
今回は、StackGANの学習済みモデルを使って文章から画像をサクッと生成してみます。
こんにちは cedro です。
以前ブログで、画像から文章を生成してみました。そうすると、今度はその逆、文章から画像を生成してみたくなるわけです。
文章から画像を生成するモデルは色々ありますが、その中で最も有名なものの1つに 2017年に発表された StackGAN があります。
一般的に、文章からの画像生成は画像がボヤけた形になり易いのですが、StackGANは2段階の画像生成によって、それまでのモデルより画像がシャープになったと言われています。
ということで、今回は、StackGANの学習済みモデルを使って文章から画像をサクッと生成してみます。
StackGANとは?
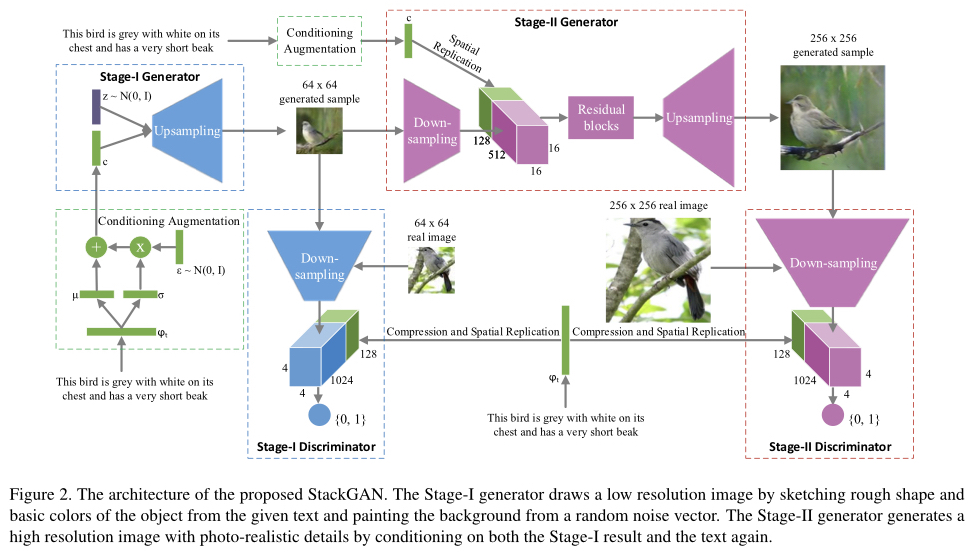
StackGAN は、 Conditonal GANの一種です。Generator は入力文章をベクトル化したものをConditioning Augmentation(文章条件)として、ランダムノイズからリアル画像に出来るだけ近いフェイク画像を生成します。一方、Discriminator は そのフェイク画像をリアル画像と間違えない様に判定します。Generator とDiscriminator の切磋琢磨によって、フェイク画像の完成度が上がるわけです。
StackGANは、これを2つのステージで行います。第1ステージでは、64×64ピクセルの画像でGeneratorとDiscriminatorの切磋琢磨を行い、第2ステージでは256×256ピクセルの画像で行うことで、画像をそれまでよりもシャープなものにすることを可能にしました。
コードを準備します
StackGANの学習済みモデルには、学習範囲を「花」とか「鳥」など対象を絞ったものと、coco データセットの様な森羅万象を対象にしたものがあります。
当然、「花」とか「鳥」に対象を絞った方が画像の完成度が上がるわけすが、見た目の変化が少なくて面白みに欠けるので、今回は対象を森羅万象の方にします。
ということで、今回は、Githubにある hanzhanggit/StackGAN-Pytorch のサンプルコードを使います。
実は、このサンプルコード、2年前に作られたもので、Python 2.7で動く仕様になっていて、動作環境を作るのが面倒です。なので、 今回はGoogle Colab を使って動かしてみます。
Google colab を使うと、こういう時、無駄に自分の環境を汚さなくて、便利ですよね。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
Google Colab に接続します。ファイル/python2 の新しいノートブックを開いたら、ランタイム/ランタイムのタイプを変更でGPUを選択して保存します。そして、上記コマンドをコピペして動かします。
実行するとこんな表示が出ます。リンクをクリックし、アカウントを選択したら、authorization code が表示されるので、これを四角内にコピぺすれば、Googole Driveがマウントされます。
|
1 2 3 |
cd drive/My Drive !git clone https://github.com/hanzhanggit/StackGAN-Pytorch.git cd StackGAN-Pytorch |
Google Drive/My Drive にサンプルコードを git clone し、ディレクトリを StackGAN-Pytorch に移すコマンドです。 1行づつコピペして実行します。
|
1 2 |
!pip install torchfile !pip install tensorboard-pytorch |
必要なライブラリーをインストールするコマンドです。 1行づつコピペして実行します。
|
1 2 |
!pip uninstall protobuf !pip install --no-binary=protobuf protobuf |
このまま進めると、TypeError: Couldn’t build proto file into descriptor pool! というエラーが出てしまいます。これを回避するために、protobuf を一端アンイストールしてから、ノーバイナリーで protobuf を再インストールします。上記コードを1行づつ実行します。
テスト用データセット(coco_test.zip)をダウンロードし解凍します。解凍すると3つファイルが現れますので、Google drive を使って、その中の val_captions.t7 を StackGAN-pytorch/data/coco/test フォルダーの中に格納します。coco フォルダーと test フォルダーは自分で作成して下さい。
val_captions.txt は後程、自分の好きな文章の画像生成をする時に使いますので、PCの何処かに保存して置いて下さい。
学習済みモデル(coco_netG_epoch_90.pth)をダウンロードし、netG_epoch_90.pth にリネーム(先頭のcoco_を削除します)してから 、Google driveを使って、StackGAN-pytorch/models/coco に格納します。coco フォルダーは自分で作成して下さい。

