
1.はじめに
以前からこのブログでは、音声から顔画像を動かす技術(Live Speech Portraits、MakeitTalk)をご紹介して来ましたが、それらはいずれも出力が2次元でした。今回ご紹介するのは、音声から顔の3Dアニメーションを作成するFaceTalkという技術です。
2.FaceTalkとは?
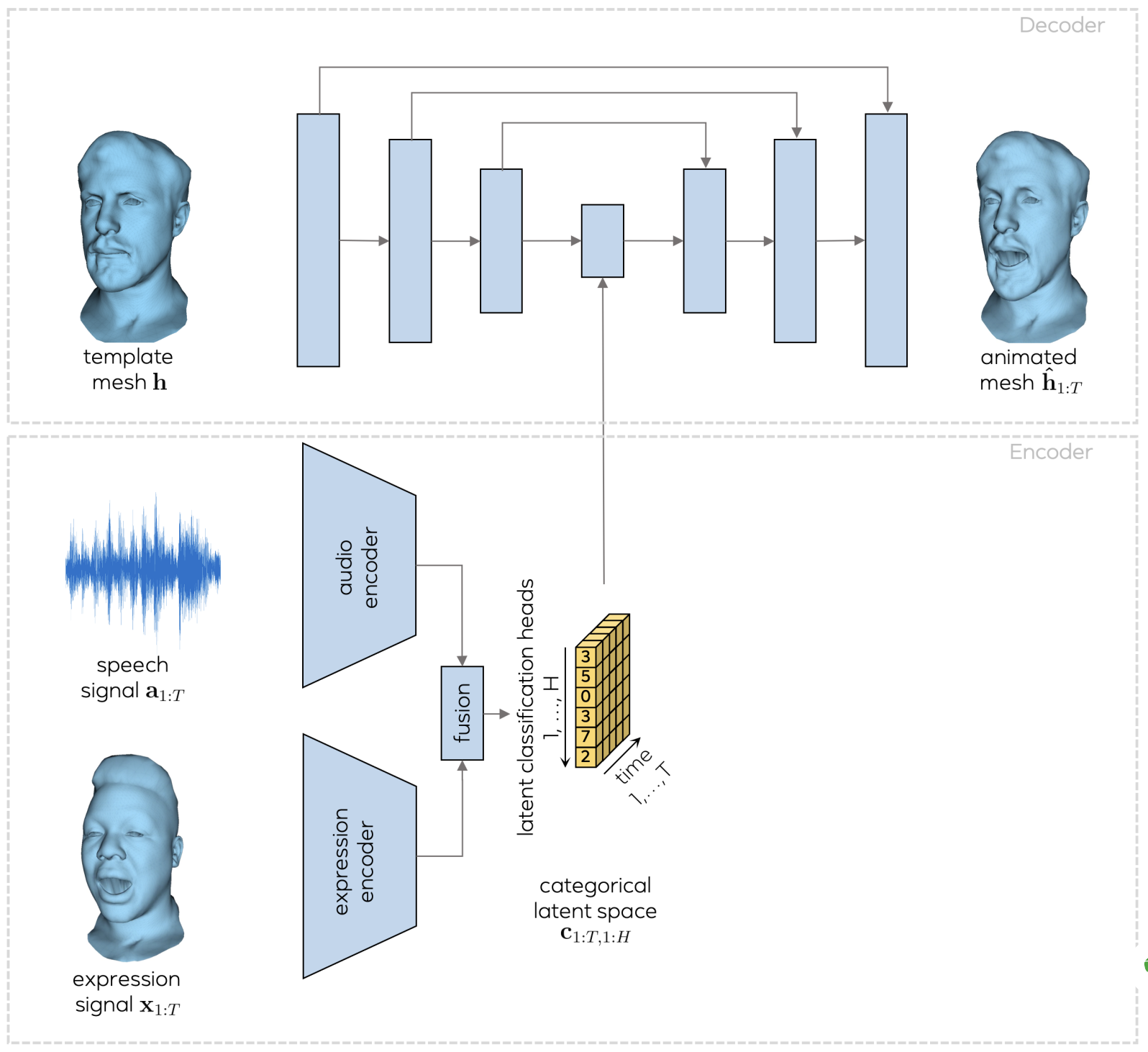
下記がシステムの概要です。まず、顔の3Dメッシュ・テンプレート(template mesh)をエンコードして特徴量に変換し、それをデコードしてアニメーションした顔の3Dメッシュ(animated mesh) に復元するU -Netを用意します。
そして、音声(Speech signal)と顔の3Dキャプチャ信号(expression signal)をそれぞれエンコードしたものを融合し、カテゴリの潜在的な表現空間(Categorical latent space)にマッピングして、U -Netの特徴量に作用させます。
それでは、早速コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。pytorch3dのインストールはpipでは上手く行かず、Building wheelsで行う必要がありセットアップに20分位かかりますので、しばらくお待ちください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#@title セットアップ(20分位かかります) # githubからコードを取得 ! git clone https://github.com/cedro3/meshtalk.git %cd meshtalk # pytorch3dインストール !pip install 'git+https://github.com/facebookresearch/pytorch3d.git@stable' # ffmpeg-pythonインストール ! pip install ffmpeg-python # 学習済みパラメータのダウンロード import urllib.request ! wget https://github.com/facebookresearch/meshtalk/releases/download/pretrained_models_v1.0/pretrained_models.zip ! unzip pretrained_models.zip # movieフォルダ作成 import os os.makedirs('movie', exist_ok=True) |
animete_face.py で音声からFaceMash動画を作成します。audioに、audioフォルダにある音声ファイル(wav)のどれを使用するか記入します。自分の用意した音声を使用する場合は事前にaudioフォルダにアップロードしておいて下さい。
|
1 2 3 4 5 6 7 |
#@title 音声から動画を作成 audio = 'mix.wav'#@param {type:"string"} audio_path = 'audio/'+audio ! python animate_face.py --model_dir pretrained_models\ --audio_file $audio_path\ --output output.mp4 |
作成した動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 |
#@title 動画の再生 from IPython.display import HTML from base64 import b64encode mp4 = open('output.mp4', 'rb').read() data_url = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="50%" height="50%" controls> <source src="{data_url}" type="video/mp4"> </video>""") |
作成した動画をダウンロードする場合は、下記を実行します。
|
1 2 3 4 5 6 7 8 9 |
#@title 動画のダウンロード import os import shutil from google.colab import files name = os.path.splitext(audio) file_name = 'movie/'+name[0]+'.mp4' shutil.copy('output.mp4', file_name) files.download(file_name) |
では、また。
(オリジナルgithub)https://github.com/facebookresearch/meshtalk













コメントを残す