
今回のテーマは女性の顔のクラス分類
こんにちはcedroです。
Webを見ていたら、女性は顔のタイプによってどういうメイクが似合うのかが変わるという記事を見つけました。
顔のタイプを分ける軸は2つで、1つは骨の凸凹が目立つ「男顔」か目立たない「女顔」かという軸。
もう1つは、顔の各パーツに特徴がある「濃い」か特徴が少ない「薄い」という軸だそうです。
この2つの軸で、女性の顔のタイプを4つに分け、それぞれのタイプに対してメイクのコツが書いてありました。
例えば、「男顔」×「濃い」場合は、こんなアドバイスが
元々のパーツや骨格がしっかりしているため、ほぼすっぴんのようなナチュラルなメイクでも服に顔が負けてしまうことがありません。一方で、全てのパーツの濃くメイクをしすぎてしまうと、ニューハーフにような雰囲気になってしまうことがあるので注意が必要です。
ほぼすっぴんと言っても、無造作な眉は野暮ったく見せてしまうので、きれいに整えることが大切。農い方は、眉マスカラでやわらかな雰囲気に変えましょう。そして、アイメイクはあまり濃くしすぎず、リップメイクで女性らしい色を加えてあげると良いでしょう。
シンプルな分類でアドバイスも分かりやすく、各タイプの芸能人の例も書いてあったので、これは面白い題材だなと思った次第です。
というわけで、今回は、SONY Neural Network Consoleを使って、メイクに役立つ女性の顔のクラス分類をやってみたいと思います(笑)。
データ収集・加工を行う
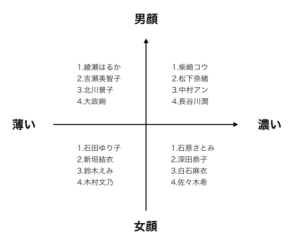
記事に書いてあった芸能人の例を4象限で整理してみるとこうなります。何人か知らない人もいるけど、なんとなくそーかなー、という感じ。
Pythonは全くやったことがないので、今回も力技で画像データの収集・加工(詳細は、指原莉乃をディープラーンイングを参照)を行います。
データ収集個数は、各象限1〜4を各20個づつ計80個×4象限=320個とします。
また例によって、とんでもなく少ないですが、力技ということでご容赦下さい。
画像データの仕様はピクセルサイズ32×32、カラーとします。
データを収集しながら思ったこと
データを収集しながら、私自身も学習することになるわけですが、「男顔×濃い」と「女顔×濃い」はなんとなく差が分かるような気もしますが、全体的に言うと良くわからないというのが素直な感想です。
考えてみると、収集した写真では皆さんメイクをされているわけで、特に「女顔×薄い」の方は、メイクの自由度が高く、色々なタイプに化けられるのでクラス分けが難しいような気がします。
理想を言うと、皆さんのすっぴん顔のデータを一定の照明環境で取得できれば精度が出ると思うのですが、それは無理ですね(笑)。
という風に考えて行くと、今回のミッションは結構ハードルが高そうな気がして来ました。
データセットの作成・読み込み
収集・加工した画像データをフォルダーに整理します。
「男顔×濃い」の画像データはface0に、「男顔×薄い」の画像データはface1に。「女顔×濃い」の画像データはface2に、「女顔×薄い」の画像データはface3に入れます。
C:直下に、SNNC31フォルダーを作り、その中にOutputとSourceというフォルダーを作成します。
そして、Sourceの中にface0、face1、face2、face3の各フォルダーを入れれば準備はOKです。
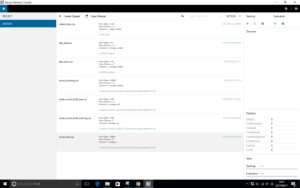
SONY Neural Network Consoleを起動し、左側にある「DATASET」タブをクリックし、中央上部にある「+Create Dataset」をクリックします。
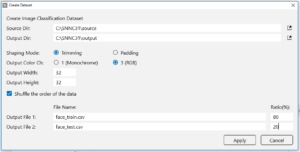
ポップアップした設定表に必要な個所に入力します。
Source Dir:先ほど作成したsourceフォルダーを指定します。
Output Dir:先ほど作成したoutputフォルダーを指定します。
Shaping Mode:デフォルトのままでOK。
Output Color Ch:カラーですので、「3(RGB)}をチェック。
Output width:32、 Output Height:32
Shuffle the order of the data:チェックを入れる
Output File1:学習用ファイル名です。私は、face_train.csvにしました。
Output File2:評価用ファイル名です。私は、face_test.csvにしました。
Ratio:学習用と評価用に何%づつデータを振り分けるかを入力します。私は、学習:評価=80%:20%にしました。
「Apply」ボタンを押します。
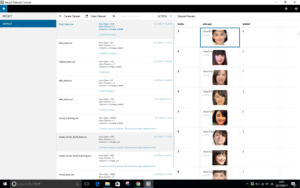
2~3分で、データが読み込まれます。
face_train.csv(学習用ファイル)と face_test.csv(評価用ファイル)が出来ていますので、それぞれクリックしてみて、ちゃんと思った通りの画像が表示されているか確認します。
プロジェクトの作成

