。
それは、単語の足し算、引き算ができるようになることです。
有名な例としては、英語の文章を大量に学習させたモデルで、King ー man + woman =を計算させると計算結果は Queen になるという話があります。
せっかくですので、yuming2.model (ユーミンモデル)でも似た様なことを試して見ましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from gensim.models import word2vec import logging import sys model = word2vec.Word2Vec.load("yuming2.model") def neighbor_word(posi, nega=[], n=10): count = 1 result = model.most_similar(positive = posi, negative = nega, topn = n) for r in result: print(str(count)+" "+str(r[0])+" "+str(r[1])) count += 1 def calc(equation): if "+" not in equation or "-" not in equation: neighbor_word([equation]) else: posi,nega = [],[] positives = equation.split("+") for positive in positives: negatives = positive.split("-") posi.append(negatives[0]) nega = nega + negatives[1:] neighbor_word(posi = posi, nega = nega) if __name__=="__main__": equation = sys.argv[1] calc(equation) |
単語の加減算を実行するプログラムです。result.py で保存します。
|
1 2 3 |
$ python result.py ママ-女+男 |
プログラム result.py を実行して ママ ー 女 + 男 = を計算させて見ましょう。答えは、直ぐ想像できますよね。
|
1 2 3 4 5 6 7 8 9 10 11 |
1 パパ 0.7120641469955444 2 モンスーン 0.6944067478179932 3 ひとすじ 0.6834356784820557 4 着いた 0.677168071269989 5 いかり 0.6693496108055115 6 閉ざさ 0.6582196950912476 7 潜る 0.6546837091445923 8 おち 0.6499546766281128 9 灼き 0.6460970640182495 10 かの 0.6431527137756348そう |
そうです、答えは パパ です。ちゃんと思った通りの答えを返してくれます。さすが、word2vec !
|
1 2 3 |
$ python result.py 横須賀ガール-女+男 |
今度はマニアックな例です(笑)。
横須賀ガール ー 女 + 男 = を計算させて見ましょう。ユーミンファンなら狙いの答えはピンと来ますよね。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
1 湘南ボーイ 0.82449871301651 2 抱く 0.795835018157959 3 深まり 0.7778992652893066 4 キャサリンキャサリン 0.7778483629226685 5 エア 0.7724181413650513 6 バター 0.7610534429550171 7 遊ん 0.7610064744949341 8 棧橋 0.759613037109375 9 コバルト 0.7588188052177429 10 ポケット 0.757361888885498 |
おおっ!ちゃんと 湘南ボーイ になりました。結構やります、word2vec !
ピンと来ない方は、荒井由実時代の名作、「コバルトアワー」を聞いてみて下さい。
さて、寄り道はこのくらいにして、本題に戻ります。
Neural Network Console のデータセットを作成します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
小さい 頃 は 神様 が い て 不思議 に 夢 を かなえ て くれ た やさしい 気持 で 目覚め た 朝 は おとな に なって も 奇跡 は おこる よ |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from gensim.models import word2vec import sys import csv model =word2vec.Word2Vec.load(sys.argv[1]) #read_fpをkashi_w.csvの読み込みポインタとして定義 read_fp=csv.reader(open("kashi_w.csv","r")) #write_fpをkashi_v.csvの書き込みポインタとして定義 write_fp=csv.writer(open("kashi_v.csv","w")) #read_fpでkashi_w.csvを一行づつ読み込み、wordに代入 for word in read_fp: #読み込んだ一行分をベクトル変換する vector=model.wv[word] print(vector) write_fp.writerow(vector) |
kashi_w.csv を1行づつ読み込んで ベクトル化し、kashi_v.csv に1行づつ書き込むプログラムです。encoder2.py で保存します。
|
1 2 3 |
$ python encoder2.py yuming2.model |
