
Pythonの世界に飛び込むことにしました
お久しぶりです、cedro です。
先回、リカレントニューラルネットワークを使って、過去の乗客数の流れから、その後の乗客数がどうなるかの予測をやりました。
そうすると今度は、過去の文章の流れから、その後の文章がどうなるかの予測をしてみたくなって来る。
しかし、Neural Network Consoleは、行列やベクトル、画像データは読めますが、単語は読めません。
まあ、1文字づつ数字に変換すれば読み込めないことはないですが、これでは後の処理が上手くできません。
そこで word2vec の登場となります。word2vec は、ある単語の周辺にどの様な単語が現れやすいかというルールに基づいて、単語をベクトル化してくれるものです。
しかし、これ Python を使わないと無理なんですよねー。
ただ、今まで、SONY Neural Network Console のマニュアルとWeb情報を元に、ここまでやって来ました。
Pythonについても、自分がやりたいことだけWebで調べて、写経すればいいんじゃない。と考えて、Pythonの世界に飛び込むことにしました。
ユーミンの歌詞生成をやってみる
いつもの様に「とりあえず一通りやって見る」の方針に従って、今回は松任谷由実の歌詞生成をやってみます。そのシナリオは、
1)Pythonの環境を作り、必要なライブラリーを整備する。
2)松任谷由実の歌詞データを収集し、gensim ( word2vec のライブラリーの1つ)で ユーミンモデルを作る。
3)松任谷由実のどれか1曲の歌詞を、ユーミンモデルを使ってベクトルデータに変換し、Neural Network Console が読める様にする。
4)Neural Network Console のLSTMで1曲の歌詞の前半3分の2を学習させ、後半3分の1を予測させる。
5)LSTMの予測したベクトルデータを単語に変換し、ユーミンの歌詞を生成する。
データはたった1曲という前代未聞の少なさ。一体、LSTMの学習は収束するんでしょうか。
まあ、なんとかなるでしょう。
1)Pythonの環境を作り、必要なライブラリーを整備する
これは、Webを見れば、山ほど情報があるので、割愛します。
私のマシン環境と導入したライブラリーだけ書いておきます。
マシン:MacBook Air 2017年モデル 256GB(bootcampで64GB分にWindows10を入れてます)
OS : Mac OS Sierra 10.12.6
ライブラリー:anacond5.0.1 (普通のアプリケーションと同様にインストールでき、後々欲しくないそうなライブラリーを一括で導入でき、一押しです)、gensim(word2Vecのライブラリー)、Mecab(分かち書きをする時に必要なライブラリー)、ipadic(Mecabで使う辞書です)。
2)松任谷由実の歌詞データを収集し、gensim で ユーミンモデルを作る。
歌詞データは、Uta-Net でダウンロードしたい曲を表示させ、HTMLのソース画面にすると170行目に歌詞がありますので、これをひたすらコピペします。
早くPythonでスクレイピングも出来る様にせねば(;汗)
全403曲を1つのtxtファイルにまとめます。
gesim は単語がスペースで区切られていないと読み込めないので、分かち書きをします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import MeCab import sys tagger = MeCab.Tagger('-F\s%f[6] -U\s%m -E\\n') fi = open(sys.argv[1], 'r') fo = open(sys.argv[2], 'w') line = fi.readline() while line: result = tagger.parse(line) fo.write(result[1:]) # skip first \s line = fi.readline() fi.close() fo.close() |
Mecab ライブラリーを使って、分かち書きするプログラムです。 wakati.py として保存します。
|
1 2 3 |
$ python wakati.py yuming.txt yuming_wakati.txt |
プログラム wakati.pyを実行します。分かち書きする対象は yuming.txt で、分かち書き後のデータは yuming_wakati.txt に保存します。
|
1 2 3 |
小さい 頃 は 神様 が いる て 不思議 に 夢 を かなえる て くれる た やさしい 気持 で 目覚める た 朝 は おとな に なる て も 奇蹟 は おこる よ カーテン を 開く て 静か だ 木 洩れる 陽 の やさしい さ に 包む れる た だ きっと 目 に うつる 全て の こと は メッセージ 小さい 頃 は 神様 が いる て 毎日 愛 を 届ける て くれる た 心 の 奥 に しまう 忘れる た 大切 だ 箱 ひらく とき は 今 雨上がり の 庭 で くちなし の 香り の やさしい さ に 包む れる た だ きっと 目 に うつる 全て の こと は メッセージ カーテン を 開く て 静か だ 木 洩れる 陽 の やさしい さ に 包む れる た だ |
