
1.はじめに
今回ご紹介するのは、音楽からドラム、ベース、ボーカルを高精度に分離できる Demucsという技術です。
*この論文は、2022.8に最終改訂されました。
2.Demucsとは?
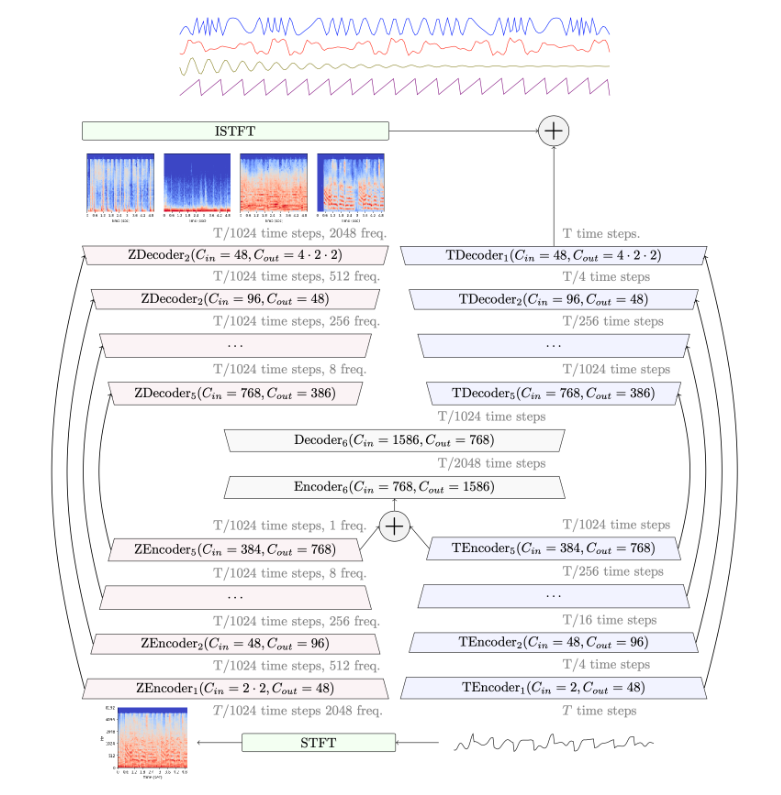
下記がDemucsの概略図です。基本的には、U-Net アーキテクチャを 1 次元の時間領域に適応させて、エンドツーエンドの音源分離を実行するWave-U-Netがベースになっています
これに、ハイブリッド スペクトログラム/波形分離、圧縮残差ブランチ、ローカル アテンション、および特異値正則化を加えたものがDemucsです。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
まず、セットアップを行います。基本的に、! pip install demucs 1発でインストールできます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
#@title #**Setup** # install demucs ! pip install demucs # clone github code ! git clone https://github.com/cedro3/demucs.git %cd demucs # import library import io from pathlib import Path import select from shutil import rmtree import subprocess as sp import sys from typing import Dict, Tuple, Optional, IO from google.colab import files import os import shutil # define function def find_files(in_path): out = [] for file in Path(in_path).iterdir(): if file.suffix.lower().lstrip(".") in extensions: out.append(file) return out def copy_process_streams(process: sp.Popen): def raw(stream: Optional[IO[bytes]]) -> IO[bytes]: assert stream is not None if isinstance(stream, io.BufferedIOBase): stream = stream.raw return stream p_stdout, p_stderr = raw(process.stdout), raw(process.stderr) stream_by_fd: Dict[int, Tuple[IO[bytes], io.StringIO, IO[str]]] = { p_stdout.fileno(): (p_stdout, sys.stdout), p_stderr.fileno(): (p_stderr, sys.stderr), } fds = list(stream_by_fd.keys()) while fds: # `select` syscall will wait until one of the file descriptors has content. ready, _, _ = select.select(fds, [], []) for fd in ready: p_stream, std = stream_by_fd[fd] raw_buf = p_stream.read(2 ** 16) if not raw_buf: fds.remove(fd) continue buf = raw_buf.decode() std.write(buf) std.flush() def separate(inp=None, outp=None): inp = inp or in_path outp = outp or out_path cmd = ["python3", "-m", "demucs.separate", "-o", str(outp), "-n", model] if mp3: cmd += ["--mp3", f"--mp3-bitrate={mp3_rate}"] if float32: cmd += ["--float32"] if int24: cmd += ["--int24"] if two_stems is not None: cmd += [f"--two-stems={two_stems}"] files = [str(f) for f in find_files(inp)] if not files: print(f"No valid audio files in {in_path}") return print("Going to separate the files:") print('\n'.join(files)) print("With command: ", " ".join(cmd)) p = sp.Popen(cmd + files, stdout=sp.PIPE, stderr=sp.PIPE) copy_process_streams(p) p.wait() if p.returncode != 0: print("Command failed, something went wrong.") def reset_folder(path): if os.path.isdir(path): shutil.rmtree(path) os.makedirs(path,exist_ok=True) # make directory ! mkdir target ! mkdir separated |