プログラム encoder2.py を実行します。ベクトル化した結果は、 kashi_v.csv に格納されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
"[ -1.67809252e-03 -1.87622048e-02 6.16140813e-02 -8.95797908e-02 -7.05911545e-03 -1.13190208e-02 1.58460662e-02 1.90176466e-03 4.39779311e-02 -2.12275237e-02 -1.90185979e-02 -5.07493243e-02 4.62005623e-02 -3.15178223e-02 -6.18393160e-03 -4.85802488e-03 -5.59474751e-02 -2.57438496e-02 3.55417877e-02 1.49122137e-03 1.65411551e-02 -2.11213604e-02 -5.15742265e-02 6.65480096e-04 2.67654713e-02 -2.27035638e-02 4.02323231e-02 3.35588935e-03 1.55695556e-02 -3.24346982e-02 3.01350281e-02 -1.65207088e-02 -3.46862944e-03 2.47173309e-02 2.34318944e-03 -5.91201615e-03 -1.80564392e-02 4.61876132e-02 7.00957850e-02 -2.17377488e-02 4.00575288e-02 -2.41122060e-02 -2.23058220e-02 3.49211134e-02 -1.42715909e-02 -9.05714259e-02 4.03053202e-02 -4.38390225e-02 1.13180265e-01 8.77974555e-03 8.36821795e-02 8.91029369e-03 -2.36755628e-02 -2.31690379e-03 -3.85019486e-03 7.84323085e-03 -3.61867845e-02 -6.67651966e-02 -3.58519927e-02 2.87621059e-02 -7.34595284e-02 -6.72459677e-02 2.38628201e-02 2.96746963e-03 -1.40744122e-02 -5.18408753e-02 -3.62221859e-02 -7.65656307e-02 9.05939005e-03 6.52993843e-02 5.27909771e-02 2.50075180e-02 -1.57684926e-03 -6.61179274e-02 -2.35982835e-02 1.98932718e-02 3.65009159e-02 8.30641016e-02 6.63818866e-02 7.21460059e-02 -8.13494436e-03 3.56596918e-03 -8.67917552e-04 -2.35941075e-02 8.10666196e-03 -2.90218126e-02 1.57858226e-02 1.15938917e-01 2.03734823e-02 2.64834072e-02 -1.66283008e-02 -2.35876832e-02 3.90793104e-03 -3.03655397e-05 1.98115278e-02 2.80100293e-02 4.64717299e-03 3.23721673e-03 -2.87951268e-02 1.82534102e-02]" |
kashi_v.csv の中身はこんな感じ。表示されているのは、冒頭の「小さい」をベクトル化した結果です。
“[ ]” で囲まれ空白で区切られていますので、エディターを使って 、“[ ]” を削除し空白をカンマに置き換え、calcで1行100列のデータとして読めるようにします。
今回は、kashi_v.csv の先頭から1200行分を使います。
1200行分のデータを100行づつ、12個のファイルに分け、0.csv 〜 11.csv のファイル名を付けて、songフォルダーに格納します。
これが学習ファイルです。ファイル名は、ym_train.csv とします。
これが評価ファイルです。ファイル名は、ym_test.csv とします。
C:直下にSNNC96フォルダーを作り、songフォルダーとym_train.csv とym_test.csv を格納します。
そして、DATASET画面で、ym_train.csv とym_test.csv を登録しておきます。
ニューラルネットワークの設定をします
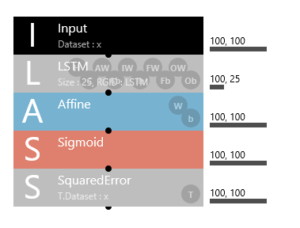
EDIT画面です。基本的に先回と同様です。
入出力とも、100行×100列の行列の形になりますので、100,100です。
学習ファイルを設定します。
評価ファイルを設定します。
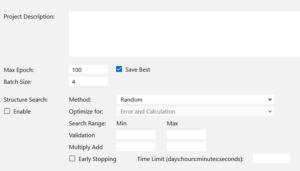
CONFIG設定です。Batch Size4、Max Epoch 100 と設定し、学習を開始します。
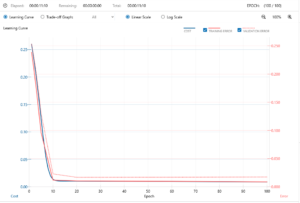
学習曲線はいい感じです。過学習もないようです。所要時間11分10秒です。
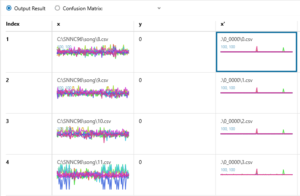
さて、評価データ x に対する予測データ x’ ですが、一目みた感じ、あまり良い結果ではないようですね(笑)。
予測データは平坦で、4つともほとんど同じ形をしている様にみえます。
0.csv 〜 3.csv で出力されますので、連結して、lstm.csv というファイル名で保存します。
歌詞生成の結果をみて見ます。