結果、Google colab の左側のファイルのタブを見ると、こんな形になっているはずです。
コードを動かします
|
1 2 |
cd code !python main.py --cfg cfg/coco_eval.yml --gpu 0 |
このコードを1行づつコピペして実行します。実行すると、val_captions.txt に載っている、1〜3001行目の文章から生成した画像を、StackGAN-pytorch/models/coco/netG_epoch_90 の中に保存します。
Google colabの動作が完了しても、生成した画像を全て保存した結果が、Google drive に反映されるまでしばらく時間が掛かりますので、お待ち下さい。
これで、3001種類の文章から画像を1枚づつ生成したわけですが、まだ画像の完成度が低いせいか画像をざっと見てもどんな画像を生成しているのか分かり難いです。
なので次に、自分で選んだ文章1つにつき10個の画像を生成して、ばらつきを含めて生成画像を見てみたいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
def sample(self, datapath, stage=1): if stage == 1: netG, _ = self.load_network_stageI() else: netG, _ = self.load_network_stageII() netG.eval() # Load text embeddings generated from the encoder t_file = torchfile.load(datapath) captions_list = t_file.raw_txt embeddings = np.concatenate(t_file.fea_txt, axis=0) num_embeddings = len(captions_list) print('Successfully load sentences from: ', datapath) print('Total number of sentences:', num_embeddings) print('num_embeddings:', num_embeddings, embeddings.shape) # path to save generated samples save_dir = cfg.NET_G[:cfg.NET_G.find('.pth')] mkdir_p(save_dir) batch_size = 1 nz = cfg.Z_DIM noise = Variable(torch.FloatTensor(batch_size, nz)) if cfg.CUDA: noise = noise.cuda() count = [816,1334,1370,2886] for k in range(len(count)): embeddings_batch = embeddings[count[k]:count[k]+1] # captions_batch = captions_list[count:iend] txt_embedding = Variable(torch.FloatTensor(embeddings_batch)) if cfg.CUDA: txt_embedding = txt_embedding.cuda() ####################################################### # (2) Generate fake images ###################################################### #print(txt_embedding) print(count[k],captions_list[count[k]]) for i in range(10): # batch_size to 10 noise.data.normal_(0, 1) inputs = (txt_embedding, noise) _, fake_imgs, mu, logvar = \ nn.parallel.data_parallel(netG, inputs, self.gpus) save_name = '%s/%d.png' % (save_dir, count[k]*10 + i) im = fake_imgs[0].data.cpu().numpy() im = (im + 1.0) * 127.5 im = im.astype(np.uint8) # print('im', im.shape) im = np.transpose(im, (1, 2, 0)) # print('im', im.shape) im = Image.fromarray(im) im.save(save_name) |
指定した文章の画像を10枚づつ生成するコードです。Google drive でStackGAN-pytorch/code の中にある trainer.py をダウンロードし、エディターで開いて def sample 行から最後までを、このコードに置き換えます。
26行目の count = [ 816, 1334, 1370, 2886 ] のところは、先程ダウンロードした val_captions.txt にある40470個の文章の内どの文章の画像を生成するか行番号を記載します。なお、番号は0からスタートなので、100行目の文章の番号は99です。
後は、Google drive で、trainer.py を削除し、しばらく待ってから修正した trainer.py をアップロードすればOKです。
Google Colab, Google drive はネットで繋がっているため、変更が反映されるまで若干タイムラグがありますので、ゆっくり行って下さい。
|
1 |
!python main.py --cfg cfg/coco_eval.yml --gpu 0 |
後は、先程と全く同じく、上記のコードを実行します。実行結果を下記に載せます。なお( )内は Google 翻訳によるものです。

No.1370 a bus turning a corner on a city street.(街の通りを曲がるバス。)から生成した画像です。バスが見えない画像が下段に2枚含まれていますが、まあこんなものでしょうか。

No.1334 a lighted kitchen looks shiny clean and nice.(照明付きのキッチンは、清潔で光沢があります。)から生成した画像です。若干バスルーム風の画像も含まれていますが、まあまあの出来でしょうか。

No.816 a zebra grazes in a cage at a fair.(シマウマは公正でケージの中でかすめます。)から生成した画像です。()内のgoogle 翻訳がイマイチですね(笑)。とりあえず、全部の画像にシマウマの模様はある様です(笑)。

No.2886 a car is parked on the side of the street in the rain.(車は雨の中通りの脇に駐車しています。)から生成した画像です。雨の中という表現は難しいだろうなと思っていたら、下段右から2・3枚目は雨で濡れた地面の感じが良く出ていますね。
いやー、セグメント対象が森羅万象だと結構難しいですね。ピントはある程度シャープですが、画像としてはとりあえず雰囲気は出ているものの細部は結構いいかげんというレベルで、完成度はまだまだの様です。
但し、ディープラーニングの進歩のスピードは凄まじいですから、森羅万象を対象とした画像生成も、近い内に完成度が上がるかもしれませんね。
では、また。













コメント失礼します。
現在StackGANの勉強として当記事を参考に学習している者です。cedroさんの説明が分かりやすく無事画像生成することができました。そこでval_captions.txtを使って自分の好きな文章で画像を生成したいと思っています。やり方を教えて頂けたら嬉しいです。宜しくお願いします。
seiさん
val_caption.txtを使って自分の好きな文章で画像を生成するのは、学習から行う必要があり大変です。下記リンクのDALL-Eをおすすめします。これなら簡単です。
http://cedro3.com/ai/dall-e/