分かち書き後のデータ yuming_wakati.txt の中身を見ると、こんな感じ。
「神様が いて」というところが「神様が いる て」となっていて、気にいらないのですが、一般化するとこうなるのかな。まあ、今回は良しとしましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from gensim.models import word2vec import logging import sys logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.LineSentence(sys.argv[1]) model = word2vec.Word2Vec(sentences, sg=1, size=100, min_count=1, window=10, hs=1, negative=0) model.save(sys.argv[2]) |
これが、gensim ライブラリーを使ってユーミンモデルを生成するプログラムです。ベクトル化の次元数は100、ウインドウは10(前後どこまでの単語を考慮するか)。train.py として保存します。
|
1 2 3 |
$ python train.py yuming_wakati.txt yuming.model |
プログラム train.pyを実行します。yuming_wakati.txt を元にして、yuming.model というモデルが生成されます。
yuming.model の中には、yuming_wakati.txt の中に出てくる単語すべてについて辞書が出来ます。そして、それぞれの単語について、ある単語の周辺にどの様な単語が現れやすいかというルールに基づいて、ベクトルが設定されます。
ある単語の周辺に現れやすい単語は類似したベクトルが設定され、その逆は異なるベクトルが設定されることになります。
|
1 2 3 4 5 6 7 8 9 10 |
from gensim.models import word2vec import sys model = word2vec.Word2Vec.load(sys.argv[1]) results = model.most_similar(positive=sys.argv[2], topn=10) for result in results: print(result[0], '\t', result[1]) |
さて、yuming.model が上手く出来たのか、チェックして見ましょう。これは、指定した単語と類似度の高い単語の上位10個を出力するプログラムです。similars.py で保存します。
|
1 2 3 |
$ python similars.py yuming.model 空 |
プログラム similars.py を実行し、yuming.model に「空」と類似度が高い単語を出力させてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
海 0.6967459321022034 雲 0.6710447669029236 ひこうき雲 0.6545253396034241 憧れる 0.6416103839874268 ながら 0.6165146231651306 さざ波 0.6080841422080994 飛行船 0.6024987697601318 さすらう 0.6002518534660339 帯 0.6000399589538574 時折 0.5948989391326904 |
「空」と最も類似度が高い単語は「海」で、その確率は69.7%だと表示されました。
3位の「ひこうき雲」、4位の「憧れる」を見ると、ユーミンのことを学習していることが良く分かります。
3)「海を見ていた午後」をベクトル化し、Neural Network Console で読める様にする。
さて、いよいよ歌詞のベクトルデータ化です。曲は、荒井由実時代の名作「海を見ていた午後」を選びました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
あなた を 思い出す この 店 に 来る たび 坂 を 上る きょう も ひとり 来る |
歌詞は1行1単語です。注意すべきは、yuming.modelの辞書に登録されている単語の区分で書くことです。
こうしないとベクトル化の時にエラーになってしまいます。分かち書きの関係で不自然な表現になっている部分は、適当に端折ります。
全部で96行(96単語)になりました。これを umi_kashiw.csv で保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from gensim.models import word2vec import sys import csv model =word2vec.Word2Vec.load(sys.argv[1]) #read_fpをkashiw.csvの読み込みポインタとして定義 read_fp=csv.reader(open("umi_kashiw.csv","r")) #write_fpをkashiv.csvの書き込みポインタとして定義 write_fp=csv.writer(open("umi_kashiv.csv","w")) #read_fpでkashi.csvを一行づつ読み込み、wordに代入 for word in read_fp: #読み込んだ一行分をベクトル変換する vector=model.wv[word] print(vector) write_fp.writerow(vector) |
