
1.はじめに
BERTは、事前学習+ファインチューニングの2段階学習によって、自然言語処理分野における11のタスクでSoTAを記録した革命的なモデルです。
今回はお手軽に、事前学習済みBERTモデルをファインチューニング無しでそのまま使って、センター試験や文章生成がどれくらい出来るかやらせてみたいと思います。
今回のコードは Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
2.BERTとは?
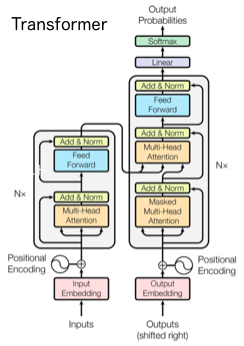
2017年12月にEncoder-Decoder翻訳モデルを並列処理が可能であるAttentionのみで構成したTransformerが発表されました。その後研究が進むにつれてTransformerに使われている Self Attention による文章の意味抽出能力が相当強力であることが分かりました。
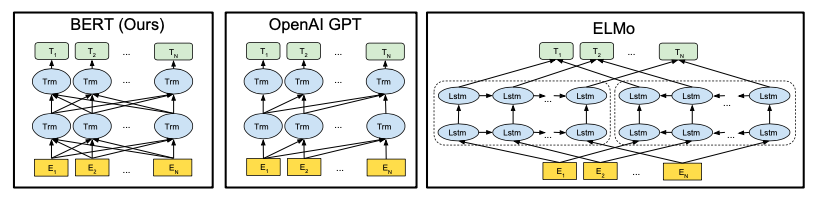
そこで、TransformerのEncoder部分のみを使ったOpenAI GPTが発表されSelf Attentionで性能が向上することが分かりましたが、前の文脈しか利用できませんでした。一方、双方向LSTMを採用した翻訳モデルELMoは、前後の文脈の活用で性能が向上することが分かりましたが、並列処理が行えませんでした。
そして2018年10月にBERTが発表されました。BERTは、Self Attentionで並列処理を行い、かつ事前学習の工夫によって前後の文脈を活用することを可能にしました。そして、事前学習+ファインチューニングの2段階学習によって様々なタスクへの対応を可能にし、現在主流のモデルになりました。
まず、Self Attentionについて簡単に説明します。入力(単語数, 次元数)に3つの全結合層を通してQuery, Key, Valueを作ります。つまり、入力に3つの重み(Wq, Wk, Wv)を掛けたものが、それぞれ Query, Key, Value となります。この3つの重みが学習の中で最適化されて行くわけです。
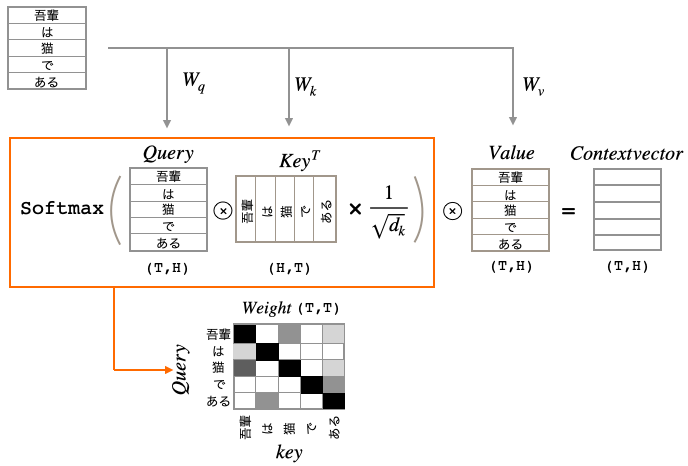
QueryとKey(転置)の内積によって、Queryの各ベクトルがKeyのどのベクトルと関連度が高いかを表す重み(Weight)を求めます。その後、ルートdkで割っているのは、Softmaxをかけた時に大き過ぎる値があるとそれ以外の数字が0になってしまうので、それを防止するためのものです。
そして、その重みとValueの内積によって、Valueの各ベクトルの重み付け和(Context vector)を求めます。結果、Contextvector は、QueryとKeyの掛かり受け構造がどうなっているのかを表すことになり、これが文の意味抽出において絶大な力を発揮します。
次に、前後の文脈を利用する事前学習の工夫を2つ説明します。
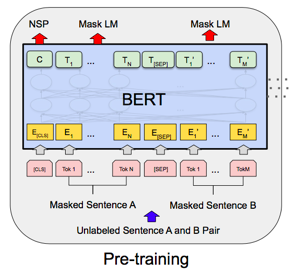
1つ目は、Masked Language Modelで、穴埋め問題を解かせることで前後の文脈を利用できるようにします。文全体の15%の単語を選び、その内80%をマスク、10%を他の単語に置き換え、10%をそのままにします。15%に抑えているのは、この後のファインチューニングでマスクは登場しないのでギャップが大きいとファインチューニングが上手く行かないためです。
2つ目は、Next Sentence Predictionで、2つの文が意味的に繋がっているかを判定するものです。
BERTの事前学習は、穴埋め問題を解く時に文の15%しか使わないため学習には相当時間が掛かりますが、その分ファインチューニングは学習量が少なく短時間で済みます。つまり、誰かが時間を掛けて事前学習をしてしまえば、色々な人が短時間のファインチューニングでBERTの恩恵に預かれると言うわけです。
ついでに、BERTの入力形態についても触れておくと、
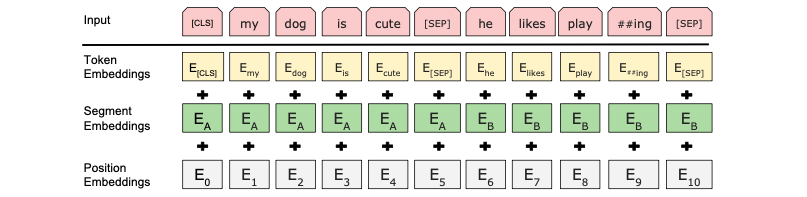
入力は、単語のベクトル表現(Token Embedding)に、文の区分を表すベクトル(Segment Embedding)と、単語位置を表すベクトル(Position Embedding)を加えたものです。
Segment Embedding と Psition Embedding が必要なのは、Self Attention で重み和を計算する時に、単語の位置情報を失うことを防ぐためです。
3. BERTにセンター試験を解かせる
なぜBERTにセンター試験を解かせようと思ったかと言うと、今回使うモデルが日本語Wikipediaを使って学習しているからです。つまり、今回使うモデルは、古今東西の様々な知識を穴埋め問題で解く形で勉強をしているわけで、それならセンター試験の穴埋め問題くらい解けるかもしれないと思って無茶振りした次第です。
まず、今回使うモジュール と形態素解析システム(JUMMAN++)をインストールし、京都大学が提供しているBERT事前学習済みモデルをダウンロードします。詳細は、Google Colabのコードを参照下さい。
さて、BERTに解かせる問題は、平成30年度の世界史Bの第2問の問1です。

