
1.はじめに
今まで、1枚の人物画像から3Dテクスチャを推定する技術は、CNNのみを使ったものでした。今回ご紹介するのは、今までのCNNにTransformerを組み合わせ、入力画像の情報を効果的に活用したTexformerという技術です。
2.Texformerとは?
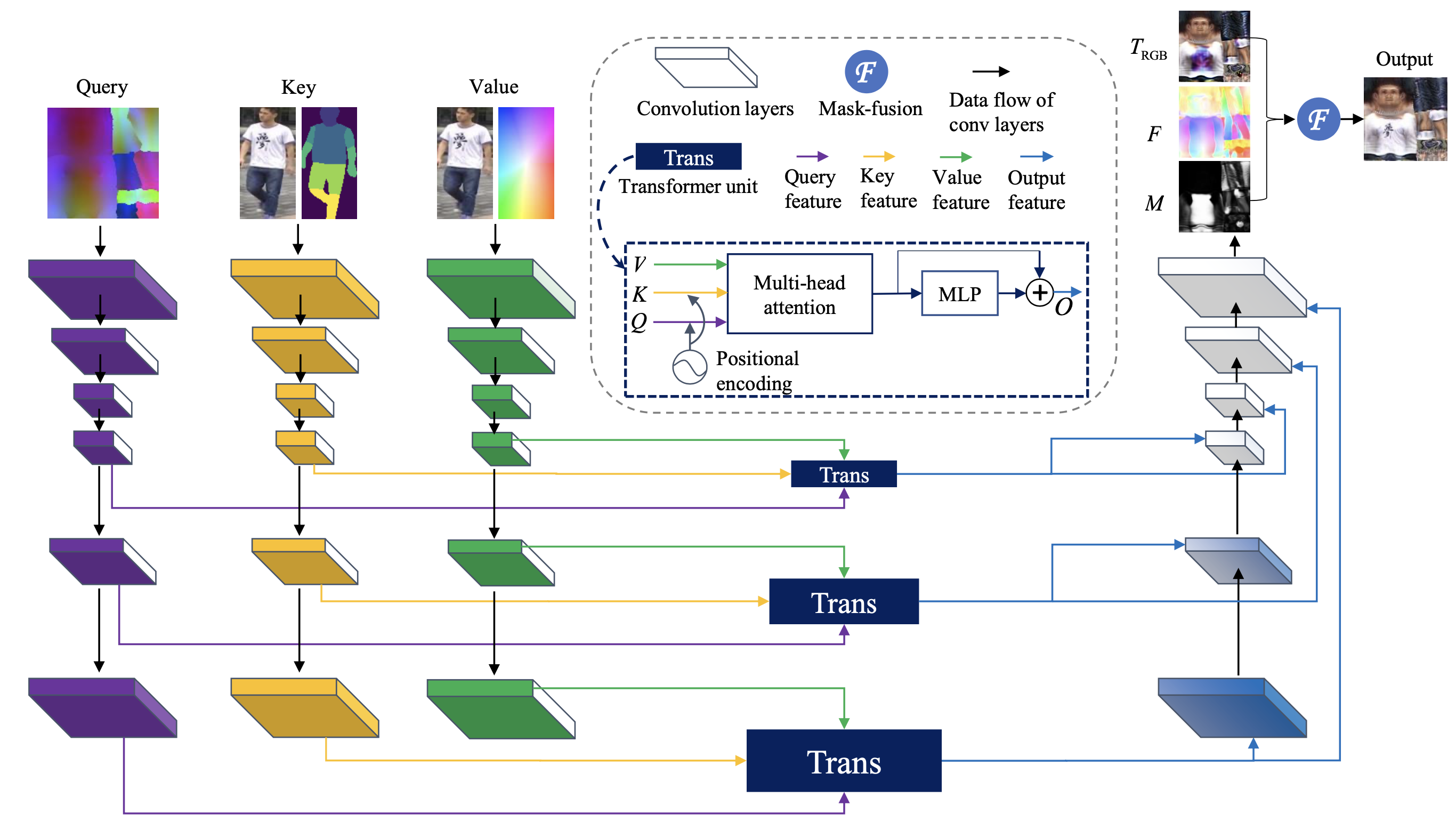
入力は、Query、Key、Valueの3つです。Queryはカラーエンコーディン、Keyは入力画像とセグメンテーションマップ、Valueは入力画像と座標です。この3つをそれぞれCNNで特徴量を抽出します。
そして、Transformerを使って、この3つの相互関係を複数のレイヤーで明確にして、もう1つのCNNに接続し融合します。
もう1つのCNNの出力は、Trgb(RGBマップ)、F(テクスチャフロー)、M(フュージョンマスク)で、最終的にこれらを組み合わせることでOutputを得ます。
では、早速コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# githubからコードを取得 ! git clone https://github.com/cedro3/Texformer.git %cd Texformer # pytorchバージョン変更 ! pip install torch==1.4.0+cu92 torchvision==0.5.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html # neural_renderインストール ! pip install neural_renderer_pytorch # その他のライブラリのインストール ! pip install imageio easydict smplx==0.1.13 scikit-image ! pip install scipy==1.5.2 # metaデータダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1LUimS6jmVW2Ynh4JNAiSWfqYUkxYQRpo', './meta.zip', quiet=False) ! unzip meta.zip # 学習済みパラメータダウンロード ! mkdir pretrained gdown.download('https://drive.google.com/uc?id=1QKGYkBSpb-jPaRuqtd2vzrW_5Pn4v567', './pretrained/texformer_ep500.pt', quiet=False) |
では、サンプル画像を使って3Dテクスチャを推定してみましょう。サンプル画像は、demo_imgsフォルダーに保存(img01.png〜img05.png)されています。自分で用意した画像で行う場合は、demo_imgsフォルダーにアップロードして下さい。画像サイズは、64×128(アルファチャンネル無し)です。
3Dテクスチャ推定には、demo.pyを使います。オプションは、–img_path の後に画像指定、–seg_pathの後にマスク画像指定、–save で推定結果を保存します。ここでは、サンプル画像はimg01.pngを選んでいます。
|
1 |
! python demo.py --img_path demo_imgs/img01.png --seg_path demo_imgs/seg.png --save |
推定結果を見てみましょう。結果は、demo_imgs/output.pngに保存されているので、これを表示させます。
|
1 2 |
from IPython.display import Image,display_png display_png(Image('demo_imgs/output.png')) |

推定結果を回転させた結果が、output.gifに保存されていますので、これを表示させます。
|
1 2 |
from IPython.display import Image Image('./output.gif', format='png') |

画像をimg02.pngに変えて実行すると、こんな感じ。

Transformerが、色々な分野に応用され出した感じがして、ワクワクして来ます。
では、また。
(オリジナルgithub)https://github.com/xuxy09/Texformer














コメントを残す