
今回は、オートエンコーダを使って、メガネ女子のメガネを取った顔を画像推定してみます
こんにちは cedro です。
たまたまメガネ女子がメガネを取るシーンに出くわした時、急に可愛く見えたり、色ぽく見えたりした経験はありませんか。
そんな経験から、メガネ女子のメガネを取った顔をディープラーニングで推定することは出来ないかと考えていました。
そうした中、先回のブログで、オートエンコーダによるノイズ除去の話を書いて、Twitter でも発信したら、「ニキビが消えるかも」なんてコメントをくれた人がいました。
そこで、「ニキビが消したいなら、ニキビ無しの顔画像を沢山食わせてから、ニキビ有りの顔画像を評価させると、ニキビはノイズだと思って消してくれるかも」というような意味の返信をしたのですが、このとき閃きました。
閃いたのは、メガネ無しの女子の顔画像を沢山オートエンコーダに学習させてから、メガネ女子の顔画像を評価させると、今まで学習したことの無いメガネはノイズだと思って消してくれるかもというアイディアです。
ということで、今回は、オートエンコーダを使って、メガネ女子のメガネを取った顔を画像推定してみます(笑)。
データを収集する
画像データの収集は、Windows のアプリ「ImageSpider」を使います。
このアプリは、キーワードを入力し、サイズ、種類、ダウンロード枚数などを指定すれば、後は自動で画像をダウンロードしてくれるという優れものです。こちらから、ダウンロードできます。
ダウンロードして解凍すると、こんなフォルダーが作成されます。インストールの必要はなく、フォルダーの中にあるアプリケーションをクリックすればアプリが起動します。
アプリを起動したら、必要な項目を入力して「ダウンロード」ボタンを押せば、アプリが入っているフォルダーの中に、キーワードのフォルダーが自動的に作成され、その中にダウンロードした画像を格納してくれます。これ、もの凄く楽ちんです。
なお、取得件数を「0」にしておくと、最大数でダウンロードになります。
今回は、AKB48のメンバー48人を指定して、画像を合計6,000枚ほどダウンロードしました。
次に、収集した画像データをOpen CVを使って顔部分のみ切り抜きます。具体的な方法は、1/4のブログ「顔画像生成に再びトライ」に詳しく書いてありますので、それをご覧下さい。

切り取った顔画像には、失敗作や狙いの人以外の顔も交じっていますので目でみて取捨選択します。最終的に3,140枚の顔画像になりました。

取捨選択の時に、メガネ女子をついでにピックアップし、メガネ女子データとして20枚確保しました。
そして、XnConvert を使ってリサイズを行います。今回の顔画像データは、とりあえず実験してみるという考え方で、カラー28×28ピクセルにします。
その後、Neural Network Console の+Create Dataset 機能でデータセットを作成(ラベルは全部0だけです)し、NNCに登録しておきます。
結果、作成したデータセットは、学習用データ2,826個(90%)、評価用データ314個(10%)、メガネ女子データ20個の3つです。
果たして、メガネ女子のメガネは消えるのか?
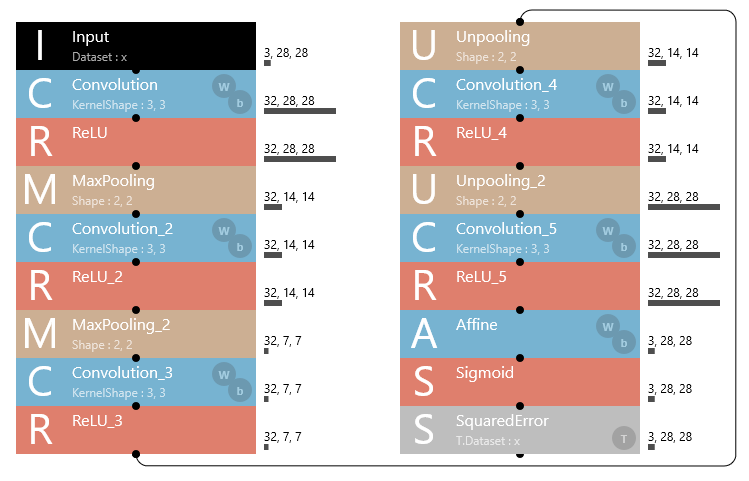
基本的に、使うネットワークは先回使ったものと同じです。但し、入出力のところだけ、モノクロからカラーに変更しています。

