
今回は、Keras AnoGANでMNISTの異常検知をしてみたいと思います。
先回、VAEによる異常検知をやってみました。最近発表された論文を分かり易く解説したブログがあったので、それをトレースしただけなのですが、私にとっては結構歯ごたえがあり、その分面白かったです。
そうした中、他の異常検知の手法が知りたくなり調べてみると、GANによる異常検知の手法があることが分かりました。
えっ?GANって生成モデルじゃなかったのと思いましたが、AnoGANというGANは異常検知が出来るらしく、GAN好きの私にとってはとても興味深く思えました。
というわけで、今回は、Keras AnoGANでMNISTの異常検知をしてみたいと思います。
AnoGANとは?
AnoGANとは、Anomaly Detection with Generative Adversarial Networksの略で、文字通りGANを使って異常検知をするという意味です。
GANは、多量の正常画像を学習すると、潜在空間の中に学習した正常画像を覚え込み、入力(ランダムノイズ)に応じて覚え込んだ様々な正常画像を生成出来るようになります。
AnoGANは、このGANの学習済みモデルを利用して、GANの入力を適切に変化させ、検査する画像に出来るだけ近い画像を生成させます。この時、検査する画像が潜在空間に含まれていないと上手く画像生成が出来ないので、異常と判断するわけです。
模式図を使って、もう少し詳しく説明しましょう。
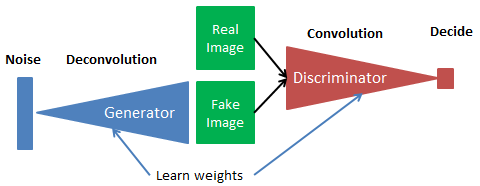
これが、GANの模式図です。Generatorは Noiseを入力としてFakeImage(偽画像)を生成することを学習します。Discriminatorは RealImage(本物画像)とFakeImage(偽画像)を間違えないように識別することを学習します。つまり、GeneratorとDiscriminator が切磋琢磨(Leran weights=重み学習)することによって、最終的には Generator が本物そっくりな偽画像が生成出来るようになります。
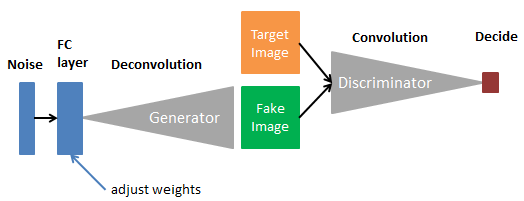
これが、AnoGANの模式図です。GANの学習済みモデルを利用して、GeneratorとDiscriminatorは新たに学習させず、FC layer を追加してその重みを調整し TargetImage(検査する画像)に出来るだけ近い FakeImage(偽画像)を生成させます。この時、TargetImageが今まで学習したものでないと上手くFakeImageが生成出来ません。従って、FakeImageと TargetImageを比較して、その差が小さければ正常、その差が大きければ異常と判断するわけです。
実装します
今回も先回同様、シンプルに mnist で実装します。正常画像は「1」、異常画像は「9」とします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Generator class Generator(object): def __init__(self, input_dim, image_shape): INITIAL_CHANNELS = 128 INITIAL_SIZE = 7 inputs = Input((input_dim,)) fc1 = Dense(input_dim=input_dim, units=INITIAL_CHANNELS * INITIAL_SIZE * INITIAL_SIZE)(inputs) fc1 = BatchNormalization()(fc1) fc1 = LeakyReLU(0.2)(fc1) fc2 = Reshape((INITIAL_SIZE, INITIAL_SIZE, INITIAL_CHANNELS), input_shape=(INITIAL_CHANNELS * INITIAL_SIZE * INITIAL_SIZE,))(fc1) up1 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(fc2) conv1 = Conv2D(64, (3, 3), padding='same')(up1) conv1 = BatchNormalization()(conv1) conv1 = Activation('relu')(conv1) up2 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv1) conv2 = Conv2D(image_shape[2], (5, 5), padding='same')(up2) outputs = Activation('tanh')(conv2) self.model = Model(inputs=[inputs], outputs=[outputs]) def get_model(self): return self.model # Discriminator class Discriminator(object): def __init__(self, input_shape): inputs = Input(input_shape) conv1 = Conv2D(64, (5, 5), padding='same')(inputs) conv1 = LeakyReLU(0.2)(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(128, (5, 5), padding='same')(pool1) conv2 = LeakyReLU(0.2)(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) fc1 = Flatten()(pool2) fc1 = Dense(1)(fc1) outputs = Activation('sigmoid')(fc1) self.model = Model(inputs=[inputs], outputs=[outputs]) |
Generator と Discriminator のコードです。このままだと分かり難いので、実際の入力を入れた場合のサマリーを下記に記載します。
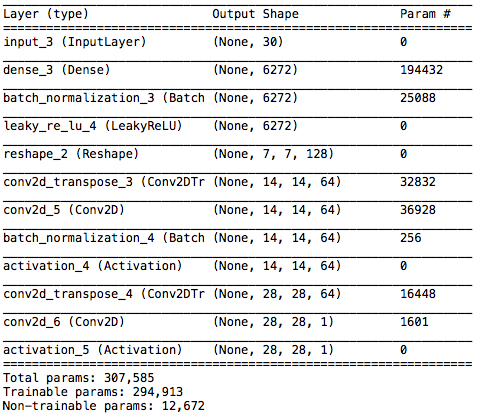