正解は①の「貴族」と「カエサル」なわけですが、さてBERTはどう解答するでしょうか。
まず、必要なライブラリーをインポートし、BERTの設定をします。
|
1 2 3 4 5 6 7 8 9 10 |
import torch from transformers import BertTokenizer, BertForMaskedLM, BertConfig import numpy as np import textwrap config = BertConfig.from_json_file('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/config.json') model = BertForMaskedLM.from_pretrained('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/pytorch_model.bin', config=config) bert_tokenizer = BertTokenizer('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/vocab.txt', do_lower_case=False, do_basic_tokenize=False) from pyknp import Juman jumanpp = Juman() |
BERTへの入力は、単語リストの先頭に[CLS]を入れ、文の区切りに[SEP]を入れ、予測したい単語は[MASK]に置き換える仕様になっているので、それを行う関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 単語リストへ[CLS],[SEP],[MASK]を追加する関数 def preparation(tokenized_text): # [CLS],[SEP]の挿入 tokenized_text.insert(0, '[CLS]') # 単語リストの先頭に[CLS]を付ける tokenized_text.append('[SEP]') # 単語リストの最後に[SEP]を付ける maru = [] for i, word in enumerate(tokenized_text): if word =='。' and i !=len(tokenized_text)-2: # 「。」の位置検出 maru.append(i) for i, loc in enumerate(maru): tokenized_text.insert(loc+1+i, '[SEP]') # 単語リストの「。」の次に[SEP]を挿入する # 「□」を[MASK]に置き換え mask_index = [] for index, word in enumerate(tokenized_text): if word =='□': # 「□」の位置検出 tokenized_text[index] = '[MASK]' mask_index.append(index) return tokenized_text, mask_index |
この関数は、単語リストの先頭に[CLS]を挿入し、最後に[SEP]を付加し、途中は「。」の後に[SEP]を挿入します。そうやって単語位置を決めてから、予測箇所「□」を[MASK]に置き換え、単語リストと[MASK]位置を返します。
次に、テキストをIDテンソルに変換します。
|
1 2 3 4 5 6 7 |
# テキストをIDテンソルに変換 text = "ギリシア人ポリュビオスは,著書『歴史』の中で,ローマ共和政の国制(政治体制)を優れたものと評価している。彼によれば,その国制には,コンスルという王制的要素,元老院という□制的要素,民衆という民主制的要素が存在しており,これら三者が互いに協調や牽制をしあって均衡しているというのである。ローマ人はこの政治体制を誇りとしており,それは,彼らが自らの国家を指して呼んだ「ローマの元老院と民衆」という名称からも読み取ることができる。共和政期末の内戦を勝ち抜いたかに見えた□でさえも,この体制を壊そうとしているという疑いをかけれ,暗殺されてしまった。" result = jumanpp.analysis(text) # 分かち書き tokenized_text = [mrph.midasi for mrph in result.mrph_list()] # 単語リストに変換 tokenized_text, mask_index = preparation(tokenized_text) # [CLS],[SEP],[MASK]の追加 tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text) # IDリストに変換 tokens_tensor = torch.tensor([tokens]) # IDテンソルに変換 |
テキストを分かち書きして単語リストにし、先程の関数を使って[CLS],[SEP],[MASK]を追加したら、IDリストに変換し、Pytorchが読めるIDテンソルに変換しています。

