
1.はじめに
今回ご紹介するのは、学習済みGANモデルを使ったクロスドメイン学習を少数の画像で可能にする Few shot gan adaptation という技術です。
*この論文は、2021.4に提出されました。
2.Few shot gan adaptation とは?
クロスドメイン学習とは、例えば大量の「実写」を学習したGANモデル(Large scale pre-training)が生成する画像に対応する「絵画」のデータや「赤ちゃん」のデータを別のGANモデルに学習させることです。こうすることによって、様々な「実写」に対応する「絵画」や「赤ちゃん」が生成できるGANモデルができます。

具体的に、実写→絵画のクロスドメイン学習を考えます。このとき単純に少数の画像だけで学習すると、どんなソース画像(Source Gs)を入力しても学習した画像だけをそのままターゲット画像(Overfit Gs→t)にする過剰適合という問題が発生します。 この問題点を解決し、ソース画像にきちんと対応したターゲット画像(Our Gs→t)にするのが今回の技術です。

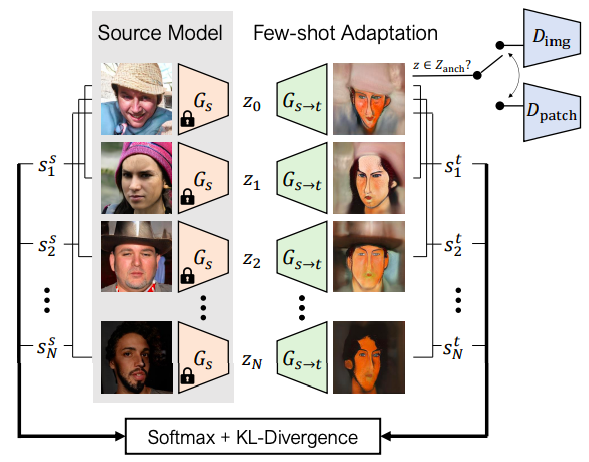
下記が、Few shot gan adaptation のフレームワークで、ポイントは2つです。1つ目は、ソースとターゲットのロスを計算するときに、それぞれの基準との距離も考慮することです(識別器はDpatchを使用)。こうすることで、対応するソースとターゲットの整合性が高まります。
2つ目は、少数の画像以外に、ランダムサンプリングしたソースにガウスノイズを加えたものについても同様な処理を行います(識別器はDimgを使用)。これによって、ソース全体とターゲット全体の潜在空間が同じような構造になります。
では、コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# github からコードを取得 ! git clone https://github.com/cedro3/few-shot-gan-adaptation.git %cd few-shot-gan-adaptation # ライブラリーのインストール ! pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html ! pip install pytorch-fid==0.1.1 ! pip install visdom==0.1.8.9 ! pip install lpips==0.1.3 ! pip install scipy==1.1.0 # ninja システムのインストール ! wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip ! sudo unzip ninja-linux.zip -d /usr/local/bin/ ! sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force # 学習済みパラメータのダウンロード import gdown gdown.download('https://drive.google.com/u/0/uc?id=1TQ_6x74RPQf03mSjtqUijM4MZEMyn7HI', 'source_ffhq.pt', quiet=False) gdown.download('https://drive.google.com/u/0/uc?id=1Qkdeyk_-1pqgvrIFy6AzsSYNgZMtwKX3', 'ffhq_sketches.pt', quiet=False) gdown.download('https://drive.google.com/u/0/uc?id=1CX8uYEWqlZaY7or_iuLp3ZFBcsOOXMt8', 'ffhq_caricatures.pt', quiet=False) # フォルダーの作成 import os os.makedirs('traversals', exist_ok=True) |
まず、「スケッチ」を学習したモデルで画像を生成してみましょう。ソースは、noise.pt (所定のベクトルを25個まとめたもの)を使います。
|
1 2 3 4 5 |
# Targetから画像生成 ! python generate_img.py --ckpt_target ffhq_sketches.pt --load_noise noise.pt from IPython.display import Image, display_png display_png(Image('./test_sample/sample.png')) |

それでは、「実写」モデルと「スケッチ」モデルの両方に、同じソースを入力した時の画像を並べて動画にしてみます。ソースは、noise.pt を使って補完(各ベクトル間を等分に割って、少しづつ変化させる)します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# source & target の画像補完 ! python generate_img.py --ckpt_source source_ffhq.pt --ckpt_target ffhq_sketches.pt\ --mode interpolate --load_noise noise.pt # output.mp4 ファイル削除 if os.path.exists('./output.mp4'): os.remove('./output.mp4') # traversals フォルダーの静止画から動画を作成 ! ffmpeg -r 15 -i traversals/sample%3d.png\ -vcodec libx264 -pix_fmt yuv420p output.mp4 |
|
1 2 3 4 5 6 7 8 9 10 |
# 動画再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
今度は、「アニメ」を学習したモデルで画像を生成してみましょう。ソースは、noise.pt (所定のベクトルを25個まとめたもの)を使います。
|
1 2 3 4 5 |
# GANからの画像生成(noise.pt) ! python generate_img.py --ckpt_target ffhq_caricatures.pt --load_noise noise.pt from IPython.display import Image, display_png display_png(Image('./test_sample/sample.png')) |

それでは、「実写」モデルと「アニメ」モデルの両方に、同じソースを入力した時の画像を並べて動画にしてみます。ソースは、noise.pt を使って補完(各ベクトル間を等分に割って、少しづつ変化させる)します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# source & target の画像補完 ! python generate_img.py --ckpt_source source_ffhq.pt --ckpt_target ffhq_caricatures.pt\ --mode interpolate --load_noise noise.pt # output.mp4 ファイル削除 if os.path.exists('./output.mp4'): os.remove('./output.mp4') # traversals フォルダーの静止画から動画を作成 ! ffmpeg -r 15 -i traversals/sample%3d.png\ -vcodec libx264 -pix_fmt yuv420p output.mp4 |
|
1 2 3 4 5 6 7 8 9 10 |
# 動画再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
この後 Colab には、ソースを random.seed(乱数系列)で指定するバージョンも用意してありますので、試してみて下さい。–rand の後の数字を変化させると色々な乱数系列を試せます。
では、また。
(オリジナルgithub)https://github.com/utkarshojha/few-shot-gan-adaptation














コメントを残す