umi_kashiw.csv から1行づつ単語を読み込んで、ベクトルに変換し、umi_kashiv.csv に1行づつベクトルを書き込むプログラムです。
vector = model.wv [word] のところがベクトル化している部分です。
encoder.py で保存します。
|
1 2 3 |
$ python encoder.py yuming.model |
プログラム encoder.py を yuming.model に対して実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
"[ 0.24569447 0.10015934 0.14830695 -0.09988572 0.03357235 0.11014041 -0.09736857 0.17450279 0.10550223 0.03985448 -0.05472968 0.17555073 0.15995912 -0.03846265 -0.0812135 0.08689704 -0.04919512 -0.0819933 -0.05673641 0.08172562 -0.14574412 0.07016838 -0.04837095 0.02692911 -0.01762966 0.04707582 0.06396389 0.06240657 0.03552805 -0.03334635 -0.12581441 -0.00550269 0.08473228 -0.00464743 0.09298534 -0.02566907 0.04234424 0.02226008 -0.03001935 -0.04619627 -0.06058308 0.01098899 -0.04659308 0.04242648 0.03605084 0.01084165 0.01328851 0.03269158 0.03076275 -0.13780005 -0.06827185 0.0625147 -0.04398905 0.08498013 -0.04156261 -0.00517326 -0.14843093 -0.04908359 -0.04259613 -0.01205945 -0.06146661 -0.07309576 0.13554449 -0.05070776 0.0795327 -0.06841516 0.00677772 -0.04836838 0.04552431 -0.02241047 0.09482959 -0.02986176 0.06642585 0.10129689 -0.01592086 -0.06089449 0.10336863 0.05967915 0.1864928 -0.0812957 0.099826 0.0050892 0.11592036 0.03532625 0.04836664 0.08552562 0.17079961 0.03184278 0.12672403 0.12580508 -0.05063909 0.10270367 0.06047614 -0.04393408 -0.00933132 0.04361366 -0.0318491 -0.01141877 -0.02142348 0.11414637]" |
ベクトルデータを書き込んだ umi_kashiv.csv の中身を見て見ましょう。
これが、海を見ていた午後」の歌詞の冒頭にある「あなた」をベクトル化した結果です。100次元ですので、この表示の全部で、「あなた」です。
umi_kashiv.csv はベクトルの先頭に [ が付き、ベクトルの最後に ] が付き、空白の区切り(タブ区切り)になっていますので、エディターを使って、[ と ] を削除し、空白を , (カンマ)に変更します。
さて、Neural Network Consoleのデータセットをどう作るかですが、100次元のベクトルが96行あるというのは、言い換えれば96行×100列の行列データがあることになります。
これを8行×100列の行列に分割します。そうすると、全部で12個の行列になります。
この12個のファイルに 0.csv~11.csv の名前を付けて、kashi フォルダーに格納します。
前半の8個を学習用、後半の4個を評価用に使うことにします。
学習用ファイルは、前回と同様です。名前は、yuming_train.csv としました。
評価用ファイルも前回と同様です。名前は、yuming_test.csv としました。
C:直下にSNNC90フォルダーを作り、そこへ yuming_train.csv とyuming_test.csvとkashiフォルダーを格納すれば準備完了です。
SONY Neural Network Console を起動して、DATASET画面で、yuming_train.csv とyuming_test.csv を登録しておいて下さい。
4)LSTMで学習・予測させる。
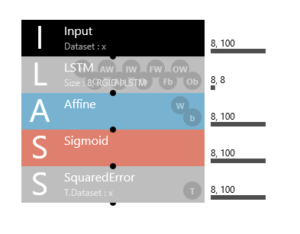
ニューラルネットワークは、先回の航空会社の乗客数予測に使ったものと同じく、LSTM unit を使用したものです。入・出力は8行×100列の行列ですので、8,100 とします。
