1.はじめに
今まで、画像のセグメンテーションは、YolactEdge や Mask R-CNN のような物体を検出して形を推定するものをご紹介しましたが、今回ご紹介するのはセマンティック・セグメンテーションと呼ばれるタスクで、画像をピクセル単位でカテゴリを分類する PSPNet です。
*この論文は、2017.4に提出されました。
2.PSPNetとは?
下記に、PSPNetの概要を示します。
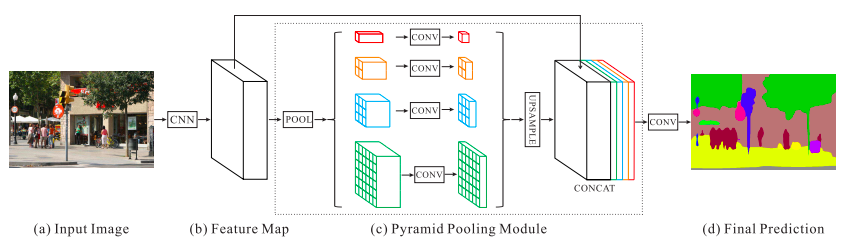
まず、Input Image(入力画像)を CNN に入力し Feature Map(特徴マップ)を取得します。次に、プーリングを通して Pyramid Pooling Module で、様々なスケールでの領域表現を収集したものを、先程の Feature Map とCONCAT(連結)させます。最後に、畳み込み層を通して Final Prediction(最終的なピクセル毎の予測を)取得します。
早速、コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 |
%%bash # Colab-specific setup !(stat -t /usr/local/lib/*/dist-packages/google/colab > /dev/null 2>&1) && exit pip install yacs 2>&1 >> install.log git init 2>&1 >> install.log git remote add origin https://github.com/CSAILVision/semantic-segmentation-pytorch.git 2>> install.log git pull origin master 2>&1 >> install.log DOWNLOAD_ONLY=1 ./demo_test.sh 2>> install.log |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# System libs import os, csv, torch, numpy, scipy.io, PIL.Image, torchvision.transforms # Our libs from mit_semseg.models import ModelBuilder, SegmentationModule from mit_semseg.utils import colorEncode colors = scipy.io.loadmat('data/color150.mat')['colors'] names = {} with open('data/object150_info.csv') as f: reader = csv.reader(f) next(reader) for row in reader: names[int(row[0])] = row[5].split(";")[0] def visualize_result(img, pred, index=None): # filter prediction class if requested if index is not None: pred = pred.copy() pred[pred != index] = -1 print(f'{names[index+1]}:') # colorize prediction pred_color = colorEncode(pred, colors).astype(numpy.uint8) # aggregate images and save im_vis = numpy.concatenate((img, pred_color), axis=1) display(PIL.Image.fromarray(im_vis)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Network Builders net_encoder = ModelBuilder.build_encoder( arch='resnet50dilated', fc_dim=2048, weights='ckpt/ade20k-resnet50dilated-ppm_deepsup/encoder_epoch_20.pth') net_decoder = ModelBuilder.build_decoder( arch='ppm_deepsup', fc_dim=2048, num_class=150, weights='ckpt/ade20k-resnet50dilated-ppm_deepsup/decoder_epoch_20.pth', use_softmax=True) crit = torch.nn.NLLLoss(ignore_index=-1) segmentation_module = SegmentationModule(net_encoder, net_decoder, crit) segmentation_module.eval() segmentation_module.cuda() |
次に、サンプル画像を読み込みます。自分の画像を使用したい場合は、カレントディレクトリに自分の画像をドラッグ&ドロップでアップロードし、pil_image = PIL.Image.open(‘***.jpg’).convert(‘RGB’)の’***.jpg’の部分を変更して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Load and normalize one image as a singleton tensor batch pil_to_tensor = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( mean=[0.485, 0.456, 0.406], # These are RGB mean+std values std=[0.229, 0.224, 0.225]) # across a large photo dataset. ]) pil_image = PIL.Image.open('ADE_val_00001519.jpg').convert('RGB') img_original = numpy.array(pil_image) img_data = pil_to_tensor(pil_image) singleton_batch = {'img_data': img_data[None].cuda()} output_size = img_data.shape[1:] |
読み込んだ画像にセマンティック・セグメンテーションを掛けて、表示させます。
|
1 2 3 4 5 6 7 8 |
# Run the segmentation at the highest resolution. with torch.no_grad(): scores = segmentation_module(singleton_batch, segSize=output_size) # Get the predicted scores for each pixel _, pred = torch.max(scores, dim=1) pred = pred.cpu()[0].numpy() visualize_result(img_original, pred) |