Generator のサマリーです。入力は30次元のランダムノイズ、これを6272個の全結合層で受けて、7×7画像128枚→14×14画像64枚→28×28画像1枚という逆畳み込みを行って偽画像を生成します。
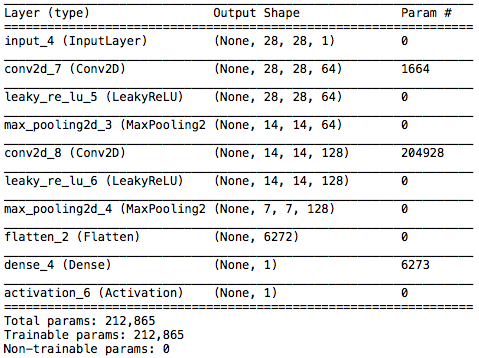
Discriminator のサマリーです。こちらは先程の逆で、28×28画像1枚→14×14画像64枚→7×7画像128枚と畳み込みを行って、6227個の全結合層に繋ぎ、画像判定を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
# DCGAN class DCGAN(object): def __init__(self, input_dim, image_shape): self.input_dim = input_dim self.d = Discriminator(image_shape).get_model() self.g = Generator(input_dim, image_shape).get_model() def compile(self, g_optim, d_optim): self.d.trainable = False self.dcgan = Sequential([self.g, self.d]) self.dcgan.compile(loss='binary_crossentropy', optimizer=g_optim) self.d.trainable = True self.d.compile(loss='binary_crossentropy', optimizer=d_optim) def train(self, epochs, batch_size, X_train): g_losses = [] d_losses = [] for epoch in range(epochs): np.random.shuffle(X_train) n_iter = X_train.shape[0] // batch_size progress_bar = Progbar(target=n_iter) for index in range(n_iter): # create random noise -> N latent vectors noise = np.random.uniform(-1, 1, size=(batch_size, self.input_dim)) # load real data & generate fake data image_batch = X_train[index * batch_size:(index + 1) * batch_size] for i in range(batch_size): if np.random.random() > 0.5: image_batch[i] = np.fliplr(image_batch[i]) if np.random.random() > 0.5: image_batch[i] = np.flipud(image_batch[i]) generated_images = self.g.predict(noise, verbose=0) # attach label for training discriminator X = np.concatenate((image_batch, generated_images)) y = np.array([1] * batch_size + [0] * batch_size) # training discriminator d_loss = self.d.train_on_batch(X, y) # training generator g_loss = self.dcgan.train_on_batch(noise, np.array([1] * batch_size)) progress_bar.update(index, values=[('g', g_loss), ('d', d_loss)]) g_losses.append(g_loss) d_losses.append(d_loss) if (epoch+1)%10 == 0: image = self.combine_images(generated_images) image = (image + 1) / 2.0 * 255.0 cv2.imwrite('./result/' + str(epoch) + ".png", image) print('\nEpoch' + str(epoch) + " end") # save weights for each epoch if (epoch+1)%50 == 0: self.g.save_weights('weights/generator_' + str(epoch) + '.h5', True) self.d.save_weights('weights/discriminator_' + str(epoch) + '.h5', True) return g_losses, d_losses def load_weights(self, g_weight, d_weight): self.g.load_weights(g_weight) self.d.load_weights(d_weight) def combine_images(self, generated_images): num = generated_images.shape[0] width = int(math.sqrt(num)) height = int(math.ceil(float(num) / width)) shape = generated_images.shape[1:4] image = np.zeros((height * shape[0], width * shape[1], shape[2]), dtype=generated_images.dtype) for index, img in enumerate(generated_images): i = int(index / width) j = index % width image[i * shape[0]:(i + 1) * shape[0], j * shape[1]:(j + 1) * shape[1], :] = img[:, :, :] return image |
DCGANのコードです。3−14行目は、Generator とDiscriminator を組み合わせて、DCGANを構成する関数です。