それでは、音楽から音楽ソースを分離しましょう。music フォルダにあるファイルの中から1つ選んで input に記入して実行します。このとき、karaoke チェックボックスにチェックを入れていないと drums, bass, other, vocal に分離され、チェックを入れていると vocal, no_vocal に分離されます。
自分の用意したファイルを使う場合は、music フォルダにアップロードして下さい。ここでは、サンプル曲を使用するために input に sazanami.mp4 と記入して実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#@title #**Separate music** #@markdown **please upload mp3 to music folder** # setting input = 'sazanami.mp3' #@param {type:"string"} reset_folder('target') reset_folder('separated') shutil.copy('./music/'+input, './target/'+input) karaoke = False #@param {type:"boolean"} # Customize the following options! model = "mdx_extra" extensions = ["mp3", "wav", "ogg", "flac"] # we will look for all those file types. if karaoke: two_stems = "vocals" else: two_stems = None # only separate one stems from the rest, for instance # Options for the output audio. mp3 = True mp3_rate = 320 float32 = False # output as float 32 wavs, unsused if 'mp3' is True. int24 = False # output as int24 wavs, unused if 'mp3' is True. # You cannot set both `float32 = True` and `int24 = True` !! in_path = './target/' out_path = './separated/' separate() |
では、分離した音楽ソースを聴いてみましょう。part で聴きたいパートを選択して実行します。先程、karaoke チェックボックスにチェックを入れていない場合は drums, bass, other, vocal が選択可能で、チェックを入れている場合は vocal, no_vocal が選択可能です。
先程は karaoke チェックボックスにチェックを入れませんでしたので、ここでは bass を選択して実行します。
|
1 2 3 4 5 6 7 8 9 |
#@title #**Play separated music** from IPython.display import Audio #@markdown -If karaoka, you can select vocals or no_vocals\ #@markdown -If not karaoke, you can select bass, drums, other, vocals part ="bass"#@param ["bass", "drums", "other", "vocals", "no_vocals"] file_path = './separated/mdx_extra/'+os.path.splitext(input)[0]+'/'+part+'.mp3' Audio(file_path) |
分離した結果をダウンロードする場合は、次を実行して下さい(Google Chrome専用)
|
1 2 3 4 5 6 7 8 |
#@title #**Download separated music** from google.colab import files if os.path.isfile('separated.zip'): os.remove('separated.zip') ! zip -r separated.zip separated/mdx_extra files.download('separated.zip') |
分離精度はかなり実用的なレベルになって来たように思います。カラオケは簡単に出来ますし、ドラムやベースをやっている方は教師音源が簡単に入手出来ますね。
では、また。
(オリジナルgithub)https://github.com/facebookresearch/demucs
(twitter投稿)














コメントを残す