画像を構成するピクセル毎に色分けされ、カテゴリ分類されているのが分かります。
それでは、カテゴリー分類した結果のTOP15を1つづつ表示させます。
|
1 2 3 4 |
# Top classes in answer predicted_classes = numpy.bincount(pred.flatten()).argsort()[::-1] for c in predicted_classes[:15]: visualize_result(img_original, pred, c) |








——————————————– 以下略 ———————————————-
それでは、今度は動画でやってみましょう。まず、サンプルビデオをダウンロードします。
|
1 2 3 |
# サンプルビデオをダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1cfa4R-0Zwd2Te5-qBWe9oNRKQ_pEUr0z', 'road.mp4', quiet=False) |
サンプルビデオから静止画を切り出し、連番のjpg画像として images フォルダーに保存します。設定は、3フレーム毎に切り出す形(interval = 3)にしています。
ご自分のビデオを使う場合は、自分のPCからカレントディレクトリへビデオをドラッグ&ドロップでアップロードし、video_file = の部分を変更して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# サンプルビデオを静止画に変換 import os import shutil import cv2 def video_2_images(video_file= './road.mp4', # ビデオ指定 image_dir='./images/', image_file='%s.jpg'): # Initial setting i = 0 interval = 3 length = 600 # 最大フレーム数 cap = cv2.VideoCapture(video_file) while(cap.isOpened()): flag, frame = cap.read() if flag == False: break if i == length*interval: break if i % interval == 0: cv2.imwrite(image_dir+image_file % str(int(i/interval)).zfill(6), frame) i += 1 cap.release() # imagesフォルダーリセット if os.path.isdir('images'): shutil.rmtree('images') os.makedirs('images', exist_ok=True) # ビデオを静止画に変換 video_2_images() |
images フォルダーにある連番のjpg画像をセマンティック・セグメンテーションしたものに置き換えます。ファイル名は変更しません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 静止画をセグメンテーションに変換 # 正規化データをロード pil_to_tensor = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( mean=[0.485, 0.456, 0.406], # These are RGB mean+std values std=[0.229, 0.224, 0.225]) # across a large photo dataset. ]) # imagesフォルダーの静止画を1枚づつ処理 from tqdm import tqdm import glob files = glob.glob('./images/*.jpg') files.sort() for file in tqdm(files): pil_image = PIL.Image.open(file).convert('RGB') img_original = numpy.array(pil_image) img_data = pil_to_tensor(pil_image) singleton_batch = {'img_data': img_data[None].cuda()} output_size = img_data.shape[1:] # セグメンテーションの実行 with torch.no_grad(): scores = segmentation_module(singleton_batch, segSize=output_size) # 予測結果の処理 _, pred = torch.max(scores, dim=1) pred = pred.cpu()[0].numpy() pred_color = colorEncode(pred, colors).astype(numpy.uint8) im_vis = numpy.concatenate((img_original, pred_color), axis=1) # オリジナルと横連結 #im_vis = numpy.concatenate((pred_color, img_original), axis=0) # オリジナルと縦連結 PIL.Image.fromarray(im_vis).save(file) |
ffmpeg を使って、images フォルダーにある連番の jpg 画像を動画(output.mp4)に変換します。
|
1 2 3 4 5 6 |
# output.mp4をリセット if os.path.exists('./output.mp4'): os.remove('./output.mp4') # 実写+セグメンテーションをmp4動画に変換 !ffmpeg -r 10 -i images/%06d.jpg -vcodec libx264 -pix_fmt yuv420p output.mp4 |
|
1 2 3 4 5 6 7 8 9 10 |
# mp4動画の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('./output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="100%" height="100%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |

では、また。
(オリジナルgithub)https://github.com/CSAILVision/semantic-segmentation-pytorch













コメントを残す