16−48行目は、DCGANを学習させる関数です。25行目で入力のランダムノイズを発生させ、28−38行目で学習画像と偽画像を比較、41−48行目で2つのロス計算をします。
49−53行目は generatror の生成画像を10epoch毎に4×4に連結して result フォルダーに保存する部分で、途中で65−76行目の画像を連結させる関数を呼び出しています。
56−59行目は、 generator と discriminator が学習した重みファイルを50epoch毎に weights フォルダーに格納する部分です。
61−63行目は、generator と discriminator が学習した重みファイルを読み込む関数 で、これは学習後のテスト時に使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# AnoGAN def sum_of_residual(y_true, y_pred): return K.sum(K.abs(y_true - y_pred)) class ANOGAN(object): def __init__(self, input_dim, g): self.input_dim = input_dim self.g = g g.trainable = False # Input layer cann't be trained. Add new layer as same size & same distribution anogan_in = Input(shape=(input_dim,)) g_in = Dense((input_dim), activation='tanh', trainable=True)(anogan_in) g_out = g(g_in) self.model = Model(inputs=anogan_in, outputs=g_out) self.model_weight = None def compile(self, optim): self.model.compile(loss=sum_of_residual, optimizer=optim) K.set_learning_phase(0) def compute_anomaly_score(self, x, iterations=300): z = np.random.uniform(-1, 1, size=(1, self.input_dim)) # learning for changing latent loss = self.model.fit(z, x, batch_size=1, epochs=iterations, verbose=0) loss = loss.history['loss'][-1] similar_data = self.model.predict_on_batch(z) return loss, similar_data |
AnoGANのコードです。3−20行目はDCGANの学習済みモデルを利用してAnoGANを構成する部分、22−30行目は検査する画像と生成画像の違いのスコアを計算する部分です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# train if __name__ == '__main__': batch_size = 16 epochs = 100 input_dim = 30 g_optim = Adam(lr=0.0001, beta_1=0.5, beta_2=0.999) d_optim = Adam(lr=0.0001, beta_1=0.5, beta_2=0.999) from keras.datasets import mnist #from keras.datasets import fashion_mnist # データセットの読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() #(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255 # 学習データの作成 x_train_1 = [] for i in range(len(x_train)): if y_train[i] == 1: x_train_1.append(x_train[i].reshape((28, 28, 1))) x_train_1 = np.array(x_train_1) print("train data:",len(x_train_1)) # 評価データの作成(n = 100) cnt = 0 x_test_9, y = [], [] for i in range(len(x_test)): if y_test[i] == 1 or y_test[i] == 9: x_test_9.append(x_test[i].reshape((28, 28, 1))) y.append(y_test[i]) cnt +=1 if cnt == 100: break x_test_9 = np.array(x_test_9) print("test_data:",len(x_test_9)) input_shape = x_train_1[0].shape X_test_original = x_test_9.copy() # train generator & discriminator dcgan = DCGAN(input_dim, input_shape) dcgan.compile(g_optim, d_optim) g_losses, d_losses = dcgan.train(epochs, batch_size, x_train_1) with open('loss.csv', 'w') as f: for g_loss, d_loss in zip(g_losses, d_losses): f.write(str(g_loss) + ',' + str(d_loss) + '\n') |