先回は、LSTMから出力されたベクトルを1つ1つ単語に変換していましたが、さすがにここは改善しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from gensim.models import word2vec import sys import csv import numpy as np model =word2vec.Word2Vec.load(sys.argv[1]) #read_fpをkashiw.csvの読み込みポインタとして定義 read_fp=csv.reader(open("lstm.csv","r")) #write_fpをkashiv.csvの書き込みポインタとして定義 write_fp=csv.writer(open("lstm_word.csv","w")) #read_fpでumi_lstm.csvを一行づつ読み込み、vectorに代入 for line in read_fp: vector=list(map(float,line)) vector=np.array(vector) #読み込んだベクトルを単語に変換する word = model.most_similar([ vector ], [], 1) print(word) write_fp.writerow(word) |
ベクトルを単語に変換するプログラムです。lstm.csv から1行づつベクトルを読み込み、lstm_word.csv に単語を書き込みます。decoder.py で保存します。
※先回上手く動かなかったのは、csvファイルから読み込んだ結果が文字列になっていることが原因でした。なので、vector=list(map(float,line)) を追加して、数値に変更しています。
|
1 2 3 |
$ python decoder.py yuming2.model |
プログラム decoder.py を実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[('胸', 0.2176605761051178)] [('会う', 0.2603440582752228)] [('何', 0.24941712617874146)] [('胸', 0.2367272973060608)] [('胸', 0.24398981034755707)] [('頃', 0.34681183099746704)] [('写真', 0.19536805152893066)] [('胸', 0.26834836602211)] [('きれい', 0.2641291618347168)] [('胸', 0.1961415410041809)] [('胸', 0.2388383448123932)] [('胸', 0.21361418068408966)] [('きこえる', 0.2260562777519226)] [('きこえる', 0.2274065911769867)] [('胸', 0.24116317927837372)] [('胸', 0.23375794291496277)] [('胸', 0.2555994987487793)] [('胸', 0.20011156797409058)] [('日', 0.29089802503585815)] [('始まっ', 0.2393302321434021)] |
これはダメですね。「胸」ばっかり言ってます(笑)。
ユーミンの表現豊かな言葉のベクトルの変化に、全く追従できていない感じです。
ならば、評価ファイルには、一生懸命勉強した学習ファイルをそのまま使えば、少しは追従性が上がるかもと思ってやってみることにしました。
方法は簡単です。DATASETボタンで、評価ファイルを学習ファイルに入れ替えて、評価ボタンを押すだけです。

その結果がこれ。少しマシになったようです(笑)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[('親切', 0.3328491747379303)] [('大好き', 0.227425217628479)] [('会い', 0.23719793558120728)] [('あの', 0.23301762342453003)] [('日', 0.19947350025177002)] [('たく', 0.27691370248794556)] [('写真', 0.23192450404167175)] [('キャサリン', 0.36049002408981323)] [('きこえる', 0.3213793635368347)] [('見つめ', 0.23744401335716248)] [('言え', 0.4049336910247803)] [('ボード', 0.3140939772129059)] [('すぐ', 0.2134196162223816)] [('蹴っ', 0.24926038086414337)] [('日', 0.2656269669532776)] [('胸', 0.20997752249240875)] [('日', 0.26540276408195496)] [('見つめ', 0.2752991318702698)] [('潮', 0.21422746777534485)] [('やめ', 0.27008119225502014)] |
うーん。さっきよりはマシになりましたが、まだまだですね。
|
1 2 3 4 5 6 7 8 9 |
ハリケーン 人待ち顔 込め 待ち焦がれ 頃 きこえる たちむかえ 探し いつ もう一度 胸 金色 リグレット はるか たくさん 実力 から 帰ら しまい 変わら 親切 姿 ほろ苦く 親切 きこえる いつか たてる頃 できる |
とりあえず、単語を4つづつを組して、まあまあの所を抜き出したのが、これです。
まだ、歌詞生成には、ほど遠い感じですね(笑)。
LSTMでユーミンの歌詞生成モデルに取り組んだ感想は、LSTMは表現力豊かなユーミンの歌詞にとても追従できないということです。
言い換えれば、あの常に時代を先取りして、新らしい何か創造しているユーミンが、何か規則性のある歌詞を作るなんてことはないわけですよね。
そして、何か規則性がないとLSTMは上手く動かないようです。
では、また。














コメントを残す