左側にある「PROJECT」タブを押し、LeNet.sdcprojをクリックします。
Lenet初期画面-300x188.png)
さて、LeNet.sdcprojですが、Cが2層のCNNです。
今回は、このプロジェクトを流用しますので、「赤丸」をクリックし適当な名前(私は、face_Lenet.sdcprojにしました)を付けて、先程作成したOutputフォルダーにプロジェクトをセーブします。

EDIT画面にします。
今回の設定変更は、Input(先頭の黒色のブロック)のパラメーターを1,28,28 → 3,32,32に変更するだけです。あとは、Inputの後のブロックが自動的に変更されます。
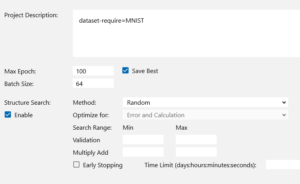
CONFIG画面にします。
Max Epochを100、Batch Sizeを64とし、自動最適化をしたいので、Structure Searchの「Enable」ボタンにチェックを入れます。
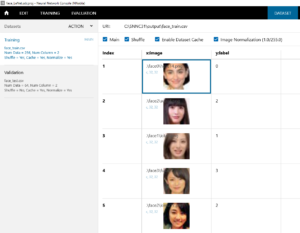
DATASET画面にします。
先程作成した、face_train.csv(学習用ファイル)と face_test.csv(評価用ファイル)を読み込ませます。
一旦、セーブします。
さて、これで学習ボタンを押せば、自動最適化の開始です。
結果はどうなったか?
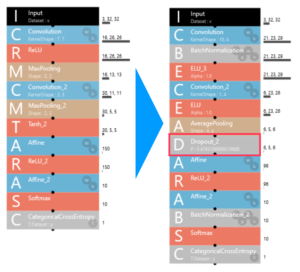
1時間ほど試行錯誤し、評価した結果、最適なニューラルネットワークの構成はこうなりました。
ブロックが12個→14個に増え、D(Dropout)が追加されています。
D(Dropout)はノードのうちいくつかを無効にして学習を行い、次の更新では別のノードを無効にして学習を行うことを繰り返すことで、ネットワークの自由度を強制的に小さくして汎用性能を上げる手法です。
なるほど。個性豊かな芸能人をクラス分けするには、有効そうですね。
そして評価結果はどうなったでしょうか?
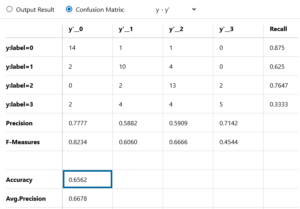
精度は65.62%でした!
おおっ!SONY Neural Network Console、芸能人の高度なメイクの目くらましに負けず、結構がんばったじゃないか。
さて、中身を見てみましょう。
y:label=0(男顔×濃い)の検出精度は87.5%
y:label=1(男顔×薄い)の検出精度は62.5%
y:label=2(女顔×濃い)の検出精度は76.47%
y:label=3(女顔×薄い)の検出精度は33.33%
自分でデータ収集する段階でなんとなく差があるかなと感じた「男顔×濃い」と「女顔×濃い」の検出精度が高いです。
そして、メイクによって一番いろいろなタイプの顔に化けられる可能性を秘めた「女顔×薄い」の検出精度が一番低くなりました。
それにしても、偶然当たる確率は25%ですので、平均で65.62%というのは、かなりのものではないでしょうか。
改めてディープラーニングのポテンシャルの高さを感じる
ディープラーニングに、個人個人の特徴を見つけ出させ識別させるのは、ある意味簡単なように思います。
今回はそうではなくて、個性豊かな複数人をグルーピングして、グループとしての共通した特徴を見つけ出さなければならない。
細かな特徴ではなく、もっと一般的な特徴を見つけなければいけないのは、より高次な問題だと思います。
今回、改めてディープラーニングのポテンシャルの高さを感じました。
では、また。














コメントを残す