学習を実行するコードです。3−8行目は各種設定部分、10−44行目はデータセット作成部分(学習データは6742個、評価データは100個)、47−52行目はDCGANを学習させ、ロスの推移をファイル(’loss.csv’)に書き込む部分です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# test import keras.backend as K K.set_learning_phase(1) def denormalize(X): return ((X + 1.0)/2.0*255.0).astype(dtype=np.uint8) if __name__ == '__main__': iterations = 100 input_dim = 30 anogan_optim = Adam(lr=0.001, beta_1=0.9, beta_2=0.999) # load weights dcgan = DCGAN(input_dim, input_shape) dcgan.load_weights('weights/generator_99.h5', 'weights/discriminator_99.h5') #3999.99 for i, test_img in enumerate(x_test_9): test_img = test_img[np.newaxis,:,:,:] anogan = ANOGAN(input_dim, dcgan.g) anogan.compile(anogan_optim) anomaly_score, generated_img = anogan.compute_anomaly_score(test_img, iterations) generated_img = denormalize(generated_img) imgs = np.concatenate((denormalize(test_img[0]), generated_img[0]), axis=1) cv2.imwrite('predict' + os.sep + str(int(anomaly_score)) + '_' + str(i) + '.png', imgs) print(str(i) + ' %.2f'%anomaly_score) if y[i] == 1 : with open('scores_1.txt', 'a') as f: f.write(str(anomaly_score) + '\n') else: with open('scores_9.txt', 'a') as f: f.write(str(anomaly_score) + '\n') # plot histgram import matplotlib.pyplot as plt import csv x =[] with open('scores_1.txt', 'r') as f: reader = csv.reader(f) for row in reader: row = int(float(row[0])) x.append(row) y =[] with open('scores_9.txt', 'r') as f: reader = csv.reader(f) for row in reader: row = int(float(row[0])) y.append(row) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(x, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(y, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='9') plt.legend(loc=1) plt.savefig("histgram.png") plt.show() plt.close() |
評価画像をテストするコードです。15−16行目はGeneratorとDiscriminator の学習した重みを読み込む部分、18−22行目は評価画像と生成画像の違いのスコアを計算する部分、24−27行目は評価画像と生成画像をペアにした画像をpredict フォルダーに保存する部分です。
29−34行目はスコアを保存する部分です。評価画像が「1」の場合のスコアは ’scores_1.txt’ に、「9」の場合のスコアは ‘scores_9.txt’ に保存します。
37−61行目はスコア・ヒストグラムを作成する部分です。検査する画像が「1」の場合と「9」の場合のスコア・ヒストグラムを重ね描きし、’histgram.png’ で保存します。
コードを実行します
適当なフォルダーに、コード全体(train.pyとか名前を付ける)、result フォルダー、weights フォルダー、predict フォルダーを格納し、コードを実行します。なお、コード全体はブログの最後に記載してあります。
DCGANを学習させる部分は割と重いですが、ノートパソコンでもなんとかやれるレベルです。私の MabookAir だと200sec/epoch で、100epoch で5時間半くらいというところ。学習が完了すると、自動的にテストを開始しますが、こちらは軽快に動きます。

学習時、result フォルダーに保存されるGeneratorの生成画像です。100epochで、色々な「1」を生成出来る様になります。。

テスト時、predict フォルダーに保存される 画像です。各画像の左が評価画像、右が生成画像です。学習した「1」に関しては、色々な「1」を見事に再現出来ています。

一方、学習をしてない「9」に関しては、全く再現が出来ていません。
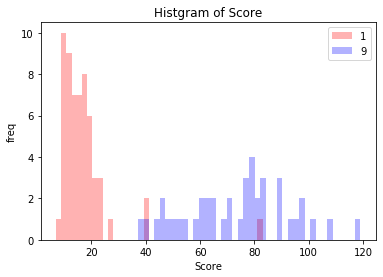
評価画像100個のスコア・ヒストグラム(’histgram.png’で保存されています)です。「1」は赤「9」は青でプロットしています。「1」と「9」のヒストグラムの重なりはほとんどなく、上手く異常検知出来てますね。今回の場合、スコアの閾値を28〜36の間に設定すると、97%くらいの精度で異常検知が出来ることが分かります。
AnoGANはテスト時に評価画像に出来るだけ近い画像を探索するトライが必要(今回は300回)なので、その分応答性は今一つですが、精度はまずまずという感触です。
また、本ブログ作成に際して、参考にさせて頂いたブログは「旅行好きなソフトエンジニアの備忘録」です。感謝致します!