こんな感じで変換をして行くわけです。
それでは、下記のコードを実行して、[MASK]箇所を推論(上位5つの候補)します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# [MASK]箇所を推論(TOP5) model.eval() tokens_tensor = tokens_tensor.to('cuda') model.to('cuda') print(textwrap.fill(text, 45)) print() with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0] for i in range(len(mask_index)): _, predicted_indexes = torch.topk(predictions[0, mask_index[i]], k=5) predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist()) print(i, predicted_tokens) |

無茶振りでしたが、1つ目の予測にはちゃんと正解の「貴族」が含まれています! 残念ながら2つ目の「カエサル」は正解できませんでしたが、BERT思ったよりやりますね。
4.BERTに文章を生成させる
事前学習しかしていないBERTは穴埋め問題と2つの文の繋がりしか学習していないので、そのままでは文章生成には向かないです。しかし原理上やれないことはないです。
あるテキストを用意して、先頭の単語に[MASK]を掛け予測をしたら、先頭の単語を予測結果に置き換え、次の単語に[MASK]を掛け予測する、ということを繰り返すとテキストに似た新たな文が生成ができるはずです。
では、やってみましょう。題材は、「ケネディ大統領がアポロ計画の支援を表明した演説(和訳)」です。

まず、テキストをIDテンソルに変換します。
|
1 2 3 4 5 6 7 |
# テキストをIDテンソルに変換 text = "我々が10年以内に月に行こうなどと決めたのは、それが容易だからではありません。むしろ困難だからです。この目標が、我々のもつ行動力や技術の最善といえるものを集結しそれがどれほどのものかを知るのに役立つこととなるからです。その挑戦こそ、我々が受けて立つことを望み、先延ばしすることを望まないものだからです。そして、これこそが、我々が勝ち取ろうと志すものであり、我々以外にとってもそうだからです。" result = jumanpp.analysis(text) # 分かち書き tokenized_text = [mrph.midasi for mrph in result.mrph_list()] # 単語リストに変換 tokenized_text, mask_index = preparation(tokenized_text) # [CLS],[SEP]の追加 tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text) # IDリストに変換 tokens_tensor = torch.tensor([tokens]) # IDテンソルに変換 |
先程同様、テキストを分かち書きして単語リストにし、定義した関数を使って[CLS],[SEP]を追加したら、IDリストに変換し、Pytorchが読めるIDテンソルに変換します。
今度は、何度も単語を1つだけ予測するので、1単語予測関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 1単語予測関数 def predict_one(tokens_tensor, mask_index): model.eval() tokens_tensor = tokens_tensor.to('cuda') model.to('cuda') with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0] _, predicted_indexes = torch.topk(predictions[0, mask_index], k=5) predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist()) return predicted_tokens, predicted_indexes.tolist() |
これは、[MASK]を掛けた単語を予測し、予測した単語とIDを返す関数です。
そして、文生成をするコードを書きます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 文生成 for i in range(1,len(tokens_tensor[0])): tmp = torch.tensor(tokens_tensor) # tokens_tensorをtmpにコピー tmp[0, i]=4 # i番目を[mask]に書き換え predicted_tokens, predicted_indexes =predict_one(tmp, i) # [mask]を予測 if predicted_indexes !=1: # 予測が[UNK]でなければ tokens_tensor[0, i] = predicted_indexes[0] # 予測IDの[0]番目でtokens_tensorのi番目を上書きする target_list = tokens_tensor.tolist()[0] predict_list = bert_tokenizer.convert_ids_to_tokens(target_list) predict_sentence = ''.join(predict_list[1:]) print('------ original_text -------') print(textwrap.fill(text,45)) print('------ predict_text -------') print(textwrap.fill(predict_sentence,45)) |
tokens_tensorを一端tmpにコピーして、tmpに順次[MASK]を掛け予測した結果で、tokens_tensorの該当箇所を上書きする、ということを繰り返します。さて、このコードを実行すると、

オリジナルが「10年以内に月に行こう」と言っているのに、文生成は「1年以内に海外に行くべきだ」と、やたらこじんまりしてしまいました(笑)。文の中身は、ちょっと意味不明な感じです。事前学習だけだと、文生成はあまり上手く行かないようです。
では、また。
(参考)
・BERT日本語モデルを使って、クリスマスプレゼントに欲しいものを推測してみた
・ColabでJUMAN++を使う














コメントを残す