パラメーターの設定表です。前回と違うのは、InputとAffineを1,28,28 → 3,28,28 に変更しただけです。
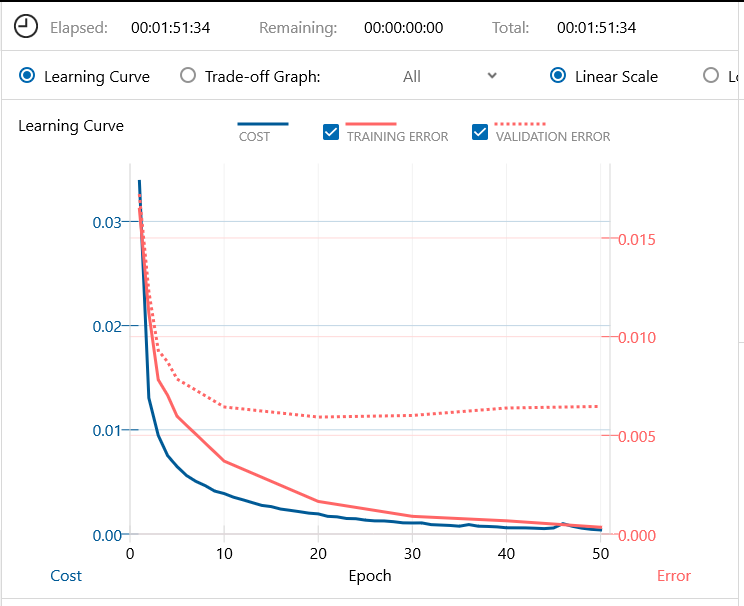
バッチ64、エポック50で学習を開始します。1時間51分で学習完了です。
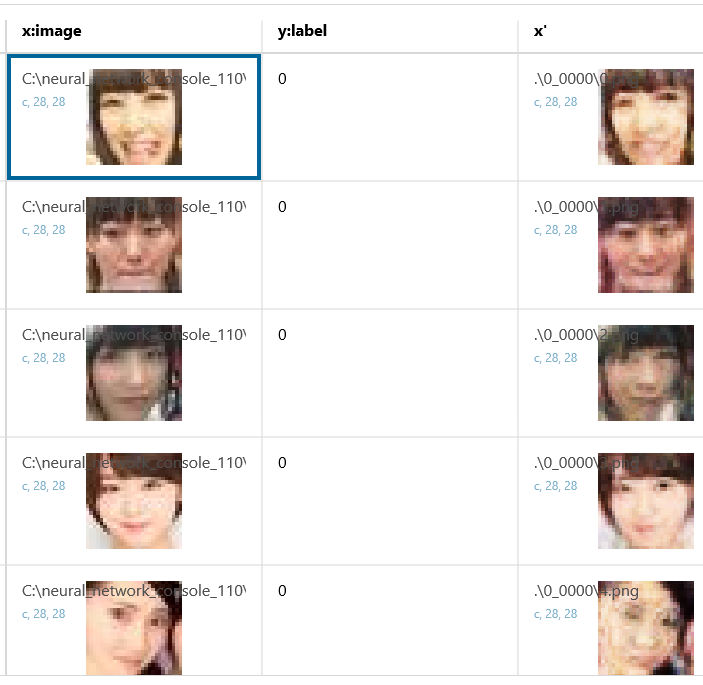
評価を実行してみます。次元圧縮によって特徴量を学習し、まずまず上手く復元出来ていますね。そして、この特徴量の中には、メガネは含まれていないのがミソです。

それでは、評価ファイルをメガネ女子データに入れ替えて、評価を再度実行します。
おっ!見事にメガネが消えているではありませんか。思った通り、学習したことのないメガネはノイズと判断した様です。
これって、もっとデータ数を増やして、ピクセル数を上げ、ネットワークも強化すると結構実用的になったりして(笑)。
いやー、温故知新のオートエンコーダ、結構面白いですね。
では、また。













初めまして!
最近、仕事でNNCの勉強をしていて、すごく参考にさせていただいてます。
質問なのですが、xとy2種類の画像を学習し、評価。
ここまではできるのですが、
画像zは、xか、yか、それ以外か?
この判別はNNC内で可能でしょうか?
お時間あれば、ご教示頂きたくコメント致しました。
宜しくお願いします。
マリーンさんへ
コメントありがとうございます。
そんなことができるなら、私もやり方を知りたいです(笑)。
たぶん、Neural Network Console Users (JP) にも質問されてますよね。
小林さんが的確な回答を出してくれるのを私も待っています。
私が、もし「x 」 か 「y」か 「それ以外」 かを識別する場合は、「x 」、 「y」、「それ以外」 の3種類の教師データを準備します。
さて、小林さんの回答楽しみですね。
では、また。
cedroさん、早速の回答ありがとうございました。
そうです。ニューラル~の方にも書き込みました笑 参考にしてる本等に載ってなかったので、とにかく出来るかどうかだけでもしりたくて…
やはりそれぞれ教師データは必要にはなりそうですね。
小林さん?の回答、頂けると嬉しいですね。
本当に有難うございました。これからも、ブログ記事参考にさせて頂きます。