最後に、コード全体を載せておきます。
では、また。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 |
from keras.utils. generic_utils import Progbar from keras.models import Model, Sequential from keras.layers import Input, Dense, Conv2D, MaxPooling2D, BatchNormalization, LeakyReLU, Reshape, Conv2DTranspose, Flatten from keras.layers.core import Activation from keras.optimizers import Adam import keras.backend as K import math, cv2 import numpy as np import os # Generator class Generator(object): def __init__(self, input_dim, image_shape): INITIAL_CHANNELS = 128 INITIAL_SIZE = 7 inputs = Input((input_dim,)) fc1 = Dense(input_dim=input_dim, units=INITIAL_CHANNELS * INITIAL_SIZE * INITIAL_SIZE)(inputs) fc1 = BatchNormalization()(fc1) fc1 = LeakyReLU(0.2)(fc1) fc2 = Reshape((INITIAL_SIZE, INITIAL_SIZE, INITIAL_CHANNELS), input_shape=(INITIAL_CHANNELS * INITIAL_SIZE * INITIAL_SIZE,))(fc1) up1 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(fc2) conv1 = Conv2D(64, (3, 3), padding='same')(up1) conv1 = BatchNormalization()(conv1) conv1 = Activation('relu')(conv1) up2 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv1) conv2 = Conv2D(image_shape[2], (5, 5), padding='same')(up2) outputs = Activation('tanh')(conv2) self.model = Model(inputs=[inputs], outputs=[outputs]) def get_model(self): return self.model # Discriminator class Discriminator(object): def __init__(self, input_shape): inputs = Input(input_shape) conv1 = Conv2D(64, (5, 5), padding='same')(inputs) conv1 = LeakyReLU(0.2)(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(128, (5, 5), padding='same')(pool1) conv2 = LeakyReLU(0.2)(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) fc1 = Flatten()(pool2) fc1 = Dense(1)(fc1) outputs = Activation('sigmoid')(fc1) self.model = Model(inputs=[inputs], outputs=[outputs]) def get_model(self): return self.model # DCGAN class DCGAN(object): def __init__(self, input_dim, image_shape): self.input_dim = input_dim self.d = Discriminator(image_shape).get_model() self.g = Generator(input_dim, image_shape).get_model() def compile(self, g_optim, d_optim): self.d.trainable = False self.dcgan = Sequential([self.g, self.d]) self.dcgan.compile(loss='binary_crossentropy', optimizer=g_optim) self.d.trainable = True self.d.compile(loss='binary_crossentropy', optimizer=d_optim) def train(self, epochs, batch_size, X_train): g_losses = [] d_losses = [] for epoch in range(epochs): np.random.shuffle(X_train) n_iter = X_train.shape[0] // batch_size progress_bar = Progbar(target=n_iter) for index in range(n_iter): # create random noise -> N latent vectors noise = np.random.uniform(-1, 1, size=(batch_size, self.input_dim)) # load real data & generate fake data image_batch = X_train[index * batch_size:(index + 1) * batch_size] for i in range(batch_size): if np.random.random() > 0.5: image_batch[i] = np.fliplr(image_batch[i]) if np.random.random() > 0.5: image_batch[i] = np.flipud(image_batch[i]) generated_images = self.g.predict(noise, verbose=0) # attach label for training discriminator X = np.concatenate((image_batch, generated_images)) y = np.array([1] * batch_size + [0] * batch_size) # training discriminator d_loss = self.d.train_on_batch(X, y) # training generator g_loss = self.dcgan.train_on_batch(noise, np.array([1] * batch_size)) progress_bar.update(index, values=[('g', g_loss), ('d', d_loss)]) g_losses.append(g_loss) d_losses.append(d_loss) if (epoch+1)%10 == 0: image = self.combine_images(generated_images) image = (image + 1) / 2.0 * 255.0 cv2.imwrite('./result/' + str(epoch) + ".png", image) print('\nEpoch' + str(epoch) + " end") # save weights for each epoch if (epoch+1)%50 == 0: self.g.save_weights('weights/generator_' + str(epoch) + '.h5', True) self.d.save_weights('weights/discriminator_' + str(epoch) + '.h5', True) return g_losses, d_losses def load_weights(self, g_weight, d_weight): self.g.load_weights(g_weight) self.d.load_weights(d_weight) def combine_images(self, generated_images): num = generated_images.shape[0] width = int(math.sqrt(num)) height = int(math.ceil(float(num) / width)) shape = generated_images.shape[1:4] image = np.zeros((height * shape[0], width * shape[1], shape[2]), dtype=generated_images.dtype) for index, img in enumerate(generated_images): i = int(index / width) j = index % width image[i * shape[0]:(i + 1) * shape[0], j * shape[1]:(j + 1) * shape[1], :] = img[:, :, :] return image # AnoGAN def sum_of_residual(y_true, y_pred): return K.sum(K.abs(y_true - y_pred)) class ANOGAN(object): def __init__(self, input_dim, g): self.input_dim = input_dim self.g = g g.trainable = False # Input layer cann't be trained. Add new layer as same size & same distribution anogan_in = Input(shape=(input_dim,)) g_in = Dense((input_dim), activation='tanh', trainable=True)(anogan_in) g_out = g(g_in) self.model = Model(inputs=anogan_in, outputs=g_out) self.model_weight = None def compile(self, optim): self.model.compile(loss=sum_of_residual, optimizer=optim) K.set_learning_phase(0) def compute_anomaly_score(self, x, iterations=300): z = np.random.uniform(-1, 1, size=(1, self.input_dim)) # learning for changing latent loss = self.model.fit(z, x, batch_size=1, epochs=iterations, verbose=0) loss = loss.history['loss'][-1] similar_data = self.model.predict_on_batch(z) return loss, similar_data # train if __name__ == '__main__': batch_size = 16 epochs = 100 input_dim = 30 g_optim = Adam(lr=0.0001, beta_1=0.5, beta_2=0.999) d_optim = Adam(lr=0.0001, beta_1=0.5, beta_2=0.999) from keras.datasets import mnist #from keras.datasets import fashion_mnist # データセットの読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() #(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data() # Fashion MNIST x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255 # 学習データの作成 x_train_1 = [] for i in range(len(x_train)): if y_train[i] == 1: x_train_1.append(x_train[i].reshape((28, 28, 1))) x_train_1 = np.array(x_train_1) print("train data:",len(x_train_1)) # 評価データの作成 cnt = 0 x_test_9, y = [], [] for i in range(len(x_test)): if y_test[i] == 1 or y_test[i] == 9: x_test_9.append(x_test[i].reshape((28, 28, 1))) y.append(y_test[i]) cnt +=1 if cnt == 100: break x_test_9 = np.array(x_test_9) print("test_data:",len(x_test_9)) input_shape = x_train_1[0].shape X_test_original = x_test_9.copy() # train generator & discriminator dcgan = DCGAN(input_dim, input_shape) dcgan.compile(g_optim, d_optim) g_losses, d_losses = dcgan.train(epochs, batch_size, x_train_1) with open('loss.csv', 'w') as f: for g_loss, d_loss in zip(g_losses, d_losses): f.write(str(g_loss) + ',' + str(d_loss) + '\n') # test K.set_learning_phase(1) def denormalize(X): return ((X + 1.0)/2.0*255.0).astype(dtype=np.uint8) if __name__ == '__main__': iterations = 100 input_dim = 30 anogan_optim = Adam(lr=0.001, beta_1=0.9, beta_2=0.999) # load weights dcgan = DCGAN(input_dim, input_shape) dcgan.load_weights('weights/generator_99.h5', 'weights/discriminator_99.h5') #3999.99 for i, test_img in enumerate(x_test_9): test_img = test_img[np.newaxis,:,:,:] anogan = ANOGAN(input_dim, dcgan.g) anogan.compile(anogan_optim) anomaly_score, generated_img = anogan.compute_anomaly_score(test_img, iterations) generated_img = denormalize(generated_img) imgs = np.concatenate((denormalize(test_img[0]), generated_img[0]), axis=1) cv2.imwrite('predict' + os.sep + str(int(anomaly_score)) + '_' + str(i) + '.png', imgs) print(str(i) + ' %.2f'%anomaly_score) if y[i] == 1 : with open('scores_1.txt', 'a') as f: f.write(str(anomaly_score) + '\n') else: with open('scores_9.txt', 'a') as f: f.write(str(anomaly_score) + '\n') # plot histgram import matplotlib.pyplot as plt import csv x =[] with open('scores_1.txt', 'r') as f: reader = csv.reader(f) for row in reader: row = int(float(row[0])) x.append(row) y =[] with open('scores_9.txt', 'r') as f: reader = csv.reader(f) for row in reader: row = int(float(row[0])) y.append(row) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(x, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(y, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='9') plt.legend(loc=1) plt.savefig("histgram.png") plt.show() plt.close() |














コメントを残す