学習ファイルをセットします。
評価ファイルをセットします。
評価ファイルのデータが4個しかないので、Batch Size は4、Max Epoch 500 で学習を実行します。

ちゃんと収束してくれて、過学習もないようです。
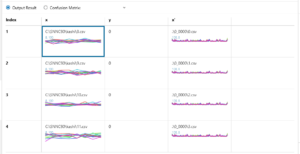
さて、評価(予測)結果です。評価データxに対してx’を予測しています。
なんか評価データはダイナミックレンジが広いのですが、予測データはダイナミックレンジが狭く、結構似ているような気がします。
さて、目的の予測データが何処にあるかと言うと

SNNC90フォルダーの中の yuming_LSTM_unit.files をクリックして

自分のみたい時刻のフォルダーをクリックして

その中の0_0000 フォルダーをクリックすると

この0~3のcsvファイルに予測したベクトルデータが入っています。
5)LSTMの予測したベクトルデータを単語に変換し、ユーミンの歌詞を生成する。
|
1 2 3 4 5 6 7 8 9 10 11 |
from gensim.models import word2vec import sys import numpy as np model =word2vec.Word2Vec.load(sys.argv[1]) vector=np.array([0.00240471,0.0166879,0.0148382,0.00312725,0.0172508,0.0056161,0.0399991,0.0445094,0.0436496,0.026358,0.00285321,0.00247504,0.00631191,0.00529516,0.0123092,0.00308995,0.00196763,0.00390349,0.0727821,0.00776131,0.0307252,0.00730357,0.00233183,0.00563598,0.047232,0.0261959,0.0545721,0.00970462,0.0311056,0.0267448,0.0382968,0.07048,0.0111126,0.0269569,0.0667372,0.00840174,0.00186305,0.00219088,0.00185668,0.00366478,0.00150611,0.00161428,0.00224958,0.00207849,0.0467214,0.0377505,0.00528867,0.0737298,0.077071,0.0212755,0.0211066,0.0363171,0.00203562,0.00269529,0.00320862,0.00945672,0.00214845,0.00205447,0.007627,0.00205762,0.00537142,0.00585467,0.00204224,0.00248403,0.00193583,0.0072777,0.00203482,0.00251333,0.00146531,0.00481778,0.00185159,0.00150527,0.00190546,0.00235801,0.00279818,0.00185423,0.00708957,0.00629635,0.0355195,0.0573038,0.0141058,0.00387628,0.0228214,0.00704818,0.0028156,0.0160483,0.00518427,0.00912945,0.0783181,0.050099,0.0145389,0.0401541,0.105838,0.187588,0.249267,0.115767,0.07744,0.111035,0.122859,0.142494]) word = model.most_similar( [ vector ], [], 1) print(word) |
csvファイルからベクトルを1つづつ読み込んで、単語に変換し、ファイルに書き出そうとしたのですが、どうしても上手く行きません。
なので、とりあえず、力技で赤字の部分にベクトルを1つづつコピペして動かす仕様にしました。
word = model.most_similar ( [ vector ], [ ] ,1 )という部分でベクトルに最も類似する単語を抜きだしています。
これを power.py で保存します。
|
1 2 3 |
$ python power.py yuming.model |
プログラム power.py を実行します。
|
1 2 3 |
[('覚える', 0.3083460330963135)] |
出力がこれ。単語の後の数字は、類似度の確率です。
power.py のベクトルのところをコピペしては、プログラム power.py 実行するというのを32回繰り返します。
|
1 2 3 4 5 6 |
海 分ぬ なれる 覚える 罪 やさしい見守るー 分 ふたつ なれる 意外 罪 つらい見守るー 分ぬ なれる 意外 罪 つらいどれー 分ぬ なれる 覚える 罪 やさしい見守る |
さて、32個の出力をまとめたものがこれです。
1曲分の歌詞だけでLSTMをやった割には、様式的にも揃っていて、何やら意味らしきものも分かる様な気がします。
この方法を追及して行くやり方は、ありじゃないでしょうか。
では、また。














コメントを残す